Qu'est-ce que la génération de langage naturel (NLG) ?
La génération de langage naturel (NLG) est l'utilisation de la programmation de l'intelligence artificielle (IA) pour produire des récits écrits ou parlés à partir d'un ensemble de données. La génération de langage naturel est liée à l'interaction entre l'homme et la machine et entre la machine et l'homme, y compris la linguistique informatique, le traitement du langage naturel (NLP) et la compréhension du langage naturel (NLU).
La recherche sur le NLG se concentre souvent sur la création de programmes informatiques qui fournissent des points de données en contexte. Les logiciels NLG sophistiqués peuvent extraire de grandes quantités de données numériques, identifier des modèles et partager ces informations d'une manière facile à comprendre pour les humains. La rapidité des logiciels de NLG est particulièrement utile pour la production d'actualités et d'autres sujets sensibles au temps sur l'internet. Dans le meilleur des cas, les résultats du NLG peuvent être publiés mot pour mot en tant que contenu web.
Comment fonctionne le NLG ?
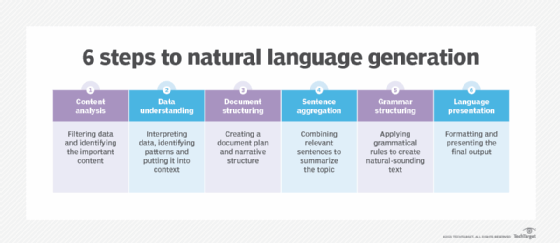
Le NLG est un processus en plusieurs étapes, chaque étape permettant d'affiner les données utilisées pour produire un contenu à consonance naturelle. Les six étapes du NLG sont les suivantes :
- Analyse du contenu. Les données sont filtrées pour déterminer ce qui doit être inclus dans le contenu produit à la fin du processus. Cette étape comprend l'identification des principaux sujets dans le document source et les relations entre eux.
- Compréhension des données. Les données sont interprétées, des modèles sont identifiés et elles sont mises en contexte. L'apprentissage automatique est souvent utilisé à ce stade.
- Structuration du document. Un plan du document est créé et une structure narrative est choisie en fonction du type de données interprétées.
- Agrégation de phrases. Les phrases ou parties de phrases pertinentes sont combinées de manière à résumer correctement le sujet.
- Structuration grammaticale. Des règles grammaticales sont appliquées pour générer un texte à consonance naturelle. Le programme déduit la structure syntaxique de la phrase. Il utilise ensuite cette information pour réécrire la phrase d'une manière grammaticalement correcte.
- Présentation du langage. La sortie finale est générée sur la base d'un modèle ou d'un format sélectionné par l'utilisateur ou le programmeur.
Comment le NLG est-il utilisé ?
La génération de langage naturel est utilisée de multiples façons. Voici quelques-unes des nombreuses utilisations possibles :
- générer les réponses des chatbots et des assistants vocaux tels que Alexa de Google et Siri d'Apple ;
- convertir des rapports financiers et d'autres types de données commerciales en un contenu facilement compréhensible pour les employés et les clients ;
- l'automatisation des réponses aux courriels de maturation des prospects, à la messagerie et au chat ;
- personnaliser les réponses aux courriels et aux messages des clients ;
- la génération et la personnalisation de scripts utilisés par les représentants du service clientèle ;
- l'agrégation et la synthèse d'informations ;
- faire rapport sur l'état des dispositifs de l'internet des objets ; et
- créer des descriptions de produits pour les pages web du commerce électronique et les messages destinés aux clients.
NLG vs. NLU vs. NLP
La PNL est un terme générique qui fait référence à l'utilisation d'ordinateurs pour comprendre le langage humain, qu'il soit écrit ou verbal. Le NLP s'appuie sur un cadre de règles et de composants et convertit les données non structurées en un format de données structuré.
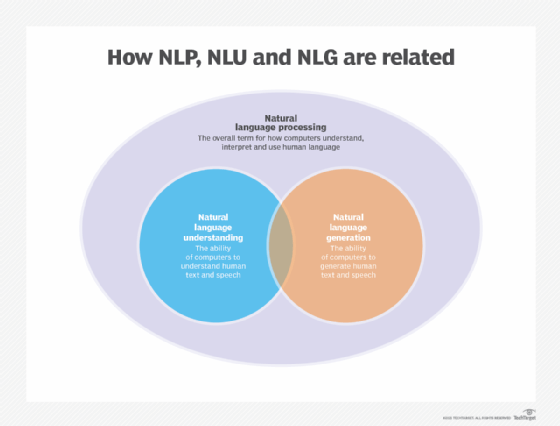
Le NLP englobe à la fois le NLG et le NLU, qui ont les capacités suivantes, distinctes mais liées :
- Le NLU désigne la capacité d'un ordinateur à utiliser l'analyse syntaxique et sémantique pour déterminer le sens d'un texte ou d'un discours.
- Le NLG permet aux appareils informatiques de générer du texte et de la parole à partir de données.
