Agentforce : Salesforce dévoile les entrailles de son moteur de raisonnement Atlas
Sous ses atours marketing et sa prise en main low-code/no-code, Agentforce dissimule un « moteur de raisonnement système 2 » couplé à une architecture graphe et orientée événements. Le tout implique l’un des premiers déploiements d’un système multiagent à large échelle.
Outre l’effort appuyé de marketing, l’appellation 2.0 derrière Agentforce est justifiée par la disponibilité en février prochain de l’architecture sous-jacente qui permettra le déploiement des agents IA à l’échelle. Comme le reste des solutions Salesforce, elle s’appuie sur l’infrastructure cloud Hyperforce, mais la plateforme de conception d’agents IA est propulsée par ce que l’éditeur a résumé à un moteur de raisonnement nommé Atlas.
Ici, l’effort marketing sert un but précis : tenter d’expliquer aux clients ce qu’il se passe sous le capot de sa plateforme d’IA. Et répondre à la question : « est-ce bien fiable ? ».
Atlas, version « simple »
« Certains clients ne veulent jamais entendre parler de notre architecture. Il y a des acheteurs qui disent : “Hyperforce, quoi ? Non, je m’en fiche” », déclare Sanjna Parulekar, vice-présidente marketing produit chez Salesforce, auprès du MagIT. « Mais il y a autant de clients qui s’intéressent vraiment à la résidence des données dans Hyperforce. Avec Atlas, ils s’intéressent à la précision et aux techniques que nous utilisons pour développer la consistance des résultats des LLM », justifie-t-elle.
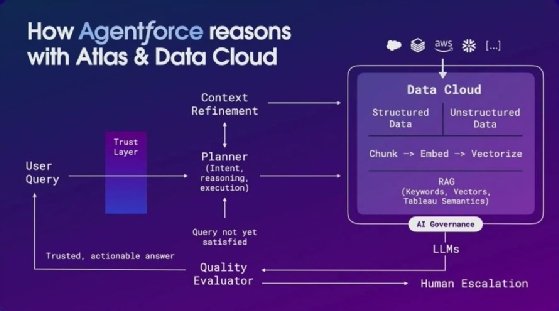
Une vue simplifiée du processus du traitement d'un utilisateur par le moteur de raisonnement Atlas.
En l’occurrence, les entreprises et les chercheurs en IA ont bien compris que la génération augmentée par la recherche (RAG) ne suffit pas toujours à contrôler les résultats d’un LLM. Peut-on alors lui confier des outils, qui plus est pour manipuler des données et des jobs dans des SI critiques ? Salesforce et son équipe de recherche croient que oui, à condition de lui imposer une gouvernance stricte.
Salesforce avait déjà présenté l’Einstein Trust Layer, un ensemble de mécanismes pour réduire les biais et les hallucinations de ses systèmes d’IA générative.
Ainsi, avec Atlas dans Agentforce, une requête d’un utilisateur traverse la couche de confiance Einstein Trust Layer avant d’être soumise à un « planificateur ». Celui-ci est chargé de comprendre l’intention de l’usager, d’établir un plan d’action et de l’exécuter en s’appuyant sur le contexte en provenance d’instances RAG mêlant des mots clés, des documents vectorisés, des données déjà structurées et des métadonnées, par exemple en provenance de la couche sémantique de Tableau (en disponibilité générale depuis le 18 décembre). Des grands modèles de langage sont utilisés pour générer la réponse soumise à un « évaluateur de qualité ». Si la réponse n’est pas suffisamment qualitative, alors l’élément généré est renvoyé au planificateur qui active à nouveau les éléments de la couche RAG. Au besoin, si l’évaluateur rejette les contenus générés, une remontée vers un humain est possible.
« Il y a certaines tâches pour lesquelles vous ne voyez pas d’inconvénient à ce qu’un agent réponde à une question d’un client qui peut facilement être traité en ligne par le biais d’une expérience de type chat », commente Sanjna Parulekar. « Mais il y a d’autres types de questions qui nécessitent vraiment la présence d’un humain dans la boucle ».
Le tout est agrémenté d’une couche d’apprentissage par renforcement pour réentraîner les modèles sous-jacents. Voilà la version « simple ».
Agentforce : Sous le capot, un système multiagent
Atlas dissimule un DAG : un graphe orienté acyclique qui guide les actions des LLMs
En réalité, Atlas est un système d’IA composite, comme Genie et DatabricksIQ chez Databricks. De fait, Ali Ghodsi et Matei Zaharia, cofondateurs de Databricks ainsi que Naveen Rao, cofondateur de MosaicML, vice-président de l’IA chez Databricks, ont contribué à un article intitulé « La transition de modèles vers des systèmes d’IA composites » (en VO : « The Shift from Models to Compound AI Systems ») publié en février 2024 sur le blog de l’institut de recherche en IA de l’université de Berkeley.
L’idée est simple : les meilleurs résultats en IA générative sont obtenus en s’appuyant sur des systèmes multipliant des composants, et « pas seulement sur des modèles [d’IA] monolithiques ». Salesforce Research a embrassé cette tendance.
« [Atlas] est une architecture graphe de flux de travail orienté événement conçu pour l’inférence en temps réel, intégrant un moteur de raisonnement de type système deux », explique Phil Mui, vice-président de la technologie et responsable des produits et de l’architecture de la recherche en IA chez Salesforce, lors d’un point presse.
Ce concept fait référence à l’ouvrage « Système 1, système 2 : les deux vitesses de la pensée » du psychologue Daniel Kahneman. Avec son confrère Amos Tversky, il a théorisé la séparation entre deux systèmes de pensées : le système 1, rapide, instinctif et émotionnel, du système 2, plus lent, mais réfléchi et logique. En clair, au centre de ce système 2 se tient un LLM du même type que 01 d’OpenAI. Mais il n’est pas seul.
