
Elnur - stock.adobe.com
Guide pratique pour déployer un modèle de machine learning en production
Le déploiement de modèles de machine learning en production est complexe et comporte de nombreux pièges potentiels. Utilisez cette feuille de route technique comme guide pour naviguer efficacement dans ce processus.

Avec l’IA générative, le machine learning n’a pas disparu. Ces dernières années, il est même devenu un élément central des opérations en entreprise. Il offre de précieux indicateurs et des capacités d’automatisation puissantes. Cependant, passer d’un environnement d’entraînement ou de développement à la production reste un défi pour de nombreuses organisations.
Ce guide pratique est conçu pour fournir les bases aux équipes techniques afin qu’elles déploient avec succès des modèles d’apprentissage automatique en production. Tout d’abord, apprenez à surmonter les obstacles courants, tels que la gestion des versions des modèles, l’incompatibilité des environnements, l’évolutivité et les problèmes d’hébergement. Ensuite, établissez un ensemble d’outils et de bonnes pratiques pour chaque étape du processus de déploiement.
Les défis liés au déploiement du machine learning
Les enjeux qui freinent le passage en production des modèles de machine learning sont légion.
Tout d’abord, la gestion des versions des modèles est essentielle pour la reproductibilité, le débogage et les scénarios de restauration. Dans un environnement de développement, il est courant d’expérimenter différentes architectures de modèles, configurations d’hyperparamètres et méthodes de prétraitement. Sans un contrôle approprié des versions, il peut devenir presque impossible de savoir quelle version du modèle a donné les meilleurs résultats ou laquelle est actuellement déployée.
Deuxièmement, l’inadéquation matérielle entre les environnements de développement et de production est souvent source de problèmes. Un modèle entraîné sur une machine locale avec certaines bibliothèques Python ou configurations matérielles peut se comporter différemment lorsqu’il est déployé sur des serveurs de production ou des plateformes cloud.
Enfin, la mise à l’échelle des modèles ML est à la fois cruciale et difficile, en particulier lorsque la demande des utilisateurs augmente ou que la latence d’inférence devient un problème. Lorsqu’un modèle est déployé en production, il doit gérer différents niveaux de trafic, allant d’une utilisation sporadique à des charges de travail importantes. Par exemple, un système de recommandation consacré aux e-commerces doit traiter des données en temps réel et fournir des prédictions à des millions de consommateurs à toute période de l’année. Et ne pas flancher au moment des soldes ou des fêtes d’années.
La mise à l’échelle des modèles nécessite également l’optimisation des ressources. L’exécution de plusieurs instances d’un modèle peut être coûteuse en matière de besoins en calcul et en stockage.
Les astuces pour un déploiement réussi en production
Gestion des versions des modèles
Pour la gestion des versions des modèles, adoptez des outils tels que MLflow, DVC ou Weights & Biases, spécialement conçus pour gérer le cycle de vie des modèles ML. Ils permettent aux utilisateurs d’enregistrer et de suivre des artefacts tels que des jeux de données, des modèles et des hyperparamètres, ainsi que le code source.
Utilisez ces outils en combinaison avec GitHub ou d’autres services de référentiel de code source, tels qu’Azure DevOps, qui peuvent suivre le code et les configurations des modèles. Utilisez ensuite des pipelines CI/CD tels que GitHub Actions, Argo CD, etc., pour automatiser les tests, la validation et le déploiement de nouvelles versions de modèles.
Cohérence de l’environnement
Une configuration cohérente garantit que les modèles fonctionnent comme prévu, quel que soit l’endroit où ils sont déployés. Les outils suivants peuvent aider à assurer la cohérence de l’environnement :
- Conteneurs Docker. Docker permet aux développeurs de regrouper les modèles, leurs dépendances et leurs environnements d’exécution dans un seul conteneur. De nombreux modèles sont des combinaisons de plusieurs paquets Python et de code R, avec différentes dépendances à des versions spécifiques de Python. Les regrouper dans un conteneur Docker garantit que le même environnement est reproduit dans les environnements de développement, de test et de production.
- Gestion de l’environnement. Utilisez des outils tels que Conda pour gérer les dépendances et verrouiller les versions. Cela permet d’éviter les problèmes causés par des versions de bibliothèques incompatibles entre les environnements.
- Infrastructure as code. Combinez Docker avec l’IaC pour garantir que l’infrastructure et les dépendances des applications sont à la fois contrôlées et reproductibles, ce qui réduit le risque de divergences entre les configurations de développement, de test et de production. Les outils IaC tels que Terraform et Pulumi permettent un provisionnement cohérent entre les environnements.
Mise à l’échelle des modèles en production
La mise à l’échelle des modèles implique souvent la gestion et l’exécution de conteneurs Docker dans un environnement de production. L’une des approches les plus courantes consiste à utiliser Kubernetes.
Kubernetes peut mettre à l’échelle les conteneurs en fonction de métriques spécifiques telles que l’utilisation du processeur (CPU), de la mémoire vive ou du GPU. Cela est crucial pour les charges de travail ML, qui impliquent souvent des tâches gourmandes en calcul, telles que l’inférence de modèles ou le traitement de données par lots.
L’orchestrateur permet également une allocation précise des ressources. Par exemple, un service d’inférence peut ne nécessiter qu’une fraction d’un GPU, tandis qu’une tâche d’entraînement peut consommer plusieurs GPU sur différents nœuds.
Hébergement sur site ou dans le cloud public
Un autre aspect de la mise à l’échelle consiste à déterminer quand choisir l’hébergement sur site ou dans le cloud public pour héberger les modèles de machine learning. Bien que leur exécution sur Kubernetes soit une option, de nombreux fournisseurs de cloud proposent également des services PaaS qui peuvent héberger les différents modèles, simplifier une grande partie de la complexité et gérer automatiquement la mise à l’échelle. Des services tels qu’Azure Machine Learning ou AWS SageMaker le proposent.
Les services PaaS et le framework MLflow permettent tous deux de surveiller en temps réel l’entraînement des modèles, l’inférence et les ressources informatiques sous-jacentes. Ils permettent également de mettre à jour ou de modifier automatiquement les modèles sous-jacents afin de limiter, voire d’éliminer, les temps d’arrêt des services qui dépendent des modèles ML.
L’évolutivité est l’un des principaux avantages de l’utilisation d’un cloud public. Ces services offrent une mise à l’échelle élastique (ajustement automatique des ressources en fonction de la demande), ce qui est idéal pour les charges de travail à trafic variable. A contrario, les infrastructures sur site nécessitent une mise à l’échelle manuelle, par exemple l’ajout de matériel ou la configuration de clusters Kubernetes. Les options sur site permettent de bien gérer les charges de travail prévisibles, mais elles sont moins flexibles et peuvent rencontrer des difficultés de mise à l’échelle lorsque la demande fluctue.
Cependant, veillez à évaluer les limites des services cloud par rapport à l’exécution de modèles sur une infrastructure privée. De plus, de nombreux services PaaS peuvent être assez coûteux par rapport à l’exécution de modèles directement sur Kubernetes ou dans un conteneur autonome.
Les étapes pour déployer un modèle ML depuis un environnement local
Le diagramme ci-dessous illustre un exemple d’environnement dans lequel un data scientist ou un analyste entraîne un modèle à l’aide de données accessibles via une plateforme de données telle que Microsoft Fabric, Databricks ou Snowflake.
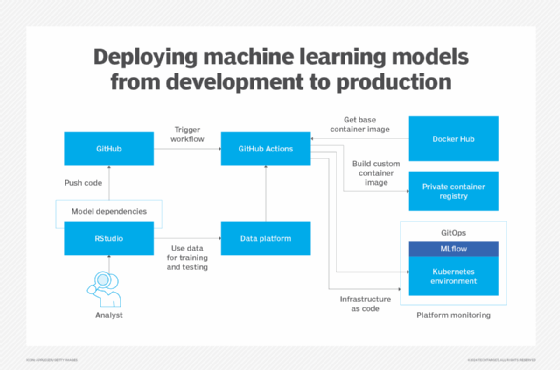
Lorsqu’ils effectuent leur entraînement localement, les développeurs peuvent effectuer des tests à l’aide de modules Python ou de packages R s’exécutant dans des images Docker sur leurs machines. Une fois le modèle terminé, le développeur transfère la configuration Docker et le code de l’application vers GitHub. Cela déclenche un workflow GitHub Action, qui utilise la configuration et les images de conteneur de base provenant de Docker Hub.
Par exemple, une image Python de base provenant de Docker peut être combinée avec la spécification du modèle afin de créer un nouvel ensemble d’images Docker contenant le modèle complet avec ses dépendances. L’image Docker résultante est stockée dans un registre de conteneurs privé, qui sert de référentiel pour les images Docker. Les développeurs peuvent ensuite mettre à jour l’environnement MLflow sur Kubernetes afin de commencer à utiliser le nouveau modèle.
Pour mettre à jour les modèles d’une version à une autre, les équipes peuvent adopter une approche GitOps, dans laquelle le code stocké dans GitHub sert de source de vérité. Dans ce scénario, la configuration Kubernetes est un manifeste qui spécifie à quoi doit ressembler l’environnement. L’approche GitOps garantit que toutes les modifications apportées à la configuration sont validées dans le référentiel, créant ainsi une source unique de vérité pour le déploiement.
Cette méthode permet le contrôle des versions, l’audit et les restaurations, ce qui en fait un choix efficace pour la gestion des environnements MLflow. Le déploiement de nouveaux modèles peut également être intégré dans un workflow GitHub en tant que processus par étapes. Par exemple, les modèles peuvent d’abord être déployés dans un environnement de préproduction afin de valider leur fonctionnalité sur Kubernetes, avant d’être mis en production.
Marius Sandbu est un évangéliste du cloud chez Sopra Steria en Norvège, où il se concentre principalement sur l’IT des utilisateurs finaux et les technologies cloud natives.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
Conteneurisation : les différences clés entre Docker et Podman
-
![]()
Comment les baies de stockage traditionnelles s’adaptent aux conteneurs
Par: Christophe Bardy
-
![]()
Stockage en conteneurs : l'essentiel sur Portworx
Par: Christophe Bardy
-
![]()
Kubernetes sur Azure Container Service : une clé pour le Cloud hybride
Par: Cyrille Chausson



