Qu'est-ce que l'architecture des données ? Un plan directeur pour la gestion des données

L'architecture des données est une discipline qui consiste à documenter les actifs de données d'une organisation, à cartographier la manière dont les données circulent dans les systèmes informatiques et à fournir un plan directeur pour la gestion des données. Son objectif est de garantir que les données sont gérées correctement et répondent aux exigences commerciales en matière d'informations utilisées pour prendre des décisions.
Si l'architecture des données peut prendre en charge des applications opérationnelles, elle définit surtout l'environnement de données sous-jacent pour les initiatives de veille économique (BI) et d'analyse avancée. Elle produit notamment un cadre multicouche pour les plateformes de données et les outils de gestion des données, ainsi que des spécifications et des normes pour la collecte, l'intégration, la transformation et le stockage des données.
Idéalement, la conception de l'architecture des données est la première étape du processus de gestion des données. Mais ce n'est souvent pas le cas, ce qui crée des environnements incohérents qui doivent être harmonisés dans le cadre d'une architecture de données. De plus, malgré leur nature fondamentale, les architectures de données ne sont pas immuables et doivent être mises à jour à mesure que les données et les besoins de l'entreprise évoluent. Cela fait du travail d'architecture des données une tâche permanente pour les équipes de gestion des données.
L'architecture des données va de pair avec la modélisation des données, qui consiste à créer des diagrammes représentant les structures de données, les règles métier et les relations entre les éléments de données. Il s'agit toutefois de deux disciplines distinctes en matière de gestion des données. Pour expliquer de manière générale en quoi la modélisation des données et l'architecture des données diffèrent, les professionnels font la distinction entre l'approche micro de la modélisation, qui se concentre sur les actifs de données individuels, et l'approche macro plus large de l'architecture des données, qui englobe l'ensemble de ces actifs.
Ce guide sur l'architecture des données explique plus en détail ce qu'elle est, pourquoi elle est importante et les avantages commerciaux qu'elle apporte. Vous y trouverez également des informations sur les cadres d'architecture des données, les meilleures pratiques et bien plus encore. Tout au long du guide, des liens hypertextes renvoient vers des articles connexes qui traitent plus en détail des différents sujets abordés.
Comment les architectures de données ont-elles évolué ?
Dans le passé, la plupart des architectures de données étaient moins complexes qu'aujourd'hui. Elles impliquaient principalement des données structurées provenant de systèmes de traitement des transactions qui étaient stockées dans des bases de données relationnelles. Les environnements analytiques se composaient d'un entrepôt de données, parfois accompagné de petits data marts créés pour des unités commerciales individuelles et d'un magasin de données opérationnelles servant de zone de transit. Les données transactionnelles étaient traitées pour analyse dans des tâches batch, à l'aide de processus traditionnels d'extraction, de transformation et de chargement (ETL) pour l'intégration des données.
À partir du milieu des années 2000, l'adoption des technologies Big Data dans les entreprises a ajouté des formes de données non structurées et semi-structurées à de nombreuses architectures. Cela a conduit au déploiement de lacs de données, qui stockent souvent les données brutes dans leur format natif au lieu de les filtrer et de les transformer pour les analyser au préalable, ce qui représente un changement majeur par rapport au processus d'entreposage des données. Plus récemment, les data lakehouses, qui combinent des éléments des lacs de données et des entrepôts, sont apparus comme une autre plateforme d'analyse. Ces nouvelles approches ont favorisé une utilisation plus large de l'intégration de données ELT, une variante de l'ETL qui inverse les étapes de chargement et de transformation.
L'utilisation croissante des systèmes de traitement des flux a également permis d'intégrer les données en temps réel dans davantage d'architectures de données. Outre les fonctions de base de BI et de reporting pilotées par les entrepôts de données, beaucoup prennent désormais en charge l'intelligence artificielle (IA), l'apprentissage automatique et d'autres applications de science des données. Le passage généralisé aux systèmes basés sur le cloud ajoute encore à la complexité des architectures de données.
