Qu'est-ce que le pré-entraînement d'un modèle linguistique amélioré par la recherche ?

Un modèle linguistique amélioré pour la récupération, également appelé REALM ou RALM, est un modèle linguistique d'intelligence artificielle (IA) conçu pour récupérer du texte et l'utiliser ensuite pour effectuer des tâches basées sur des questions.
Le préapprentissage d'un tel système consiste à former le modèle à une tâche avant de l'entraîner à travailler sur une autre tâche ou un autre ensemble de données. L'utilisation d'un modèle déjà formé de manière adjacente est un moyen rapide et efficace de créer des applications d'intelligence artificielle, en donnant au modèle une longueur d'avance dans la formation, par rapport à la formation d'un nouveau modèle à partir de zéro. Le processus de pré-entraînement du modèle linguistique permet également de capturer une grande partie de la connaissance du monde qui peut être cruciale pour les tâches de traitement du langage naturel (NLP) des réseaux neuronaux, telles que la réponse aux questions.
Google a introduit le pré-entraînement des modèles de langage augmentés par la recherche en 2020 dans un document sur l'utilisation de modèles de langage masqués, comme BERT, pour répondre à des questions à livre ouvert. Ce processus utilise le corpus - ou la collection de données utilisée pour former l'IA - de documents avec une architecture de modèle de langage. Cela aide le modèle REALM à trouver les documents, leurs passages les plus pertinents et à renvoyer les données pertinentes pour l'extraction d'informations.
Architecture de base de REALM
Les modèles augmentés par récupération utilisent généralement un mécanisme de récupération sémantique. Par exemple, REALM utilise un récupérateur de connaissances et un encodeur augmenté de connaissances. Le récupérateur de connaissances aide le modèle de langage étendu (LLM) - un type d'algorithme d'IA qui utilise des techniques d'apprentissage profond et des ensembles de données massifs pour comprendre, résumer, générer et prédire de nouveaux contenus - à trouver et à se concentrer sur un texte spécifique à partir d'un vaste corpus de connaissances. Lorsque l'utilisateur saisit une invite (prompt), l'objectif du récupérateur de connaissances est d'identifier les documents pertinents. Un outil d'encodage enrichi de connaissances est ensuite utilisé pour extraire les données correctes du texte. Le texte et l'invite originale sont ensuite transmis au LLM pour répondre à la question initiale de l'utilisateur.
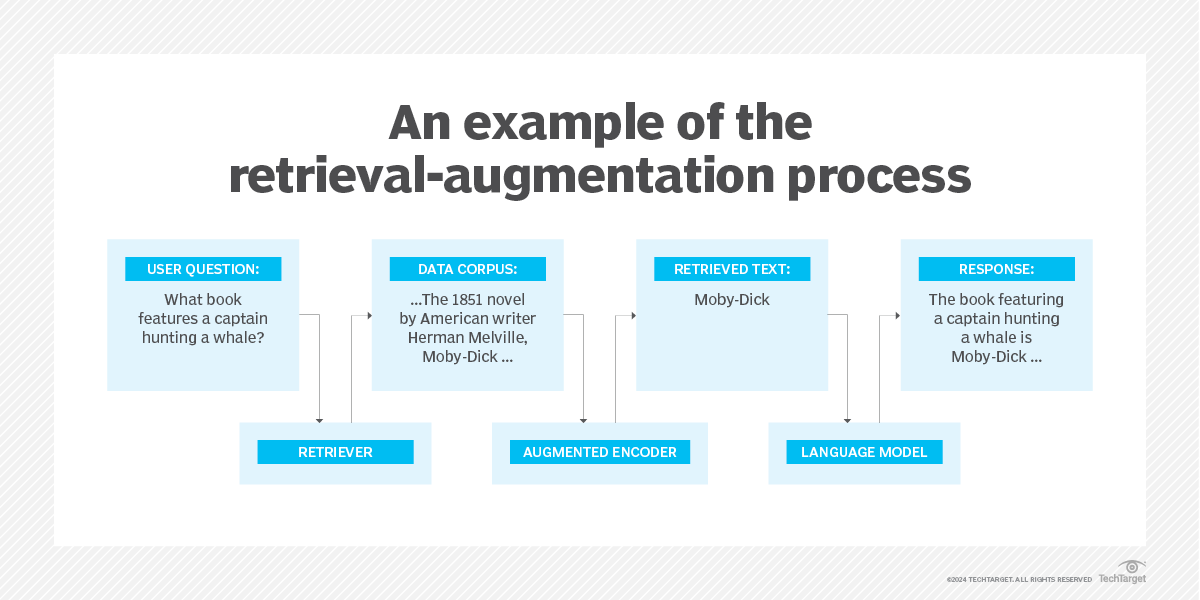
Les étapes d'un programme de préformation
Les programmes pré-entraînés nécessitent un modèle d'apprentissage automatique et deux ensembles de données différents. Les étapes de base sont les suivantes :
- Former le modèle d'apprentissage automatique à l'aide de son ensemble de données d'apprentissage initial. Les étapes de la formation initiale consistent généralement en une phase d'évaluation visant à déterminer si une formation est nécessaire ; une phase de développement, au cours de laquelle le matériel de formation, l'environnement et les divers outils sont élaborés ou choisis ; une phase d'exécution au cours de laquelle la formation commence ; et une phase d'évaluation de référence au cours de laquelle l'efficacité de la formation est déterminée. Un ensemble de données de formation initial diversifié expose le modèle à différentes caractéristiques, modèles et représentations de données.
