Getty Images/iStockphoto
Sauvegardes : tout ce qu’il faut savoir sur la déduplication
La déduplication des sauvegardes permet de réduire la consommation d’espace de stockage actif, de diminuer la durée des tâches de sauvegarde et d’augmenter l’efficacité globale d’une infrastructure de stockage.

Les administrateurs de sauvegarde ont la responsabilité de protéger les données critiques de l’entreprise, mais aussi celle de gérer des coûts de stockage et de réseau. La redondance est un élément majeur de la sauvegarde des données, mais une redondance excessive peut augmenter les coûts de stockage et compliquer la gestion des données. C’est là qu’intervient la déduplication des sauvegardes.
La déduplication fonctionne en générant un hachage des données analysées. Les résultats du hachage sont ensuite comparés à d’autres résultats afin de déterminer les doublons. Toutes les copies des informations dupliquées, sauf une, sont supprimées et remplacées par des pointeurs vers la source de données unique et définitive.
Avec la déduplication des sauvegardes, les données dupliquées dans les sauvegardes sont remplacées par des pointeurs vers le fichier source. Il en résulte un gain d’espace assez surprenant. L’espace gagné varie en fonction de la technique de déduplication et des données d’origine. L’espace économisé dépend également fortement du type d’informations générées par les utilisateurs.
Cet article examine la déduplication des données et la manière dont elle permet aux administrateurs de sauvegarde d’exceller dans leurs fonctions. Il aborde différents types de déduplication, leurs avantages, leurs inconvénients et des techniques spécifiques pour vous aider à déterminer comment la déduplication s’intègre dans votre structure de sauvegarde des données.
Les types de déduplication des données
Plusieurs options de déduplication sont disponibles, permettant aux administrateurs de sauvegarde de choisir leur propre aventure en ce qui concerne la manière dont le processus est effectué. Lorsqu’ils décident d’une stratégie de déduplication des sauvegardes, les administrateurs peuvent déterminer comment les données dupliquées sont analysées, quand elles sont éliminées et à quel moment du processus de sauvegarde la déduplication a lieu.
Déduplication au niveau des fichiers ou au niveau des blocs. Les techniques de déduplication comprennent deux niveaux d’analyse des informations, chacun offrant ses propres avantages : au niveau des fichiers et au niveau des blocs.
La déduplication au niveau des fichiers évalue des fichiers complets pour rechercher des informations présentes deux fois. La déduplication au niveau des blocs divise les données en blocs, puis vérifie chaque bloc pour rechercher des informations en double par rapport aux autres blocs. Dans les deux cas, des pointeurs vers une source unique et définitive remplacent ces informations.
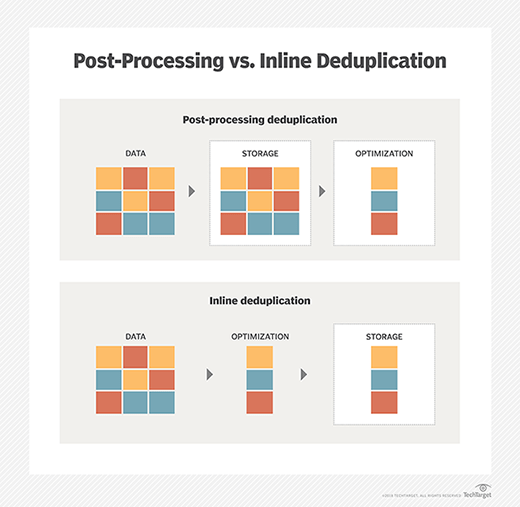
Déduplication en temps réel ou en post-traitement. La déduplication peut s’effectuer au fil de l’eau, en temps réel, ou après l’enregistrement du fichier par l’utilisateur. La déduplication après l’enregistrement du fichier par l’utilisateur est appelée post-traitement.
La déduplication en temps réel peut nécessiter davantage de ressources que la déduplication post-traitement, ce qui ralentit le processus de sauvegarde. Cependant, la déduplication post-traitement nécessite l’utilisation d’un espace de stockage temporaire, contrairement à la déduplication en temps réel. Tenez compte des besoins de votre entreprise en matière de stockage et de traitement afin de déterminer le moment le plus opportun pour effectuer la déduplication.
Déduplication basée sur la source ou sur la cible. Les administrateurs de stockage et de sauvegarde peuvent également décider du moment où la déduplication doit avoir lieu par rapport au processus de sauvegarde. Les options sont la déduplication basée sur la source ou sur la cible.
La déduplication basée sur la source traite les informations avant le début de la procédure de sauvegarde, ce qui réduit les besoins en bande passante et en stockage. Elle présente également l’avantage de réduire les besoins généraux en stockage pour les données.
La déduplication basée sur la cible traite les informations au niveau de la cible de sauvegarde. Il s’agit d’une approche plus spécialisée et plus gourmande en ressources, qui convient aux ensembles de données volumineux.