Un autre concept architectural émergent est celui de la structure de données, qui vise à automatiser les tâches d'intégration et de gestion des données grâce à des processus réutilisables. Il existe de nombreux cas d'utilisation potentiels dans les environnements de données. Encore plus récent, le maillage de données est une architecture décentralisée qui confère à chaque domaine d'activité la responsabilité de gérer ses propres données. Des processus de gouvernance fédérés sont utilisés pour créer des normes et des politiques en matière de données à l'échelle de l'organisation.
Pourquoi les architectures de données sont-elles importantes ?
Une architecture de données bien conçue est un élément essentiel du processus de gestion des données. Elle soutient les efforts d'intégration et d'amélioration de la qualité des données, ainsi que l'ingénierie et la préparation des données. Elle permet également une gouvernance efficace des données et l'élaboration de normes internes en matière de données. Ces deux éléments aident à leur tour les organisations à garantir l'exactitude et la cohérence de leurs données.
Une architecture de données constitue également le fondement d'une stratégie globale en matière de données qui soutient les objectifs et les priorités de l'entreprise. Les stratégies commerciales dépendent de plus en plus des données. Par conséquent, la gestion et l'utilisation des données sont trop importantes pour être laissées à la discrétion des individus, selon Donald Farmer, directeur du cabinet de conseil TreeHive Strategy. Outre les données elles-mêmes, il a cité les catalogues de données, les outils de gestion des données, diverses techniques d'analyse, les capacités de collaboration et les objectifs documentés comme éléments clés d'une stratégie en matière de données. Mais tout cela doit s'appuyer sur une architecture de données solide.
Outre la mise en place d'une architecture, les principaux aspects du développement d'une stratégie en matière de données comprennent les éléments suivants, comme l'explique Donna Burbank, directrice générale du cabinet de conseil Global Data Strategy :
- Identifier les objectifs commerciaux que les ressources de données d'une organisation doivent soutenir.
- Évaluation de l'état actuel des processus et des technologies de gestion des données.
- Proposer des mises à niveau de l'environnement de gestion des données afin de répondre aux besoins opérationnels.
- Planification et communication d'une feuille de route pour l'architecture et la stratégie des données.

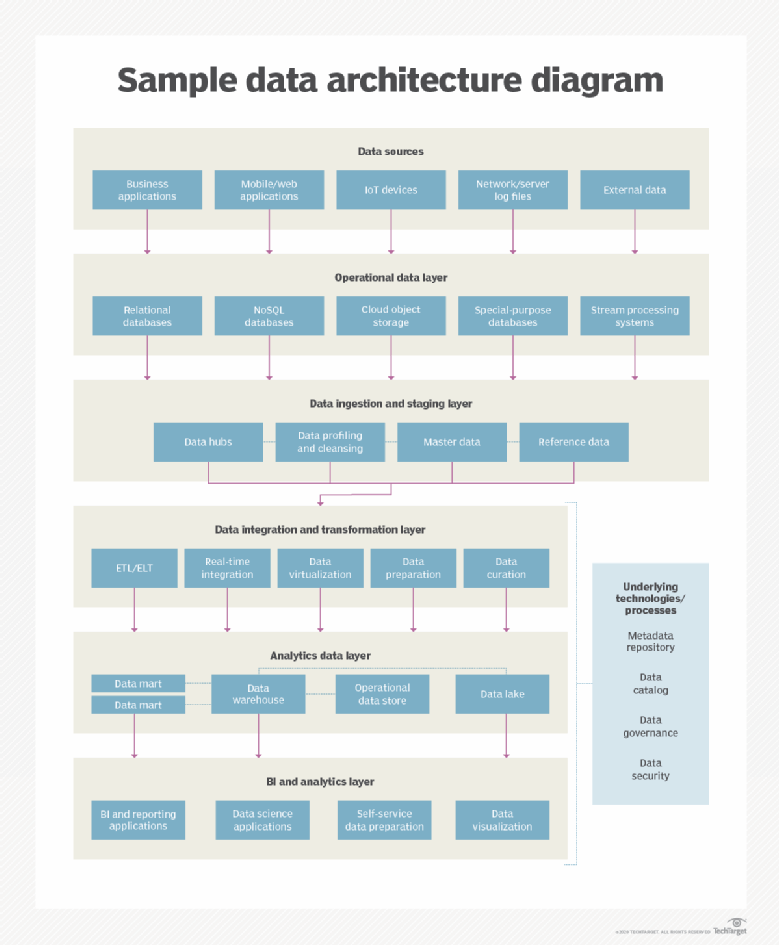
Caractéristiques et composants d'une architecture de données moderne
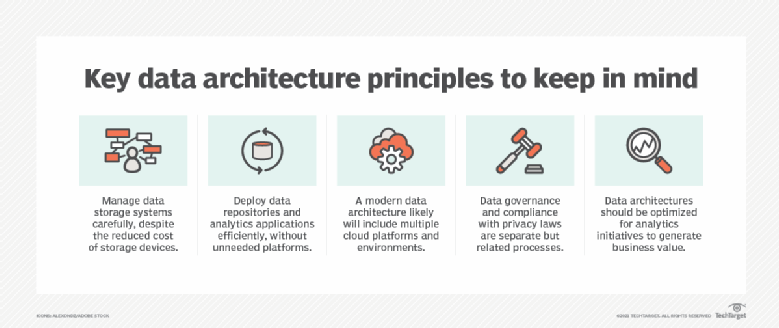
