Qu'est-ce que l'erreur de prédiction ?
Une erreur de prédiction est l'incapacité d'un modèle de système à prévoir avec précision les résultats. Il s'agit de la différence entre la valeur prédite et la valeur mesurée. L'erreur absolue moyenne, l'erreur quadratique moyenne et l'erreur quadratique moyenne de prédiction font partie des méthodes utilisées pour calculer la précision du modèle prédictif.
Les erreurs sont un élément inévitable de l'analyse prédictive qui doit être quantifié et présenté avec tout modèle, souvent sous la forme d'un intervalle de confiance qui indique la précision attendue des prédictions. L'analyse des erreurs de prédiction de modèles similaires ou antérieurs peut aider à déterminer les intervalles de confiance.
Il est impossible d'éliminer les erreurs de prédiction. L'objectif est plutôt de minimiser et de classer l'erreur. Lorsque l'erreur potentielle est comprise, l'analyste peut avoir confiance dans les valeurs données et prendre des décisions basées sur les valeurs prédites.
Les logiciels d'analyse prédictive traitent les données nouvelles et historiques afin de prévoir les activités, les comportements et les tendances. Les programmes appliquent des techniques d'analyse statistique, des requêtes analytiques et des algorithmes d'apprentissage automatique à des ensembles de données pour créer des modèles prédictifs qui quantifient la probabilité qu'un événement particulier se produise.
Types d'erreurs de prédiction
Les données d'apprentissage sous-jacentes sont souvent la source d'erreurs de prédiction dans les modèles d'apprentissage automatique. Voici quelques problèmes courants :
- Biais. Un biais est une entrée donnée qui est surévaluée ou sous-évaluée par rapport à une valeur objective.
- Sous-ajustement. Le modèle de formation n'est pas suffisamment complexe pour capturer les caractéristiques importantes des données, ce qui donne lieu à des suppositions sur-généralisées en sortie.
- Sur ajustement. Dans le cas d'un sur ajustement, le modèle d'apprentissage est trop complexe et capture le bruit ou les caractéristiques indésirables des données d'apprentissage, ce qui se traduit par un résultat trop sensible.
- Variance. De petits changements dans les données d'apprentissage entraînent de grands changements dans le modèle final.
- Erreur de généralisation. Le modèle fait de mauvaises prédictions lorsqu'il reçoit de nouvelles données en dehors de l'ensemble d'apprentissage.
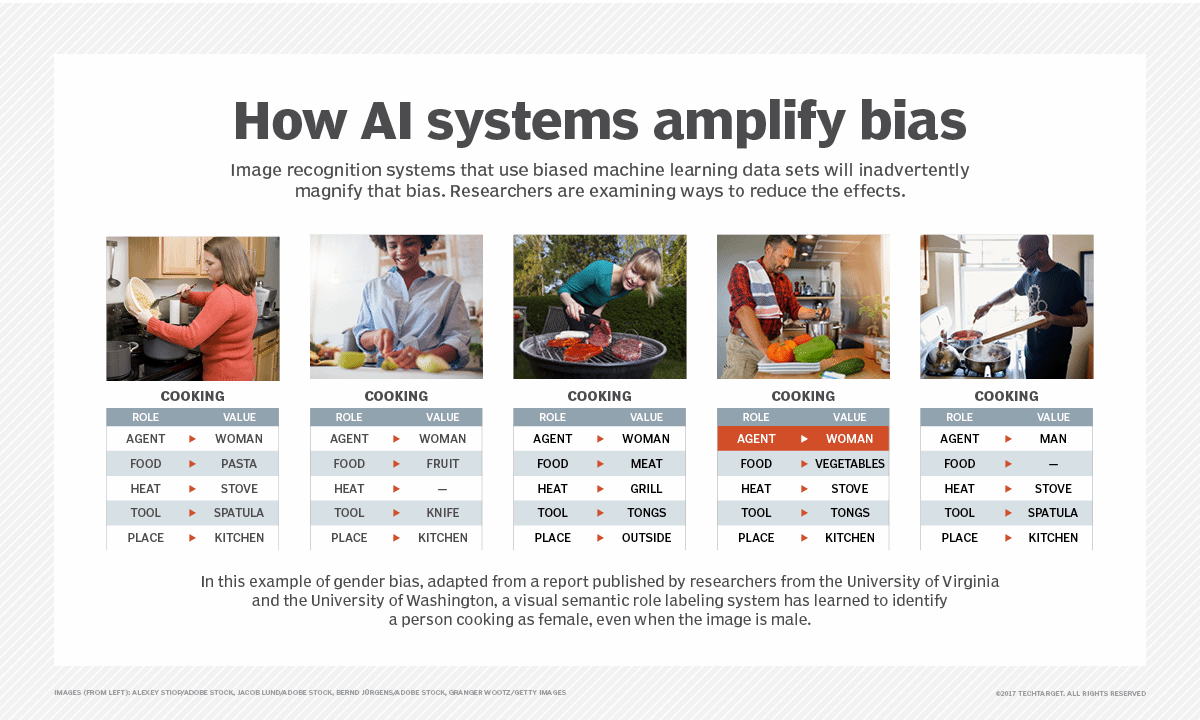
Erreurs de prédiction dans l'IA et la ML
Dans l'IA, l'analyse des erreurs de prédiction peut aider à guider la ML, de la même manière qu'elle le fait pour l'apprentissage humain.
