Trust Score : l’approche de Talend pour améliorer la qualité des données
Talend a présenté cette semaine les améliorations d’une fonctionnalité peu mise en avant jusqu’alors : le Trust Score. Ce système de note se retrouve maintenant dans plusieurs outils de la plateforme d’intégration cloud Talend Data Fabric pour inciter les métiers à améliorer la qualité de la donnée.
« Isoler les processus de qualité et de gouvernance de la donnée, pour nous, cela n’a pas de sens », déclare Jean-Michel Franco, directeur senior du marketing produit chez Talend. « Mais il faut aussi pouvoir démocratiser l’amélioration de la qualité des données. Aujourd’hui, c’est le premier défi du Chief Data Officer qui ne dispose pas de la bonne matière première. Nous nous devons de simplifier les structures de gouvernance », ajoute-t-il.
C’est en quelque sorte la raison d’être de Talend Cloud Data Inventory. La brique de gouvernance devient un composant central de Talend Data Fabric, selon Jean-Michel Franco. Introduit en avril dans le cadre de la release Winter, Data Inventory « est capable de capturer tous les jeux de données qui circulent sur la plateforme » et lui associer un score de confiance : le Talend Trust Score.
Plus spécifiquement, Data Inventory, permet de lister les jeux de données créés ou collectés avec Talend Cloud Pipeline Designer et Cloud Data Preparation, en choisissant dans une liste d’une vingtaine de connecteurs JDBC vers les principales sources de données en entreprise (HDFS, Amazon S3, Amazon Kinesis, Kafka, Google PubSub, BigQuery, Snowflake, Salesforce, Marketo, MySQL, etc.). Il est également possible d’y déposer des datasets « locaux » au format CSV, Excel, Avro ou Parquet, en glisser-déposer depuis l’interface web associée.
Talend va y ajouter au quatrième trimestre des crawlers pour extraire automatiquement les jeux de données disponibles depuis les connecteurs JDBC Talend Data Fabric et les mettre à jour à l’aide d’un système de planification.
« J’ai tendance à penser que les entreprises qui ont réussi dernièrement ont mis en place un indice de confiance, par exemple Blablacar pour le covoiturage. Il n’y a pas d’équivalent dans l’IT. ».
Jean-Michel FrancoDirecteur senior marketing produit,Talend
Pour l’instant, l’éditeur ne les propose pas pour toutes les sources de données. « Nous allons d’abord fournir des crawlers pour les data warehouses, des bases de données SQL puis les systèmes de fichiers, et les applications SaaS », indique Jean-Michel Franco.
Ces agents seront d’abord capables d’extraire les jeux de données hébergés dans le cloud. Talend met notamment en avant le crawler consacré au data warehouse Snowflake. Par ailleurs, ils sont uniquement compatibles avec les données relationnelles.
L’outil associe automatiquement le fameux score de confiance aux data sets en s’appuyant sur la qualité des données, la documentation apportée par les métadonnées et une notation issue d’une production participative (crowdsourcing). Pour cela, il constitue automatiquement un échantillon de référence, stocké dans le cloud.
« Les retours des clients nous ont poussés à mettre ce Trust Score au premier plan », assure Jean-Michel Franco. « J’ai tendance à penser que les entreprises qui ont réussi dernièrement ont mis en place un indice de confiance, par exemple Blablacar pour le covoiturage. Il n’y a pas d’équivalent dans l’IT : il y a des données partout et il est difficile de savoir quels sont les jeux les plus pertinents pour un cas d’usage donné ».
Aie confiance, crois au Trust Score
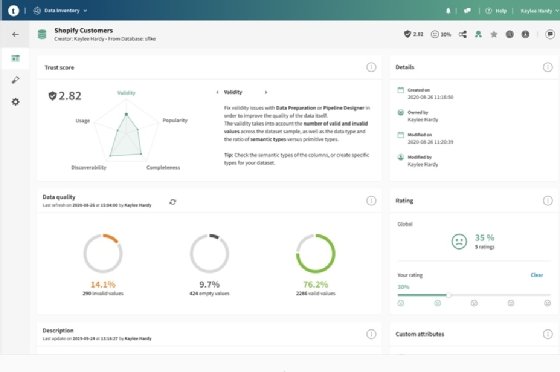
Le Trust Score est accompagné d'un diagramme radar pour l'expliquer.
Depuis avril, Talend propose à ses clients trois mécaniques pour former ce score. La première est un moteur d’analyse sémantique associé à une base ontologique qu’il est possible de compléter. Il permet de repérer les cellules vides, valides ou invalides dans une colonne. Dans le principe il s’agit de vérifier la pertinence de la donnée inscrite dans une cellule par rapport à l’intitulé de la colonne via un algorithme de logique floue (fuzzywuzzy avec Python, ou distance de Levensthein en mathématiques).
La deuxième consiste en un outil de notation en pourcentage par les utilisateurs. La troisième mécanique permet aux propriétaires-créateurs de certifier un jeu de données. Il est également possible de les partager avec des collaborateurs ou encore les inscrire en favoris.
« Le calcul du score est basé sur cinq dimensions : la validité de la donnée, la complétude, la popularité, la “découvrabilité” et l’usage ».