Les principes des architectures de données modernes, également cités par Farmer, comprennent l'alignement avec les processus de gouvernance des données et de conformité réglementaire, la prise en charge des environnements multicloud et des déploiements efficaces qui évitent les plateformes de données inutiles. Une architecture de données doit également garantir que les données sont disponibles pour les utilisations analytiques prévues. Sinon, la valeur commerciale potentielle des données sera gaspillée.
Parmi les autres caractéristiques communes aux architectures de données bien conçues, on peut citer les suivantes :
- Une approche axée sur les activités, alignée sur les stratégies organisationnelles et les exigences en matière de données.
- Flexibilité et évolutivité pour permettre diverses applications et répondre aux nouveaux besoins commerciaux en matière de données.
- Solides mesures de sécurité visant à empêcher tout accès non autorisé aux données et toute utilisation abusive de celles-ci.
Du point de vue d'un puriste, les composants de l'architecture des données n'incluent pas les plateformes, les outils et autres technologies. Une architecture de données est plutôt une infrastructure conceptuelle décrite par un ensemble de diagrammes et de documents, que les équipes de gestion des données utilisent ensuite pour orienter les déploiements technologiques et la manière dont les données sont gérées.
Voici quelques exemples de ces composants, communément appelés artefacts :
- Modèles de données, définitions des données et vocabulaires communs pour les éléments de données.
- Diagrammes de flux de données illustrant la manière dont les données circulent à travers les systèmes et les applications.
- Documents qui établissent une correspondance entre l'utilisation des données et les processus métier, tels que la matrice CRUD (acronyme de « create, read, update and delete », soit créer, lire, mettre à jour et supprimer).
- Autres documents décrivant les objectifs, les concepts et les fonctions de l'entreprise afin d'aider à aligner les initiatives de gestion des données sur ceux-ci.
- Politiques et normes qui régissent la manière dont les données sont collectées, intégrées, transformées et stockées.
- Un plan architectural de haut niveau, avec différentes couches pour des processus tels que l'ingestion, l'intégration et le stockage des données.
Si les éléments technologiques sont intégrés, une architecture de données moderne comprend ceux mentionnés précédemment dans la section consacrée à l'évolution, ainsi que d'autres, comme indiqué ci-dessous :
- Entrepôts de données, lacs de données et entrepôts de lacs de données.
- Systèmes, stockage et applications cloud.
- Outils d'intelligence artificielle et d'apprentissage automatique.
- Systèmes de streaming de données et d'analyse en temps réel.
- Diverses méthodes d'intégration des données.
- Connecteurs API pour rationaliser le partage de données entre les applications.
- Pipelines de données qui fournissent les données nécessaires aux utilisateurs.
- Applications conteneurisées et microservices.
Quels sont les avantages d'une architecture de données ?