Dans l'apprentissage par renforcement, par exemple, un agent peut utiliser l'objectif de minimiser le retour d'erreur comme moyen de s'améliorer. Dans ce cas, les erreurs de prédiction peuvent se voir attribuer une valeur négative et les résultats prédits une valeur positive, auquel cas l'IA est programmée pour tenter de maximiser son score. Cette approche de la ML, parfois appelée apprentissage par l'erreur, cherche à stimuler l'apprentissage en se rapprochant de la volonté humaine de maîtrise.
La ML a beaucoup plus d'utilisations potentielles que l'analyse statistique. Les outils de ML peuvent être utilisés dans des tâches de reconnaissance vocale ou de vision artificielle. Dans ces tâches, les paramètres et les caractéristiques des données et du modèle peuvent être examinés afin de déterminer pourquoi le modèle a mal classé une entrée donnée.
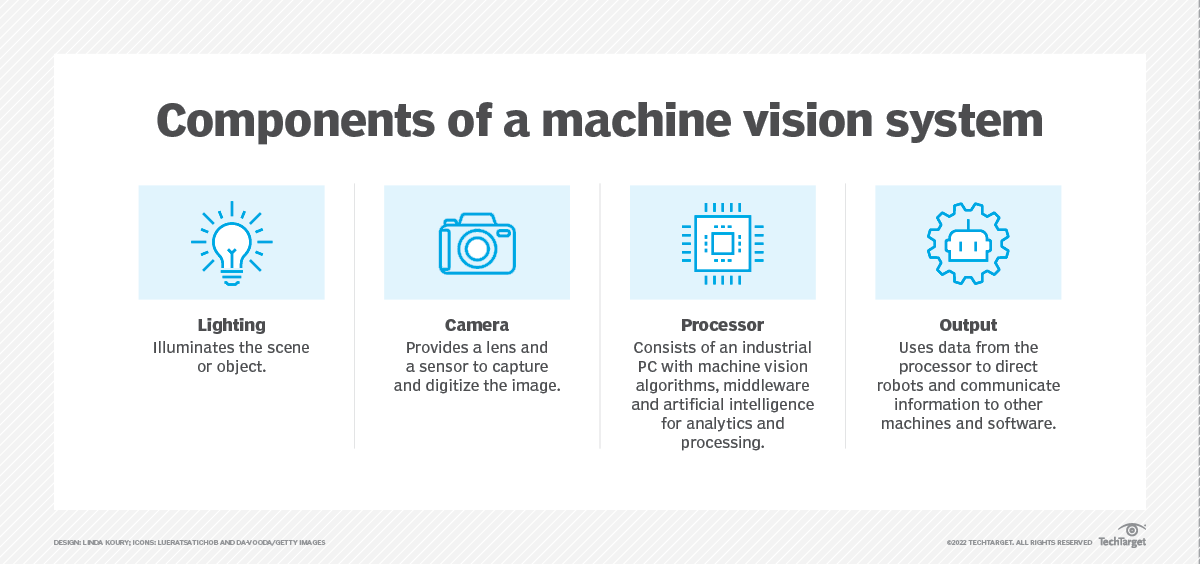
Lors de la construction d'un modèle sur des données de tableau, il peut être difficile de déterminer la cause de l'erreur. La corrélation exacte entre les valeurs et la raison pour laquelle une sortie spécifique est donnée peut ne pas être intuitive.
Comment minimiser les erreurs de prédiction
L'analyse humaine des erreurs de prédiction est cruciale. Lorsque les prédictions échouent, les humains peuvent utiliser des fonctions métacognitives, en examinant les prédictions et les échecs antérieurs et en décidant, par exemple, s'il existe des corrélations et des tendances, comme l'incapacité constante à prévoir les résultats avec précision dans des situations particulières.