« Les retours des clients nous ont poussé à mettre ce Trust Score au premier plan. »
Jean-Michel FrancoDirecteur senior marketing produit, Talend
La validité est fonction de l’analyse des types sémantiques ; la complétude de valeurs non définies ; la popularité du partage des data sets par les utilisateurs ; la découvrabilité des renseignements fournis par le propriétaire et l’éditeur (nombre de notes, description, documentation, certifications, etc.) ; et l’analyse de l’usage est calculée en fonction de leur utilisation dans d’autres services, actuellement Data Preparation et Data Pipeline Designer.
« Nous ajouterons par la suite les autres outils de la suite en commençant par Stitch et Data StewardShip », précise le responsable du marketing produit. « On envisage également de rendre compatible le Trust Score avec d’autres outils du marché ». Toutes ces dimensions sont corrélées pour afficher la fameuse note.
Reste à l’interpréter. « Nos clients ont des exigences d’explicabilité », rappelle le responsable marketing. Actuellement, le score est représenté par une note allant de 1 à 5, la visualisation du Trust Score évoluera pour intégrer les relations entre les cinq dimensions via un diagramme radar.
Ce calcul est en principe immuable. Il n’est pas possible de personnaliser la note. « Nous voulons que ce soit systématique, applicable à tous les jeux de données », indique Jean-Michel Franco, mais il sera tout de même possible d’optimiser les dimensions via un moteur de règles.
Mauvaise qualité des données : responsabiliser les métiers
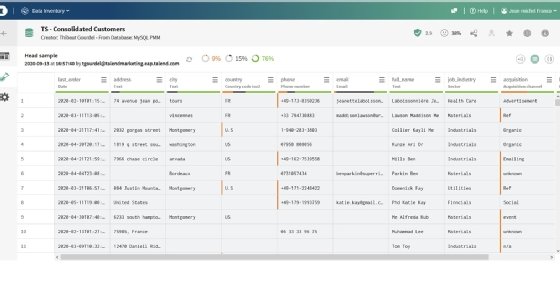
Les données erronées sont surlignées en rouge.
Data Inventory fournit également un score par colonne, exprimé en pourcentage et visuellement représenté par des couleurs (vert et rouge), pour comparer la pertinence des contenus des cellules avec l’intitulé des colonnes. Cette fonctionnalité s’adresse directement aux métiers. Les cellules invalides sont indiquées en rouge et un bouton donne accès à Data Preparation pour modifier ou supprimer les informations erronées.
Dans l’exemple ci-dessus, les numéros de téléphone soulignés en rouge ne disposent pas du bon indicatif par rapport aux pays d’origine du client. Ce travail peut être réparti via Talend Data Stewardship. L’outil doit faciliter la création de workflows collaboratifs de modifications de jeux de données et de leur source. Un responsable peut désigner une équipe et lui demander de remplir une tâche dans un temps imparti.
« Nous avons un cas d’usage en interne. Nous avons réattribué les comptes clients aux commerciaux par secteur, mais notre colonne correspondante dans notre CRM n’était pas standardisée. Ce fut facile de motiver les commerciaux pour les corriger », témoigne Jean-Michel Franco.
L’accès à Data Pipeline Designer doit permettre plus globalement d’améliorer la manière de constituer un data set en sélectionnant les bonnes sources et les bonnes tables.
L’objectif peu original, parce que commun à d’autres éditeurs : obtenir une seule source de vérité. « Souvent quand il y a des problèmes de qualité, on essaye de les résoudre, mais pas au bon endroit. Si les données Salesforce sont mauvaises, c’est dans Salesforce qu’il faut les modifier », considère le responsable.
Le Trust Score permet de responsabiliser les métiers concernant le problème de la qualité des données » vante Jean-Michel Franco. « Libérer la valeur cachée des données, c’est la clé du succès. Pour ça, nous avons besoin que les métiers et l’IT s’entendent sur la même chose. C’est exactement ce que fait le Trust Score, » explique Arnaud Maton, Responsable du Service Data Management du Groupe Kiloutou, dans un communiqué de presse. « Il fournit un indicateur clé de la santé des données, lisible, compréhensible et actionnable pour tous. Le tout au cœur de notre projet “Data for Business” qui vise à rendre les données fiables, accessibles et utilisables. ».
« Si vous êtes data engineer et que vous devez exploiter des data sets pour un projet analytique et que le score est mauvais, vous vous dites : je ne peux pas laisser ça dans mon data warehouse. Nous pensons que cela va changer la donne. Habituellement, la qualité est le problème d’un autre. Le Trust Score vous confronte directement au problème », déclare Jean-Michel Franco, convaincu.
Le Trust Score, un argument clé pour la stratégie cloud de Talend
Le Talend Trust Score est aussi un argument pour l’éditeur afin de pousser à l’adoption de ses produits cloud. C’est le chemin que prend le secteur de l’intégration et de la gouvernance. L’éditeur doit faire face à une concurrence déterminée.
« Nous avons le fait choix de commercialiser Data Inventory uniquement dans le cloud, comme les derniers produits de notre plateforme, même s’il est possible avec certains produits de déporter le traitement sur site avec les remote engines sans sortir les données des centres de données », explique le responsable marketing de Talend. « Nous avons une forte demande des clients de placer Data Inventory au niveau du remote engine. Cette fonctionnalité arrivera sûrement l’année prochaine », annonce-t-il.
Si tel est le cas, il faudra spécifier encore une fois la différence entre Data Inventory et l’offre Data Catalog. En mars dernier, cette segmentation des produits sur site et dans le cloud avait provoqué une légère confusion.