Une architecture de données bien conçue aide les organisations à développer des plateformes d'analyse de données efficaces qui fournissent des informations et des connaissances utiles. Ces connaissances améliorent la planification stratégique et la prise de décision opérationnelle, ce qui peut conduire à de meilleures performances commerciales et à des avantages concurrentiels. Elles facilitent également d'autres types d'applications, telles que la recherche scientifique, les programmes gouvernementaux et le diagnostic et le traitement de pathologies médicales.
De plus, l'architecture des données offre les avantages suivants en matière de gestion des données :
- Amélioration de la qualité des données.
- Intégration simplifiée des données.
- Réduction des coûts de stockage des données.
- Amélioration de la cohérence des données entre les systèmes.
- Une gouvernance des données plus efficace.
- Une meilleure collaboration en matière de gestion et de gouvernance des données.
Pour ce faire, elle adopte une approche globale de l'entreprise, contrairement à la modélisation des données spécifiques à un domaine ou à l'architecture au niveau de la base de données, selon Peter Aiken, consultant en gestion des données et professeur agrégé en systèmes d'information à la Virginia Commonwealth University.
L'architecture des données apporte une « finalité » aux efforts visant à garantir que les actifs de données soutiennent les stratégies commerciales, a déclaré M. Aiken lors d'un webinaire Dataversity en octobre 2023. « L'architecture est ce que vous utilisez comme guide pour déterminer comment vous allez utiliser ces [actifs]. »
Quels sont les risques liés à une mauvaise conception de l'architecture des données ?
L'une des difficultés liées à l'architecture des données réside dans sa complexité excessive. La redoutable « architecture spaghetti » en est la preuve, avec son enchevêtrement de lignes représentant différents flux de données et connexions point à point. Il en résulte un environnement de données disparate, avec des silos de données incompatibles difficiles à intégrer à des fins d'analyse. Ironiquement, les projets d'architecture de données visent souvent à mettre de l'ordre dans des environnements désorganisés qui se sont développés de manière organique. Mais s'ils ne sont pas gérés avec soin, ils peuvent créer des problèmes similaires.
Un autre défi consiste à obtenir un accord universel sur les définitions, les formats et les exigences standardisés en matière de données. Sans cela, il est difficile de créer une architecture de données efficace. Il peut également être difficile de replacer les données dans un contexte commercial. Bien conçue, l'architecture de données reflète la signification commerciale des données. Mais si ce n'est pas le cas, cela peut créer un décalage entre l'architecture et les exigences stratégiques en matière de données qu'elle est censée satisfaire. Par conséquent, le travail d'architecture de données doit être axé sur la pratique, a déclaré M. Aiken lors du webinaire Dataversity. « Si cela ne fait pas bouger les choses, cela ne vaut probablement pas la peine d'y investir. »
Architecture des données vs modélisation des données
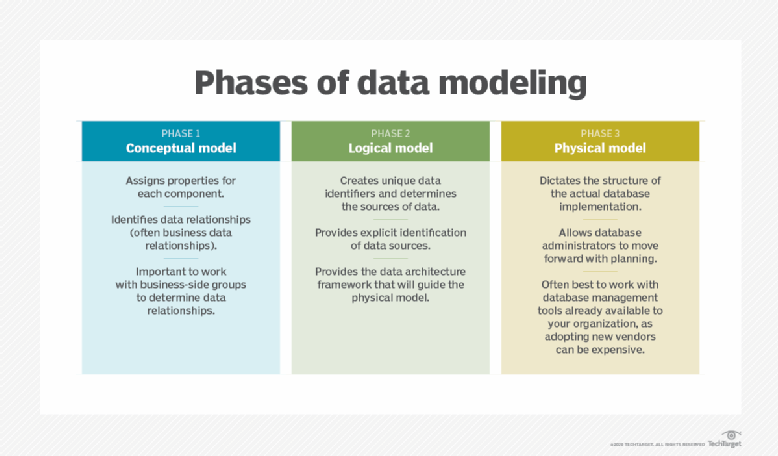
La modélisation des données se concentre sur les détails d'actifs de données spécifiques. Elle crée une représentation visuelle des entités de données, de leurs attributs et des relations entre les différentes entités. Cela permet de définir les besoins en données des applications et des systèmes, puis de concevoir des structures de bases de données pour les données, un processus qui s'effectue à travers une progression de modèles de données conceptuels, logiques et physiques.
