Qu'est-ce que l'apprentissage automatique des opérations (MLOps) ?
Les opérations d'apprentissage automatique (MLOps) sont le développement et l'utilisation de modèles d'apprentissage automatique par les équipes d'opérations de développement (DevOps). MLOps ajoute de la discipline au développement et au déploiement des modèles ML, rendant le processus de développement plus fiable et plus productif.
MLOps englobe un ensemble de processus, plutôt qu'un cadre unique, que les développeurs d'apprentissage automatique utilisent pour construire, déployer et surveiller et former en continu leurs modèles. Il est au cœur de l'ingénierie de l'apprentissage automatique, mélangeant l'intelligence artificielle (IA) et les techniques d'apprentissage automatique avec les pratiques DevOps et d'ingénierie des données.
De nombreuses étapes sont nécessaires avant qu'un modèle de ML soit prêt pour la production, et plusieurs acteurs sont impliqués. La philosophie de développement MLOps est pertinente pour les professionnels de l'informatique qui développent des modèles de ML, déploient les modèles et gèrent l'infrastructure qui les prend en charge. La production d'itérations de modèles de ML nécessite la collaboration et les compétences de plusieurs groupes informatiques, tels que les équipes de science des données, les ingénieurs logiciels et les ingénieurs ML.
Le développement de l'apprentissage profond et d'autres modèles de ML est considéré comme expérimental, et les échecs font partie du processus dans les cas d'utilisation du monde réel. La discipline évolue et il est entendu que, parfois, même un modèle de ML réussi peut ne pas fonctionner de la même manière d'un jour à l'autre.
Comment fonctionne le MLOps
MLOps met en œuvre le cycle de vie de l'apprentissage automatique. Il s'agit des étapes qu'un modèle d'apprentissage automatique doit franchir pour être prêt pour la production. Voici les quatre cycles qui composent le cycle de vie de l'apprentissage automatique :
- Le cycle des données. Le cycle des données implique la collecte et la préparation des données pour la formation. Tout d'abord, les données brutes sont extraites de sources appropriées, puis des techniques telles que l'ingénierie des caractéristiques sont utilisées pour transformer, manipuler et organiser les données brutes en données étiquetées prêtes pour l'apprentissage du modèle.
- Cycle du modèle. C'est au cours de ce cycle que le modèle est formé à l'aide de ces données. Une fois le modèle formé, il est important d'en suivre les versions futures tout au long du cycle de vie. Certains outils, tels que l'outil open source MLflow, peuvent être utilisés pour simplifier cette tâche.
- Cycle de développement. Le modèle y est développé, testé et validé afin de pouvoir être déployé dans un environnement de production. Le déploiement peut être automatisé à l'aide de pipelines et de configurations d'intégration continue/de livraison continue (CI/CD) qui réduisent le nombre de tâches manuelles.
- Cycle d'exploitation. Le cycle d'exploitation est un processus de surveillance de bout en bout qui garantit que le modèle de production continue de fonctionner et qu'il est entraîné à nouveau pour améliorer les performances au fil du temps. MLOps peut entraîner automatiquement un modèle ML selon un calendrier défini ou lorsqu'il est déclenché par un événement, tel qu'une mesure de performance du modèle tombant en dessous d'un certain seuil.
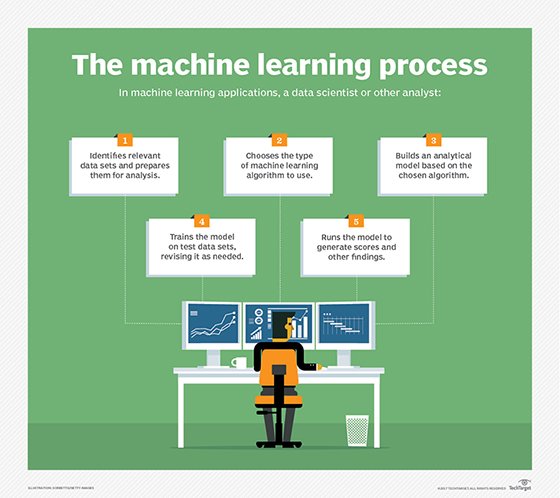
Principales composantes des MLOps
Le processus d'élaboration du modèle MLOps est composé de plusieurs éléments. Ils sont généralement mis en œuvre de manière séquentielle et garantissent la reproductibilité du processus. Les quatre étapes du cycle de vie de MLOps donnent une vue d'ensemble du processus, mais ces cycles peuvent être décomposés en composants plus détaillés :
- Collecte et analyse des données. Les données utiles doivent être identifiées et collectées.
