Load balancing (répartition de charge)
La répartition de charge, ou en anglais load balancing, est une technique utilisée pour répartir uniformément les charges de travail sur plusieurs serveurs ou autres ressources informatiques, afin d'optimiser le rendement, la fiabilité et la capacité du réseau.
Le load balancer est réalisé par un équipement dédié, une appliance physique ou virtuelle. Cette appliance identifie en temps réel quel serveur au sein d'un pool répond le mieux à une demande donnée du client, tout en veillant à ce qu'un trafic réseau intense ne surcharge pas trop un seul et même serveur.
En plus de maximiser les capacités et les performances du réseau, la répartition de charge apporte une fonctionnalité de basculement (failover). Si un serveur dysfonctionne, un load balancer redirige immédiatement ses charges de travail vers un serveur de secours, atténuant ainsi les conséquences de la panne sur les utilisateurs.
On distingue généralement deux types de répartition de charge, selon qu'il prend en charge la couche 4 ou la couche 7. Les répartiteurs de charge de la couche 4 répartissent le trafic en fonction des données de transport, telles que les adresses IP et les numéros de port TCP (Transmission Control Protocol).
Les dispositifs de load balancing de la couche 7 prennent des décisions d'acheminement en s'appuyant sur certaines caractéristiques des applications qui comprennent les informations d'en-tête HTTP et le contenu réel du message, URL et cookies, par exemple. Les répartiteurs de charge de la couche 7 sont plus répandus, mais ceux de la couche 4 restent toutefois prisés, particulièrement dans les déploiements périphériques.
Fonctionnement du load balancing
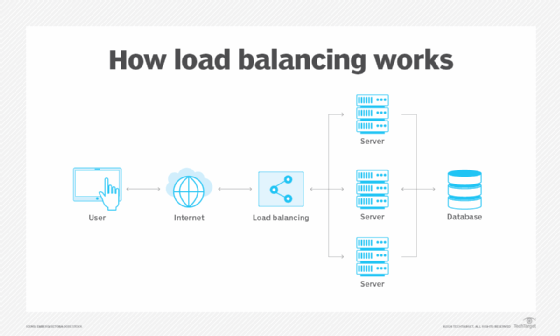
Les répartiteurs de charge traitent des demandes provenant d'utilisateurs qui sollicitent des informations ou d'autres services. Ils sont installés entre les serveurs qui gèrent ces demandes et Internet. Une fois la demande reçue, le répartiteur de charge détermine d'abord quel serveur d'un pool est disponible et en ligne, puis achemine la demande vers ce serveur. Sur les périodes de forte charge réseau, un load balancer peut ajouter dynamiquement des serveurs pour répondre aux pics de trafic. A l'inverse, il peut libérer des serveurs si la demande est trop faible.
Un load balancer peut consister en une appliance physique, une instance logicielle ou une combinaison des deux. Habituellement, les fournisseurs chargent un logiciel propriétaire sur un matériel dédié et vendent le tout aux utilisateurs en tant d'appliances autonomes, généralement par paires afin d'offrir un basculement en cas de défaillance d'un des équipements. Le développement des réseaux rend nécessaire l'achat d'appliances supplémentaires et/ou de plus grande envergure.
A l'inverse, un logiciel de répartition de charge s'exécutera sur des machines virtuelles (VM, Virtual Machine) ou sur des serveurs en marque blanche, le plus souvent sous la forme d'une fonctionnalité d'un contrôleur de mise à disposition d'applications (ACD, Application Delivery Controller). Les ADC proposent généralement des fonctions supplémentaires, comme la mise en cache, la compression ou encore la régulation de trafic (traffic shaping). Répandu dans les environnements cloud, le load balancing virtuel apporte une grande flexibilité ; par exemple, il permet à l'utilisateur de faire évoluer automatiquement sa solution, à la hausse comme à la baisse, pour l'adapter aux pics de trafic ou à une diminution de l'activité du réseau.
Procédés de répartition de charge
Les algorithmes de load balancing déterminent quels serveurs reçoivent des demandes entrantes spécifiques des clients. Les procédés standard sont les suivants :
- L'approche par hachage détermine le serveur à privilégier pour un client donné en fonction de clés désignées, telles qu'en-têtes HTTP ou informations d'adressage IP. Ce procédé prend en charge la persistance de session, ou stickiness, qui profite aux applications reposant sur les informations d'état stockées des utilisateurs, telles que les paniers d'achat sur les sites de commerce électronique.
- La méthode basée sur le moins de connexions favorise les serveurs qui affichent le moins de transactions entrantes, c'est-à-dire les « moins occupés ».
- L'algorithme du temps de réponse le plus court tient compte à la fois des temps de réponse et des connexions actives du serveur ; il envoie les nouvelles demandes aux serveurs les plus rapides affichant le moins de demandes en cours.
- La méthode tournante, dite « round robin », qui a longtemps constitué le procédé de load balancing par défaut, se contente de consulter cycliquement une liste de serveurs disponibles dans un ordre séquentiel.
Les formules peuvent varier considérablement en sophistication et en complexité. Les algorithmes de répartition de charge pondérés, par exemple, hiérarchisent les serveurs, les serveurs haute capacité recevant davantage de trafic que ceux auxquels sont affectés des poids inférieurs.