L'architecture des données examine l'ensemble des données d'une organisation afin de créer un cadre pour leur gestion et leur utilisation. Mais, comme mentionné précédemment, la modélisation des données et l'architecture des données se complètent mutuellement. Les modèles de données sont un élément crucial des architectures de données, et une architecture de données bien établie simplifie la modélisation des données, selon David Loshin, président et consultant principal chez Knowledge Integrity Inc.
Il existe différentes techniques pour modéliser les données. Les plus utilisées actuellement sont les approches de modélisation entité-relation, dimensionnelle et graphique. Les deux premières sont des variantes du modèle de données relationnel qui sous-tend les bases de données relationnelles, mais elles peuvent également être utilisées pour modéliser d'autres types de données. La modélisation graphique des données est principalement utilisée pour cartographier les relations dans les bases de données graphiques qui stockent les données dans des structures de type graphique.
Voici quelques bonnes pratiques en matière de modélisation des données :
- Rassemblez à l'avance les exigences commerciales et les besoins en données avant de créer des modèles.
- Développez des modèles de données de manière itérative et incrémentale afin de rendre le processus gérable.
- Utilisez les modèles de données comme outil pour communiquer avec les utilisateurs professionnels au sujet de leurs besoins.
- Gérez les modèles de données comme n'importe quel autre type de code d'application.
Architecture des données vs architecture de l'information et architecture d'entreprise
Bien qu'elles semblent similaires, il existe une différence entre l'architecture des données et l'architecture de l'information dans les applications d'entreprise. Elle réside dans la différence fondamentale entre les données et l'information : cette dernière est le résultat des données. Ainsi, une architecture de l'information définit le contexte de gestion des opérations commerciales et de prise de décision, y compris les flux d'informations au sein d'une organisation et avec les clients et partenaires commerciaux. Une architecture de données qui fournit des données fiables et de haute qualité constitue la base de l'architecture de l'information.
Par ailleurs, l'architecture des données est généralement considérée comme un sous-ensemble de l'architecture d'entreprise (EA), qui vise à créer un plan organisationnel dans quatre domaines. Outre les données, l'EA englobe les trois domaines suivants :
- L'architecture d'entreprise, qui englobe la stratégie commerciale et les processus opérationnels clés.
- Architecture applicative, qui se concentre sur les applications individuelles et leurs relations avec les processus métier.
- Architecture technologique, qui comprend les systèmes informatiques, les réseaux et les technologies supplémentaires qui soutiennent les trois autres domaines.
Quels sont les cadres d'architecture de données disponibles ?
Les organisations peuvent utiliser des cadres normalisés pour concevoir et mettre en œuvre des architectures de données au lieu de partir de zéro. Voici trois options de cadres bien connues :
- DAMA-DMBOK2. DAMA-DMBOK : Data Management Body of Knowledge, tel qu'il est officiellement nommé, est un cadre de gestion des données et un guide de référence créé par DAMA International, une association professionnelle pour les gestionnaires de données. Aujourd'hui dans sa deuxième édition et communément appelé DAMA-DMBOK2, ce cadre traite de l'architecture des données ainsi que d'autres disciplines liées à la gestion des données. La première édition a été publiée en 2009. La deuxième édition est disponible depuis 2017 et a été révisée en 2024.
- TOGAF. Créé en 1995 et mis à jour à plusieurs reprises depuis lors, la dernière fois en 2022, TOGAF est un cadre et une méthodologie d'architecture d'entreprise qui comprend une section sur la conception de l'architecture des données et l'élaboration d'une feuille de route. Il a été développé par The Open Group, et TOGAF signifiait initialement The Open Group Architecture Framework. Mais il est désormais simplement appelé la norme TOGAF.
- Le cadre Zachman. Il s'agit d'un cadre ontologique qui utilise une matrice de six lignes et six colonnes pour décrire l'architecture d'une entreprise, y compris les éléments de données. Il ne comprend pas de méthodologie de mise en œuvre, mais sert plutôt de base à une architecture. Ce cadre a été initialement développé en 1987 par John Zachman, un cadre supérieur d'IBM qui a pris sa retraite en 1990 et fondé une société de conseil appelée Zachman International, qui continue de le superviser.