Les chatbots et les fonctions de "texte suggéré" dans les clients de messagerie, comme Smart Compose de Gmail, sont des exemples d'applications qui utilisent à la fois la compréhension du langage naturel et la génération de langage naturel. La compréhension du langage naturel permet à un ordinateur de comprendre le sens de l'entrée de l'utilisateur, et la génération de langage naturel fournit la réponse textuelle ou vocale d'une manière que l'utilisateur peut comprendre.
Le NLG est lié à la fois au NLU et à la recherche d'informations. Elle est également liée au résumé de texte, à la génération de discours et à la traduction automatique. Une grande partie de la recherche fondamentale en matière de NLG recoupe également la linguistique informatique et les domaines concernés par l'interaction entre l'homme et la machine et entre la machine et l'homme.
Modèles et méthodologies NLG
Le NLG s'appuie sur des algorithmes d'apprentissage automatique et d'autres approches pour créer du texte généré par une machine en réponse aux entrées de l'utilisateur. Voici quelques-unes des méthodologies utilisées :
Chaîne de Markov. Le modèle de Markov est une méthode mathématique utilisée en statistique et en apprentissage automatique pour modéliser et analyser des systèmes capables de faire des choix aléatoires, tels que la génération de langues. Les chaînes de Markov commencent par un état initial, puis génèrent aléatoirement les états suivants en fonction de l'état précédent. Le modèle apprend à connaître l'état actuel et l'état précédent, puis calcule la probabilité de passer à l'état suivant en fonction des deux précédents. Dans un contexte d'apprentissage automatique, l'algorithme crée des expressions et des phrases en choisissant des mots qui sont statistiquement susceptibles d'apparaître ensemble.
Réseau neuronal récurrent (RNN). Ces systèmes d'intelligence artificielle sont utilisés pour traiter des données séquentielles de différentes manières. Les RNN peuvent être utilisés pour transférer des informations d'un système à un autre, par exemple pour traduire des phrases écrites dans une langue à une autre. Les RNN sont également utilisés pour identifier des modèles dans les données, ce qui peut aider à identifier des images. Un RNN peut être entraîné à reconnaître différents objets dans une image ou à identifier les différentes parties du discours dans une phrase.
Mémoire à long terme (LSTM). Ce type de RNN est utilisé dans l'apprentissage profond lorsqu'un système doit apprendre à partir de l'expérience. Les réseaux LSTM sont couramment utilisés dans les tâches de NLP car ils peuvent apprendre le contexte nécessaire au traitement de séquences de données. Pour apprendre les dépendances à long terme, les réseaux LSTM utilisent un mécanisme de gating pour limiter le nombre d'étapes précédentes qui peuvent affecter l'étape actuelle.
Transformateur. Cette architecture de réseau neuronal est capable d'apprendre les dépendances à long terme dans le langage et de créer des phrases à partir de la signification des mots. Transformer est lié à l'IA. Il a été développé par OpenAI, une société de recherche en IA à but non lucratif située à San Francisco. Transformer comprend deux encodeurs : l'un pour traiter les entrées de toute longueur et l'autre pour produire les phrases générées.
Les trois principaux modèles de transformateurs sont les suivants :
- Generative Pre-trained Transformer (GPT) est un type de technologie NLG utilisé avec les logiciels de business intelligence (BI). Lorsque le GPT est mis en œuvre avec un système de veille stratégique, il utilise la technologie NLG ou des algorithmes d'apprentissage automatique pour rédiger des rapports, des présentations et d'autres contenus. Le système génère du contenu sur la base des informations qu'il reçoit, qui peuvent être une combinaison de données, de métadonnées et de règles de procédure.
- Bidirectional Encoder Representations from Transformers (BERT) est le successeur du système Transformer que Google a créé à l'origine pour son service de reconnaissance vocale. BERT est un modèle linguistique qui apprend le langage humain en apprenant les informations syntaxiques, c'est-à-dire les relations entre les mots, et les informations sémantiques, c'est-à-dire le sens des mots.
- XLNet est un réseau neuronal artificiel formé à partir d'un ensemble de données. Il identifie des modèles qu'il utilise pour tirer une conclusion logique. Un moteur NLP peut extraire des informations à partir d'une simple requête en langage naturel. XLNet vise à s'auto-apprendre à lire et à interpréter des textes et à utiliser ces connaissances pour écrire de nouveaux textes. XLNet se compose de deux parties : un encodeur et un décodeur. L'encodeur utilise les règles syntaxiques du langage pour convertir les phrases en une représentation vectorielle ; le décodeur utilise ces règles pour reconvertir la représentation vectorielle en une phrase significative.
Découvrez pourquoi le NLP est à la pointe de l'adoption de l'IA et le rôle clé que jouent le NLP et le NLG dans l'application de l'IA au sein de l'entreprise.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que l'IA conversationnelle (intelligence artificielle conversationnelle) ?
-
![]()
Qu'est-ce qu'un réseau neuronal récurrent ?
Par: Nicole Laskowski
-
![]()
Qu'est-ce que la compréhension du langage naturel (NLU) ?
Par: Alexander Gillis
-
![]()
Qu'est-ce que le traitement du langage naturel (NLP) ?
Par: Ben Lutkevich