- Préparation des données. Les développeurs nettoient et préparent les données pour garantir un formatage cohérent et une bonne lisibilité avant de les introduire dans le modèle.
- Développement et formation du modèle. Les données préparées sont utilisées pour former le modèle de ML, qui est testé pour s'assurer qu'il produit les informations, les prédictions et les autres résultats nécessaires.
- Déploiement du modèle. Le modèle est mis en production, ce qui le rend accessible aux utilisateurs après qu'il a été développé et testé.
- Surveillance du modèle. Les performances du modèle sont contrôlées pour s'assurer qu'il fonctionne correctement. Tout débogage nécessaire est effectué à ce stade.
- Recyclage des modèles. Les modèles ont besoin de nouvelles données pour continuer à produire des informations et des prévisions précises et actualisées. Le recyclage est un processus continu.
- CI/CD. Cette composante s'applique à l'ensemble du processus, depuis le développement et les tests jusqu'au déploiement et au recyclage. Il automatise et rationalise ces processus.
Pourquoi les MLOps sont-ils nécessaires ?
Les modèles d'apprentissage automatique ne sont pas construits une seule fois et oubliés ; ils nécessitent une formation continue afin de s'améliorer au fil du temps. C'est là que MLOps intervient. Il assure la formation continue et la surveillance constante nécessaires pour garantir le bon fonctionnement des modèles d'apprentissage automatique.
MLOps documente des processus fiables et des stratégies de gouvernance pour prévenir les problèmes, réduire le temps de développement et créer de meilleurs modèles. MLOps utilise des processus reproductibles de la même manière que les entreprises utilisent des flux de travail pour l'organisation et la cohérence. En outre, l'automatisation de MLOps permet de ne pas perdre de temps avec des tâches qui sont répétées à chaque fois que de nouveaux modèles sont construits.

Quels sont les avantages des MLOps ?
MLOps offre une série d'avantages, dont les suivants :
- Rapidité et efficacité. MLOps automatise de nombreuses tâches répétitives dans le développement ML et dans le pipeline ML. Par exemple, l'automatisation des procédures de préparation des données initiales réduit le temps de développement et diminue les erreurs humaines dans le modèle.
- Évolutivité. Les modèles de ML doivent souvent être mis à l'échelle pour gérer des charges de travail accrues, des ensembles de données plus importants et de nouvelles fonctionnalités. Pour assurer l'évolutivité, MLOps utilise des technologies telles que les logiciels conteneurisés et les pipelines de données qui peuvent traiter efficacement de grandes quantités de données.
- Fiabilité. Les tests et la validation des modèles de MLOps permettent de résoudre les problèmes au cours de la phase de développement, ce qui accroît la fiabilité dès le départ. Les processus opérationnels garantissent également que les modèles sont conformes aux politiques mises en place par l'organisation. Cela réduit les risques tels que la dérive des données, dans laquelle la précision d'un modèle se détériore au fil du temps parce que les données sur lesquelles il a été formé ont changé.
Les défis du MLOps
Les MLOps sont peut-être plus efficaces que les approches traditionnelles, mais ils ne sont pas sans poser de problèmes. Ces défis sont notamment les suivants :
- La dotation en personnel. Les scientifiques des données chargés de développer les algorithmes de ML ne sont peut-être pas les plus efficaces pour les déployer. Ils ne sont peut-être pas non plus les mieux équipés pour expliquer aux développeurs de logiciels comment utiliser ces algorithmes. Certaines des meilleures équipes MLOps adoptent l'idée de la diversité cognitive - l'inclusion de personnes qui ont des approches différentes de la résolution de problèmes et offrent des perspectives uniques parce qu'elles pensent différemment.