Étapes clés pour la création d'une architecture de données
Les équipes chargées de la gestion des données doivent travailler en étroite collaboration avec les dirigeants d'entreprise et les autres utilisateurs finaux afin de développer une architecture de données. Si elles ne le font pas, celle-ci risque de ne pas être en phase avec les stratégies commerciales et les exigences en matière de données. Deux étapes clés de la planification de l'architecture de données consistent à dialoguer avec les cadres supérieurs afin d'obtenir leur soutien et à rencontrer les utilisateurs afin de comprendre leurs besoins en matière de données.
Les autres mesures à prendre sont les suivantes :
- Évaluer les risques liés aux données en fonction des directives en matière de gouvernance des données.
- Classez les ensembles de données en fonction de leur utilisation et de leur degré de sensibilité.
- Suivez les flux de données, ainsi que les informations relatives au cycle de vie et à la traçabilité des données.
- Documenter et évaluer l'infrastructure technologique existante en matière de gestion des données.
- Définir une feuille de route pour les projets de déploiement de l'architecture de données.
Les mêmes étapes s'appliquent à la mise en place d'une architecture cloud pour la gestion et l'analyse des données, comme le font de plus en plus les entreprises. Mais les équipes chargées de la gestion des données sont confrontées à de nouveaux défis potentiels en matière de conception d'architecture dans le cloud, notamment les exigences en matière de sécurité des données, les obligations de conformité réglementaire et les problèmes de gravité des données qui peuvent compliquer la migration des ensembles de données depuis les systèmes sur site.
Quels sont les différents rôles dans la conception et le développement d'une architecture de données ?
Sans surprise, les architectes de données jouent généralement un rôle de premier plan dans les initiatives d'architecture de données. Ils doivent posséder diverses compétences techniques, ainsi que la capacité d'interagir et de communiquer avec les utilisateurs professionnels. Un architecte de données passe beaucoup de temps à travailler avec les utilisateurs finaux afin de documenter les processus métier et l'utilisation actuelle des données, ainsi que les nouvelles exigences en matière de données.
Sur le plan technique, les architectes de données créent eux-mêmes des modèles de données et supervisent le travail de modélisation effectué par d'autres. Ils élaborent également des plans d'architecture de données, des diagrammes de flux de données et d'autres artefacts. D'autres tâches peuvent consister à définir les processus d'intégration des données et à superviser l'élaboration de définitions de données, de glossaires métier et de catalogues de données. Dans certaines organisations, les architectes de données sont également chargés de concevoir des plateformes de données et d'évaluer et de sélectionner des technologies de gestion des données.
Les autres professionnels de la gestion des données qui participent souvent au processus d'architecture des données sont les suivants :
- Modélisateurs de données. Ils travaillent également avec les utilisateurs professionnels pour évaluer les besoins en données et examiner les processus métier. Ils utilisent ensuite les informations recueillies pour créer des modèles de données.
- Développeurs d'intégration de données. Une fois l'architecture mise en œuvre, ils sont chargés de créer des tâches ETL et ELT pour intégrer les ensembles de données.
- Ingénieurs de données. Ils construisent les pipelines qui acheminent les données vers les scientifiques de données et autres analystes. Ils aident également les équipes de science des données dans le processus de préparation des données.
Craig Stedman est un rédacteur spécialisé qui crée des dossiers approfondis sur l'analyse, la gestion des données, la cybersécurité et d'autres domaines technologiques pour TechTarget Editorial.
Pour approfondir sur MDM - Gouvernance - Qualité
-
![]()
Le guide complet sur le SASE (Secure Access Service Edge)
Par: Jennifer English
-
![]()
Apache Camel, Mule ESB, Spring : bien choisir son framework d’intégration
Par: Twain Taylor
-
![]()
MDD, développement piloté par les modèles
-
![]()
Serverless vs microservices : lequel choisir en fonction de votre projet
Par: Joydip Kanjilal