L'application de ce type de connaissances peut éclairer les décisions et améliorer la qualité des prévisions futures. Ces étapes supplémentaires peuvent contribuer à minimiser les erreurs de prédiction :
- Assainissement des données. Inspecter les données sources pour détecter les valeurs aberrantes, les données incomplètes et les inexactitudes.
- Transformation des données. Normaliser et formater les données.
- Réglage des paramètres. Sélectionner et tester différents paramètres d'apprentissage du modèle.
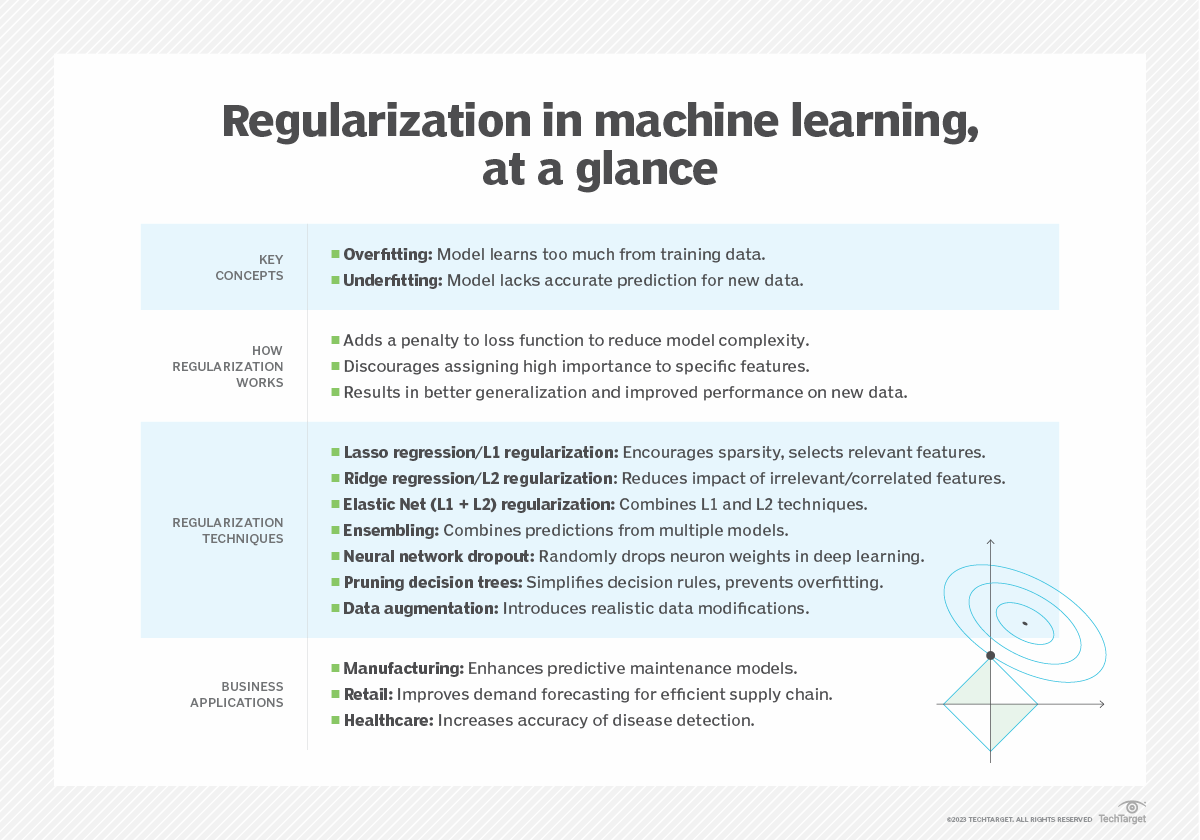
- Régularisation. Utilisez la régularisation L1 ou L2 pour pénaliser les erreurs et éviter l'ajustement excessif.
- Test de prédiction. Analyser les résultats du modèle dans un environnement contrôlé et les affiner si nécessaire.
La performance de tout modèle prédictif doit être évaluée en permanence. Les résultats obtenus sont-ils supérieurs à un seuil d'erreur acceptable ? Les données d'entrée ont-elles changé par rapport au moment où le modèle a été formé ? Le modèle répond-il toujours aux principaux critères de réussite ? L'itération et l'actualisation permanente du modèle peuvent contribuer à minimiser les erreurs de prédiction.
La régularisation en ML représente un ensemble précieux de techniques qui peuvent aider à atténuer le risque de sur ajustement. En employant ces stratégies, les scientifiques des données peuvent améliorer les performances des modèles de ML et réduire les erreurs potentiellement coûteuses, pour finalement bénéficier du résultat global de leur travail. En savoir plus sur la régularisation ML à l'aide d'exemples (en anglais).