Les avantages de la déduplication pour les sauvegardes
De nombreux administrateurs de stockage utilisent déjà la déduplication des données, de sorte que les administrateurs de sauvegarde peuvent bénéficier de cette technologie sans s’en rendre compte. Cependant, les avantages spécifiques de la déduplication des données pour les administrateurs de sauvegarde sont les suivants :
- Efficacité des tâches de sauvegarde.
- Optimisation de l’espace de stockage.
- Optimisation de la bande passante réseau.
- Efficacité accrue de la gestion des données.
La réduction des coûts qui en résulte permet aux entreprises de consacrer des ressources financières cruciales à d’autres domaines. La déduplication peut également aider les administrateurs de sauvegarde à justifier la conservation des données plus longtemps tout en réduisant l’empreinte de stockage sur les supports physiques.
Les inconvénients de la déduplication des données
Aucune technologie n’est parfaite, et la déduplication des données ne fait pas exception. Vous devez anticiper certains problèmes spécifiques si vous implémentez la déduplication dans votre environnement. Les inconvénients potentiels sont les suivants :
- Ralentissement des performances du système, en particulier au niveau du processeur. La déduplication est très gourmande en ressources processeur.
- Risques de perte de données dus à des collisions de hachage ou à d’autres erreurs.
- Fragmentation accrue du stockage résultant de la manière dont les blocs sont traités et écrits sur le disque à des moments légèrement différents, et sont répartis sur plusieurs périphériques de stockage.
- Risques de dépendance des blocs associés à la corruption des données. Si un bloc source est corrompu, cela peut avoir des répercussions importantes sur de nombreux fichiers.
- Niveaux d’efficacité variables en fonction du type et de la structure des données.
Le ralentissement des performances du système est particulièrement préoccupant. Si la récupération rapide des données est essentielle, la déduplication n’est peut-être pas le meilleur choix.
Les cas d’usage de la déduplication
Les cas d’usage de la déduplication couvrent presque tous les types de fichiers. Cependant, chaque type de fichier bénéficie différemment de la déduplication. Prenons l’exemple d’un stockage de fichiers susceptible de contenir des informations identiques. Les fichiers sources d’installation, les images de machines virtuelles ou encore d’autres situations où il existe de nombreuses copies des mêmes fichiers en sont un excellent exemple. Les types de fichiers et de données suivants bénéficient considérablement de la déduplication des données.
Fichiers de sauvegarde. Les tâches de sauvegarde fréquentes ne contiennent souvent que des modifications mineures avec beaucoup d’informations dupliquées.
Fichiers de machines virtuelles. Les images disque de machines virtuelles, les images ISO et autres fichiers de support contiennent des informations identiques sur les fichiers système.
Pièces jointes aux e-mails. De nombreuses entreprises envoient des pièces jointes à des groupes d’e-mails entiers, dupliquant ainsi la même pièce jointe des centaines de fois.
Fichiers binaires de logiciels. Les programmes d’installation, les fichiers CAB et autres fichiers sources de logiciels peuvent être dupliqués dans toute une entreprise.
Documents utilisateur. Les fichiers de la suite Office, les PDF, les images et autres fichiers de données des utilisateurs sont fréquemment dupliqués dans les répertoires personnels, les dossiers des services et divers espaces de stockage collaboratifs.
Référentiels de code. Les développeurs peuvent stocker des versions de code qui se répètent, car ils utilisent les commits Git pour gérer les versions.
Les outils de déduplication sous Windows et Linux
Les outils de déduplication intégrés varient en fonction du système d’exploitation utilisé par l’entreprise.
Windows Server inclut un utilitaire de déduplication intégré pour NTFS. Il offre plusieurs options de configuration utiles à l’aide de PowerShell et d’outils graphiques :
- Planification. Planifiez les actions de déduplication pendant les heures creuses à l’aide de PowerShell ou du Planificateur de tâches afin de minimiser l’impact sur les performances du serveur pendant les heures de pointe.
- Exclusions. Excluez certains types de fichiers ou emplacements de stockage du processus de déduplication afin d’éviter tout risque pour les fichiers critiques.
- Seuils d’ancienneté. Définissez des seuils d’ancienneté pour les fichiers candidats à la déduplication. La valeur par défaut est trois jours.
- Rapports et surveillance. Activez la surveillance de l’état des actions de déduplication à l’aide de cmdlets PowerShell tels que Get-DedupStatus et Get-DedupJob.
Les utilisateurs Linux disposent des options suivantes pour la déduplication :
- Btrfs. Ce système de fichiers permet la déduplication hors ligne, basée sur des blocs, à l’aide d’utilitaires tels que duperemove et bedup.
- Czkawka. Cet outil identifie les informations en double et autres données inutiles afin de récupérer de l’espace de stockage.
- Rdfind. Cet outil identifie les informations en double en fonction du contenu des fichiers, ce qui vous permet de gérer les fichiers en double à l’aide d’autres outils. Il peut supprimer les doublons ou remplacer les informations redondantes.