« Chaque agent du moteur de raisonnement Atlas, coordonné avec un orchestrateur-concierge, raisonne en autonomie sur des tâches spécifiques, le tout surveillé par des flux de travail pilotés par des événements ».
Phil MuiV-P technologie et responsable produits et architecture de la recherche en IA, Salesforce
« Chaque agent du moteur de raisonnement Atlas, coordonné avec un orchestrateur-concierge, raisonne en autonomie sur des tâches spécifiques, le tout surveillé par des flux de travail pilotés par des événements », détaille Phil Mui dans un billet de blog.
Un agent a besoin d’état – de données accessibles par les LLM à travers l’architecture RAG – et de flux, d’un cadre programmatique pour guider ses actions. Un agent provoque des « effets secondaires » : essentiellement, il crée, modifie ou supprime des données dans les produits Salesforce et – bientôt des systèmes tiers.
Si l’interface utilisateur les masque, des fichiers déclaratifs YAML permettent de définir le rôle, les données, les actions, les garde-fous et les canaux attribués à un agent.
D’autres acteurs présenteraient Atlas comme un système multiagent. En clair, plusieurs LLMs à qui l’on a confié un rôle spécifique agissent de concert, mais de manière autonome. L’architecture pub/sub doit permettre une communication asynchrone entre les agents et de les découpler. Outre le fait que ce couplage « léger » permet de paralléliser les traitements, les flux de travail événementiels incluent des règles et des déclencheurs qui orientent leurs activités. En principe, les flux de travail peuvent aussi déclencher l’appel à des outils et à d’autres modèles de machine learning ou de deep learning pour compléter un traitement.
Les éléments de la couche de confiance, les techniques avancées de RAG, les filtres doivent assurer le contrôle des résultats. Salesforce supervise le tout à travers (entre autres) des logs d’audit. D’autres entreprises, dont Pegasystems, un concurrent de Salesforce, s’est montré sceptique à l’idée de confier autant d’importance à des LLM connus pour halluciner. Salesforce répond qu’elle a mis en place les garde-fous et la sécurité nécessaire, et que son système serait 33 % plus efficace que les solutions concurrentes, selon les pilotes menés avec les clients.
Qui doit être le chef d’orchestre ? Un LLM ou un moteur de règles ?
Une autre technique, en apparence moins risquée, implique l’orchestration de flux de travail à travers un moteur de règles qui permet le déclenchement d’un agent ou d’un LLM. « Certains clients veulent conserver un framework basé sur des règles avec des déclarations conditionnelles “If-Then” et ne déléguer que certains types de charge de travail aux agents. Et c’est tout à fait acceptable, évidemment », répond Sanjna Parulekar. « Ce sont des décisions de conception qu’une entreprise peut prendre et nous leur laissons le choix », avance-t-elle. « Maintenant, un nombre équivalent d’entreprises ne veulent pas du tout fonctionner ainsi. Elles préfèrent un système entièrement basé sur des LLM ».
« Certains clients veulent conserver un framework basé sur des règles avec des déclarations conditionnelles “If-Then” et ne déléguer que certains types de charge de travail aux agents. Et c’est tout à fait acceptable, évidemment ».
Sanjna Parulekar V-P, marketing produit, Salesforce
De fait, Salesforce n’est pas le seul à vouloir concevoir un système multiagent pour ses clients. S’il ne semble pas en avoir fait un produit aussi élaboré, Microsoft a développé deux frameworks en ce sens : Autogen et Semantic Kernel. Il les propose dans sa suite Azure AI Foundry. Lors de son événement re:Invent 2024, AWS a présenté un système multiagent encadré par une IA neurosymbolique : un moteur de règles. Le spécialiste du BPM Appian l’a testé et y voit une solution prometteuse.
De son côté, le Français ILLUIN Technology se propose d’orchestrer les flux de données transformées par les LLM à travers une technologie de type ELT/ETL en sus des autres outils des systèmes composites.
Le géant du CRM sera toutefois l’un des premiers sinon le premier à déployer un système multiagent à l’échelle. Même avant les fournisseurs de LLM.
Les lois de mise à l’échelle doivent maintenant régir l’inférence
Selon Phil Mui, il y aurait maintenant deux types de « scaling laws ».
Les « scaling laws » sont des lois empiriques théorisées par les chercheurs en IA pour tenter de déterminer quelle est la quantité idéale et/ou maximale de données pour entraîner un grand modèle de langage performant.
« Le fait que Sam Altman [cofondateur et PDG d’OpenAI, N.D.L.R.] lui-même y a fait brièvement référence, en évoquant le fait que les gains d’échelle se situent désormais au niveau de l’inférence au moment de la sortie du modèle 01, est un marqueur important de cette tendance », illustre Phil Mui.
Dans ce contexte, l’objectif devient donc d’exploiter des modèles de langage, devenu des commodités.
Bien que certains modèles soient légèrement supérieurs aux autres, ils se tiennent dans un mouchoir de poche, qu’ils soient open weight ou propriétaires. LeMagIT évite de trop s’épancher sur ses résultats tant les différences sont infimes et tant ces parangonnages sont abscons pour une entreprise. Salesforce l’a bien compris : il a mis en place une batterie de tests pour vérifier les performances des LLM sur les tâches de son CRM.
Cependant, pour multiplier les performances par 10, il est crucial de déployer des systèmes d’inférence complexes qui combinent plusieurs modèles d’IA capables de « raisonner », selon Phil Mui. « C’est précisément ce que vise le moteur de raisonnement Atlas de Salesforce : maximiser l’utilisation de ces modèles pour repousser les limites de précision et d’efficacité ».
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM