Qu'est-ce qu'un modèle de transformateur ?
Un modèle de transformateur est une architecture de réseau neuronal capable de transformer automatiquement un type d'entrée en un autre type de sortie. Le terme a été inventé en 2017 dans un article de Google intitulé "Attention Is All You Need" (L'attention est tout ce dont vous avez besoin). Ce document de recherche examine comment les huit scientifiques qui l'ont rédigé ont trouvé un moyen de former un réseau neuronal pour la traduction de l'anglais vers le français avec plus de précision en un quart du temps de formation d'autres réseaux neuronaux.
Les modèles transformateurs sont particulièrement aptes à déterminer le contexte et la signification en établissant des relations dans des données séquentielles, telles qu'une série de mots parlés ou écrits ou les relations entre des structures chimiques. Les techniques mathématiques employées dans les modèles de transformateurs sont appelées attention ou auto-attention et permettent aux modèles de déterminer la manière dont les points de données sont liés les uns aux autres.
La notion d'attention existe depuis les années 1990 en tant que technique de traitement. Cependant, en 2017, l'équipe de Google a suggéré qu'elle pouvait utiliser l'attention pour encoder directement le sens des mots et la structure d'une langue donnée. Il s'agissait d'une avancée révolutionnaire, car elle remplaçait ce qui nécessitait auparavant une étape d'encodage supplémentaire à l'aide d'un réseau neuronal dédié. Elle a également permis de modéliser virtuellement n'importe quel type d'information, ouvrant la voie aux extraordinaires percées qui ont vu le jour.
La technique s'est avérée plus généralisable que les auteurs ne l'avaient imaginé, et les transformateurs ont été utilisés pour générer du texte, des images et des instructions pour robots. Ils peuvent également modéliser les relations entre différents modes de données, ce que l'on appelle l'intelligence artificielle multimodale (IA), pour transformer des instructions en langage naturel en images ou en instructions pour robots. La large utilisation des modèles de transformateurs et les tendances à la généralisation des transformateurs ont conduit à leur désignation en tant que modèles de base, fournissant des modèles généraux préformés que les organisations peuvent adapter et peaufiner à des fins spécifiques beaucoup plus rapidement et facilement que la construction d'un modèle à partir de zéro.
Pratiquement toutes les applications qui utilisent le traitement du langage naturel (NLP) utilisent maintenant des transformateurs sous le capot parce qu'ils sont plus performants que les approches précédentes. Les chercheurs ont également découvert que les modèles de transformateurs peuvent apprendre à travailler avec des structures chimiques, à prédire le pliage des protéines et à analyser des données médicales à grande échelle. Les transformateurs sont essentiels dans toutes les applications de grands modèles de langage (LLM), notamment ChatGPT d'OpenAI, Google Search, Dall-E d'OpenAI et Microsoft Copilot.
Que peuvent faire les modèles de transformateurs ?
Dans de nombreuses applications, les transformateurs supplantent progressivement les types d'architectures de réseaux neuronaux d'apprentissage profond précédemment populaires, notamment les réseaux neuronaux récurrents (RNN) et les réseaux neuronaux convolutifs (CNN). Les RNN étaient idéaux pour traiter des flux de données, tels que des discours, des phrases et des codes. Mais ils ne pouvaient traiter que des chaînes de caractères courtes à la fois. Les techniques plus récentes, telles que la mémoire à long terme, étaient des approches RNN qui pouvaient prendre en charge des chaînes plus longues, mais qui restaient limitées et lentes. En revanche, les transformateurs peuvent traiter des séries plus longues et chaque mot ou jeton en parallèle, ce qui leur permet de s'adapter plus efficacement.
Les CNN sont idéaux pour le traitement des données, comme l'analyse en parallèle de plusieurs régions d'une photo pour rechercher des similitudes dans les caractéristiques, telles que les lignes, les formes et les textures. Ces réseaux sont optimisés pour comparer des zones proches. Les modèles Transformer, tels que Vision Transformer introduit en 2021, en revanche, semblent mieux réussir à comparer des régions éloignées les unes des autres et ont fait leurs preuves dans les applications de vision par ordinateur. Les transformateurs sont également plus performants lorsqu'il s'agit de travailler avec des données non étiquetées.
Les transformateurs peuvent apprendre à représenter efficacement le sens d'un texte en analysant de grandes quantités de données non étiquetées. Les chercheurs peuvent ainsi faire évoluer les transformateurs pour qu'ils prennent en charge des centaines de milliards, voire des trillions de caractéristiques. Dans la pratique, les modèles pré-entraînés créés à partir de données non étiquetées ne servent que de point de départ pour un affinement ultérieur dans le cadre d'une tâche spécifique avec des données étiquetées. Toutefois, cela est acceptable car l'étape secondaire nécessite moins d'expertise et de puissance de traitement.
Les modèles de transformateurs ont été acceptés dans un large éventail de cas d'utilisation directe de l'IA, notamment les suivants :
- Tâches NLP. Transformers est capable d'ingérer, de comprendre, de traduire et de reproduire des langues humaines en temps quasi réel.
- Tâches financières et de sécurité. Les transformateurs peuvent traiter et analyser de nombreuses données financières ou de trafic réseau afin de détecter et de signaler les anomalies, ce qui permet d'éviter les fraudes et les violations de la sécurité.
- Analyse des idées. Les modèles Transformer peuvent ingérer et traiter une grande quantité d'informations et produire des résumés ou des aperçus appropriés - pensez aux CliffsNotes pour les livres, les collections et même des sujets entiers.
- Entités d'IA simulées. Les logiciels, tels que les chatbots, peuvent combiner des fonctions de langage, d'analyse et de synthèse conçues pour interagir avec les gens, répondre à leurs questions et les aider à résoudre des problèmes. Google Gemini en est un exemple.
- Analyse et conception pharmaceutiques. Les modèles Transformer peuvent aider les chercheurs dans l'analyse chimique et l'analyse de l'ADN, accélérant ainsi la conception et le perfectionnement de nouveaux médicaments puissants.
- Création de médias. Les modèles transformateurs peuvent produire des images, des vidéos et de la musique génératives sur la base d'une invite textuelle de l'utilisateur. Dall-E d'OpenAI en est un exemple.
- Tâches de programmation. Les modèles de transformateurs peuvent compléter des segments de code, analyser et optimiser le code, et effectuer des tests approfondis.
Architecture du modèle de transformateur
L'architecture d'un transformateur se compose d'un codeur et d'un décodeur qui fonctionnent ensemble. Le mécanisme d'attention permet aux transformateurs d'encoder la signification des mots en fonction de l'importance estimée d'autres mots ou tokens. Cela permet aux transformateurs de traiter tous les mots ou tokens en parallèle pour des performances plus rapides, ce qui contribue à la croissance de LLM de plus en plus grands.
En utilisant le mécanisme d'attention, le bloc encodeur transforme chaque mot ou jeton en vecteurs pondérés par d'autres mots. Par exemple, dans les deux phrases suivantes, le sens de "il" est pondéré différemment, en raison du remplacement du mot "rempli" par "vidé" :
- Il verse la cruche dans la tasse et la remplit.
- Il a versé la cruche dans la tasse et l'a vidée.
Le mécanisme d'attention le relie à la tasse que l'on remplit dans la première phrase et au pichet que l'on vide dans la deuxième phrase.
Le décodeur inverse essentiellement le processus dans le domaine cible. Le cas d'utilisation initial était la traduction de l'anglais vers le français, mais le même mécanisme pourrait traduire des questions et des instructions anglaises courtes en réponses plus longues. Inversement, il peut traduire un article long en un résumé plus concis.
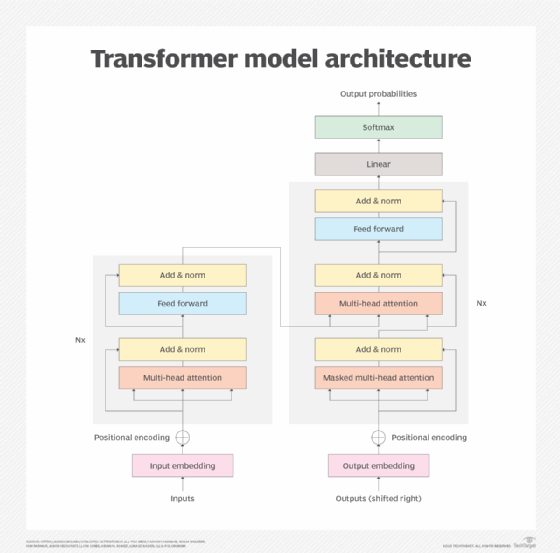
- Entrée. L'intégration des données convertit un flux de données brutes en un ensemble de données que le modèle peut traiter. Par exemple, des mots parlés ou écrits peuvent être convertis en données. Les données résultant de cette conversion capturent les caractéristiques de l'entrée, telles que la sémantique et la syntaxe des mots. Les données produites lors de cette conversion sont une caractéristique du processus d'apprentissage du modèle. Le reste du modèle peut traiter les données résultantes.
- Encodage positionnel. Les modèles de transformateurs ne comprennent pas de sens natif du positionnement ou de l'ordre d'entrée, de sorte que le codage positionnel comble ce manque de données et dérive des informations sur la position des données en cours d'entrée. Par exemple, les transformateurs ne connaissent pas l'ordre des mots dans une phrase, de sorte que l'encodage positionnel indique au modèle la position des mots dans la phrase. Le codage positionnel indique donc au modèle la position des mots dans la phrase, ce qui lui permet d'évaluer l'ordre des mots.
- Mécanisme d'attention. Le cœur du modèle de transformateur est le mécanisme d'attention, qui est généralement un mécanisme d'auto-attention avancé à têtes multiples. Ce mécanisme permet au modèle de traiter et de déterminer ou de contrôler l'importance de chaque élément de données. Le terme "multi-têtes" signifie que plusieurs itérations du mécanisme fonctionnent en parallèle, ce qui permet au modèle d'examiner différentes relations entre les données et de déterminer la relation la plus probable ou la plus sensée.
- Les réseaux neuronaux de type "feed-forward". Un réseau neuronal non linéaire transforme ensuite les représentations établies par le mécanisme d'attention. Ces réseaux neuronaux permettent au modèle transformateur d'apprendre des schémas complexes et des nuances dans les données, qui sont plus détaillés et plus précis que le mécanisme d'attention seul.
- Techniques de normalisation. La normalisation des données permet au modèle de standardiser ou de placer des garde-fous autour des valeurs de données qu'il traite. Le modèle est ainsi protégé contre les valeurs de données extrêmes ou les variations inhabituelles susceptibles de fausser le processus de transformation et d'aboutir à un résultat médiocre. Des techniques de normalisation supplémentaires, telles que les connexions résiduelles, sont utilisées pour traiter le problème des gradients qui s'évanouissent lorsque le modèle est difficile à former.
- Sortie. Le mécanisme de sortie est chargé de générer la sortie finale du modèle. Il comprend généralement une transformation linéaire, ainsi qu'une fonction softmax qui convertit les nombres vectoriels en une distribution de probabilités. Par exemple, un traducteur anglais-français sélectionne et ordonne les mots en français. Bien que la sortie soit généralement créée mot par mot, les transformateurs avancés peuvent produire des phrases ou des paragraphes entiers en même temps. Le texte peut être affiché directement, ou la parole peut être produite par une conversion texte-parole supplémentaire.
Formation au modèle de transformateur
La formation d'un transformateur comporte deux phases essentielles. Dans la première phase, un transformateur traite un grand nombre de données non étiquetées pour apprendre la structure de la langue ou d'un phénomène, tel que le pliage des protéines, et la manière dont les éléments proches semblent s'influencer les uns les autres. Il s'agit là d'un aspect coûteux et énergivore du processus. La formation de certains des plus grands modèles peut coûter des millions de dollars.
Une fois le modèle formé, il est utile de l'affiner pour une tâche particulière. Une entreprise technologique pourrait vouloir régler un chatbot pour qu'il réponde à différentes demandes de service à la clientèle et d'assistance technique avec des niveaux de détail variables en fonction des connaissances de l'utilisateur. Un cabinet d'avocats peut adapter un modèle d'analyse des contrats. Une équipe de développement peut adapter le modèle à sa vaste bibliothèque de codes et à ses conventions de codage uniques.
Le processus de réglage fin nécessite beaucoup moins d'expertise et de puissance de traitement. Les partisans des transformateurs affirment que les dépenses importantes liées à la formation de modèles généraux plus grands, ou modèles de base, peuvent être rentables car elles permettent d'économiser du temps et de l'argent en adaptant le modèle à un grand nombre de cas d'utilisation différents.
Le nombre de caractéristiques d'un modèle est parfois utilisé comme indicateur de ses performances au lieu de mesures plus pertinentes. Cependant, le nombre de caractéristiques - ou la taille du modèle - n'est pas directement corrélé à la performance ou à l'utilité. Il est possible d'entraîner un modèle avec davantage de paramètres tout en obtenant des résultats moins précis que le même modèle entraîné avec moins de paramètres. Dans la pratique, les modèles formés avec de grands volumes de données sont souvent utiles pour des capacités plus larges où une précision moindre est acceptable.
Mise en œuvre du modèle de transformateur
Les implémentations de transformateurs s'améliorent en termes de taille et de prise en charge de nouveaux cas d'utilisation ou de domaines différents, tels que la médecine, la science ou les applications commerciales. Voici quelques-unes des implémentations de transformateurs les plus prometteuses :
- Le Bidirectional Encoder Representations from Transformers (BERT) de Google a été l'un des premiers LLM basés sur des transformateurs. Il existe une myriade de versions différentes de BERT, notamment BERT base, BERT large, RoBERTa, DistilBERT, TinyBERT, ALBERT, ELECTRA et FinBERT.
- Le GPT de l'OpenAI a suivi le mouvement et a connu plusieurs itérations, notamment GPT-2, GPT-3, GPT-3.5, GPT-4 et GPT-4o. Le GPT-5 est actuellement en cours de développement.
- Le lama de Meta atteint des performances comparables avec des modèles 10 fois plus grands. Le Llama 3.3, qui a été publié en décembre 2024, devrait éclipser ces capacités.
- Le modèle linguistique Pathways (PaLM) de Google généralise et exécute des tâches dans plusieurs domaines, notamment le texte, les images et les commandes robotiques. Le modèle PaLM 2 est disponible, ainsi que les modèles populaires Gemini.
- Dall-E 3 crée des images à partir d'une courte description textuelle.
- Le Gatortron de l'Université de Floride et de Nvidia analyse les données non structurées des dossiers médicaux. Il utilise le cadre de modélisation du langage Megatron de Nvidia, basé sur des transformateurs, sur un DGX SuperPOD avec plus de 1 000 unités de traitement graphique A100.
- AlphaFold 3 de Google DeepMind décrit comment les protéines se plient et peut prédire les interactions entre les protéines et d'autres molécules.
- MegaMolBART d'AstraZeneca et de Nvidia génère de nouveaux médicaments candidats à base de petites molécules à partir de données sur la structure chimique.