- Définir les paramètres du modèle et la manière dont il utilise l'ensemble des données de formation initiales. Par exemple, dans REALM, les tâches de pré-entraînement et de réglage fin sont formalisées sous la forme d'un processus génératif de récupération puis de prédiction.
- Commencez à entraîner le modèle sur le nouvel ensemble de données. Il est important que le nouvel ensemble de données soit similaire à la formation initiale du modèle. Par exemple, l'entraînement d'un modèle déjà entraîné à prédire les mesures du trafic ne serait pas utile s'il était ensuite entraîné à détecter des objets. En revanche, un modèle formé à la détection d'objets serait utile pour créer un modèle capable d'identifier des animaux.
Le préapprentissage est généralement appliqué à l'apprentissage par transfert, à la classification ou à l'extraction de caractéristiques.
- L'apprentissage par transfert utilise les données obtenues à partir d'un modèle d'apprentissage automatique pour un autre modèle.
- La classification fait référence à un modèle d'apprentissage automatique formé pour des tâches de classification, telles que la classification d'images.
- L'extraction de caractéristiques identifie et extrait les caractéristiques pertinentes d'un ensemble de données, les caractéristiques extraites étant ensuite utilisées dans un autre modèle.
Avantages et inconvénients de la préformation
Les avantages de la préformation sont les suivants
- Facilité d'utilisation. Les développeurs n'ont pas besoin de créer des modèles à partir de zéro. Ils peuvent à la place trouver un modèle pré-entraîné qui a été entraîné sur une tâche similaire et l'entraîner à nouveau sur la tâche spécifique sur laquelle ils travaillent.
- Optimisation des performances. Un modèle pré-entraîné peut atteindre des performances optimales plus rapidement, car il peut déjà connaître les paramètres susceptibles de produire de bons résultats.
- Ne nécessite pas de grandes quantités de données d'apprentissage. Les modèles pré-entraînés ne nécessitent pas autant de données d'entraînement que la construction d'un modèle à partir de zéro. En outre, les modèles disponibles en ligne sont susceptibles d'avoir déjà été entraînés sur des ensembles de données extrêmement importants.
- Amélioration des tâches liées à la PNL. Le pré-entraînement REALM améliore l'efficacité des tâches liées au NLP, telles que celles qui consistent à répondre à des questions.
Les inconvénients potentiels de la préformation peuvent toutefois être les suivants :
- Nécessite un réglage fin. Le processus de réglage fin peut être gourmand en ressources et nécessite du temps pour un réglage efficace.
- Produit des résultats inefficaces. L'utilisation d'un modèle déjà formé pour une tâche trop différente de sa tâche initiale ne produira pas de résultats efficaces en matière de formation.
Génération augmentée en fonction de la recherche, modèle linguistique augmenté en fonction de la recherche et LLMs
Les modèles linguistiques augmentés par récupération, les LLM et la génération augmentée par récupération (RAG) sont tous étroitement liés. REALM et RAG sont tous deux des modèles et des cadres d'IA qui fonctionnent avec des LLM.
Mais alors que REALM est un modèle linguistique conçu pour extraire du texte d'un corpus de données de formation initiale et l'utiliser ensuite pour répondre à des tâches basées sur des questions à forte intensité de connaissances, RAG est conçu pour accéder à des informations externes, distinctes de ses données de formation initiale. Par exemple, RAG peut extraire des données de sources externes telles que des bases de connaissances externes, des bases de données ou l'internet.
Les modèles de LLM ont généralement une date de fin de formation, après laquelle le LLM n'est pas au courant des nouveaux événements ou développements. Cela signifie que les gestionnaires de l'apprentissage tout au long de la vie ne travaillent généralement pas avec les informations les plus récentes et les plus actualisées, ce qui a pour effet de figer les connaissances d'un gestionnaire de l'apprentissage tout au long de la vie à un moment donné. Les GCR contournent cette limitation en puisant dans des sources d'information externes en temps réel. Cela améliore la qualité des réponses tout en réduisant les hallucinations de l'IA. Si un modèle d'IA comme ChatGPT utilisait des RAG, il ne serait pas limité en fonction de la date de fin de sa formation.
REALM peut également être associé à l'apprentissage à partir de zéro, qui est un concept d'apprentissage automatique permettant de reconnaître des échantillons de classes sur lesquelles le modèle n'a pas été initialement formé.
Pré-entraînement et mise au point
Alors que la préformation est le concept d'entraînement d'un modèle d'apprentissage automatique précédemment entraîné sur une tâche similaire avec de nouvelles données d'entraînement, le réglage fin fait référence au processus d'affinage d'un modèle pré entraîné pour qu'il fonctionne sur des tâches particulières. Le réglage fin utilise un ensemble de données plus petit dans le but d'ajuster et de spécialiser le modèle pour qu'il s'adapte à une tâche spécifique. Un exemple de ceci est le réglage fin d'un LLM pour l'analyse des sentiments.
Les concepts de pré-entraînement et de réglage fin ne sont toutefois pas exclusifs. Par exemple, un modèle REALM peut être pré-entraîné puis affiné par la suite. Le réglage fin permet au modèle de tirer parti de ses vastes connaissances acquises lors du préapprentissage tout en se spécialisant dans une tâche cible spécifique. Le réglage fin permet également d'obtenir de meilleures performances dans sa tâche.
En savoir plus sur le RAG et les autres tendances actuelles en matière d'IA et d'apprentissage automatique.