- Coûts élevés. Les MLOps peuvent être coûteux, étant donné la nécessité de mettre en place une infrastructure qui utilise de nombreux nouveaux outils. Les ressources nécessaires à l'analyse des données, ainsi qu'à la formation des modèles et des employés, sont également coûteuses. Cela est particulièrement vrai pour les projets de ML à grande échelle, avec de nombreuses dépendances et boucles de rétroaction. Il est important pour une organisation intéressée par ces projets d'évaluer si MLOps est la meilleure approche.
- Des processus imparfaits. Bien que les processus MLOps soient conçus pour réduire les erreurs, certaines d'entre elles se produisent toujours et nécessitent une intervention humaine.
- Les cyberattaques. Les acteurs malveillants constituent une menace étant donné la grande quantité de données que les infrastructures MLOps stockent et traitent. La cybersécurité est nécessaire pour minimiser le risque de violations et de fuites de données.
Principaux cas d'utilisation des MLOps
À première vue, le MLOps semble être exclusif à l'industrie technologique ; cependant, d'autres industries trouvent de la valeur dans l'utilisation des pratiques MLOps pour améliorer leurs opérations :
- Finance. La ML permet d'analyser rapidement des millions de points de données. Les sociétés de services financiers peuvent ainsi l'utiliser pour analyser de nombreuses transactions et détecter rapidement les fraudes, par exemple.
- Commerce de détail et commerce électronique. Le commerce de détail s'appuie sur les MLOp pour produire des modèles qui analysent les données d'achat des clients et font des prédictions sur les ventes futures.
- Santé. Le logiciel MLOps est utilisé pour analyser des ensembles de données sur les maladies des patients afin d'aider les institutions à poser des diagnostics plus éclairés.
- Voyages. L'industrie du voyage analyse les données de voyage des clients afin de mieux les cibler avec des publicités pour leurs prochains voyages.
- Logistique. Ce logiciel est utilisé pour analyser les données de performance des différents modes de transport afin de prévoir les défaillances et les risques. Cette pratique est connue sous le nom de maintenance prédictive.
- Fabrication. Les outils MLOps sont utilisés pour surveiller les équipements de fabrication et fournir des capacités de maintenance prédictive.
- Pétrole et gaz. Dans l'industrie du pétrole et du gaz, MLOps surveille les équipements et analyse les données géologiques afin d'identifier les zones propices au forage et à l'extraction du pétrole et du gaz naturel.
MLOps vs. DevOps
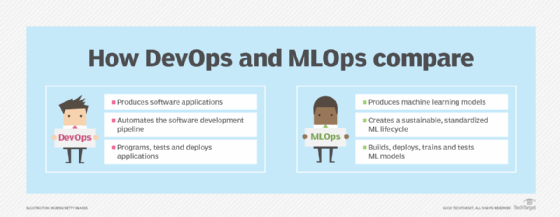
La similitude la plus évidente entre DevOps et MLOps est l'accent mis sur la rationalisation des processus de conception et de production. Cependant, la différence la plus évidente entre les deux est que DevOps produit les versions les plus récentes des applications logicielles pour les clients aussi rapidement que possible, un objectif clé des fournisseurs de logiciels. MLOps s'attache au contraire à surmonter les défis propres à l'apprentissage automatique pour produire, optimiser et maintenir un modèle.
DevOps implique généralement des équipes de développement qui programment, testent et déploient des applications logicielles en production. MLOps signifie faire la même chose avec les systèmes et les modèles de ML, mais avec une poignée de phases supplémentaires. Celles-ci comprennent l'extraction des données brutes pour l'analyse, la préparation des données, l'entraînement des modèles, l'évaluation des performances des modèles, ainsi que la surveillance et l'entraînement en continu.
Ingénierie MLOps vs. ML
Le terme d'ingénierie ML est parfois utilisé de manière interchangeable avec celui de MLOps, mais il existe des différences essentielles. MLOps englobe tous les processus du cycle de vie d'un modèle de ML, y compris l'agrégation des données avant le développement, la préparation des données, ainsi que l'entretien et le recyclage après le déploiement. L'ingénierie ML, quant à elle, se concentre sur les étapes de développement et de test d'un modèle pour la production, à l'instar de ce que font les ingénieurs en logiciel.
Par exemple, une équipe MLOps désigne des ingénieurs ML pour gérer les étapes de formation, de déploiement et de test du cycle de vie MLOps. Ces professionnels possèdent les mêmes compétences que les développeurs de logiciels classiques. D'autres membres de l'équipe opérationnelle peuvent avoir des compétences en analyse de données et effectuer des tâches de pré développement liées aux données. Une fois les tâches d'ingénierie ML achevées, l'équipe dans son ensemble assure une maintenance continue et s'adapte à l'évolution des besoins de l'utilisateur final, ce qui peut nécessiter un réentraînement du modèle avec de nouvelles données.
Meilleures pratiques pour les MLOps
Les équipes MLOps adhèrent à de nombreuses stratégies utiles. L'ensemble des pratiques suivantes peut aider à mener à bien un projet d'apprentissage automatique et à réduire les risques d'échec :
- Une interface de programmation d'application (API) d'un service d'IA existant peut simplifier ou accélérer les MLOps de différentes manières. Par exemple, les API peuvent être utilisées pour récupérer des données à partir de sources de données externes et pour tester automatiquement les modèles de ML.
- Les professionnels du MLOps mènent souvent des processus de développement de modèles en parallèle, de sorte que, si un modèle échoue, d'autres sont encore en cours.
- Les modèles pré-entraînés sont utilisés pour démontrer la validité du concept.
- Les algorithmes généralisés qui donnent de bons résultats sont ensuite formés à une tâche spécifique. Par exemple, un algorithme de régression logistique peut être entraîné à prédire la probabilité d'événements futurs.
- Les sources de données accessibles au public sont utilisées pour combler les lacunes dans les données d'entraînement des modèles, fournir de nouvelles données et prévenir la dérive des modèles.
Comment une organisation peut-elle mettre en œuvre les MLOps ?
Il n'existe pas de méthode unique pour acquérir les employés qualifiés, les outils et l'infrastructure nécessaires pour mener à bien une opération MLOps. Cela dit, il existe trois niveaux de mise en œuvre de MLOps qui coïncident avec les besoins d'une organisation :
- Niveau 0. Ce niveau correspond aux petites entreprises ou aux startups qui n'ont pas besoin de processus MLOps à grande échelle. Cela implique peu ou pas d'automatisation, et les petites équipes de développement gèrent les processus manuellement. Il n'y a pas non plus de CI/CD, de sorte que les modèles déployés sont rarement mis à niveau une fois qu'ils se trouvent dans un environnement de production.
- Niveau 1. Les organisations qui ont besoin de méthodes avancées peuvent mettre en œuvre une formation continue et des outils d'automatisation afin que les processus n'aient pas à être exécutés manuellement. La plus grande différence entre les niveaux 0 et 1 est que le niveau 1 permet de mettre à jour les modèles pour tenir compte de l'évolution des besoins des utilisateurs finaux et des nouvelles données.
- Niveau 2. Le niveau 2 est le plus haut niveau d'automatisation des processus MLOps. Il permet aux organisations d'expérimenter la création d'un plus grand nombre de modèles. Il s'agit d'utiliser des outils de niveau 2 pour mettre en place un pipeline de processus automatisés qui peuvent être facilement reproduits et mis à l'échelle.
Il existe quatre types d'approches de formation en ML. L'apprentissage automatique supervisé est le plus courant, mais il existe également l'apprentissage non supervisé, l'apprentissage semi-supervisé et l'apprentissage renforcé. Découvrez les étapes de la formation à l'apprentissage automatique.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que l'étiquetage des données ?
-
![]()
L'apprentissage par renforcement à partir du feedback humain (RLHF) ?
Par: Andy Patrizio
-
![]()
Qu'est-ce que l'apprentissage par renforcement à partir du feedback humain (RLHF) ?



