SLM : New Relic rattrape son retard pour répondre aux besoins des SRE
Une mise à jour de New Relic cette semaine reflète le rôle crucial des SRE dans le maintien en condition opérationnelle des microservices. L’éditeur prévoit également de s’aligner sur les ambitions DevSecOps de ses concurrents.
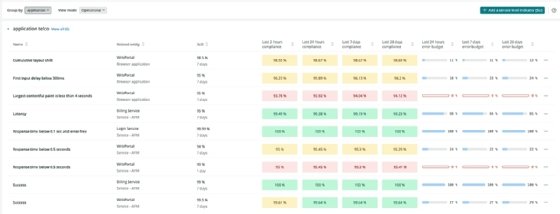
La gestion des niveaux de service (SLM), une nouvelle fonctionnalité de la plateforme New Relic One, a été rendue disponible gratuitement cette semaine pour les clients existants. Elle fournit un framework permettant aux équipes d’ingénierie de la fiabilité des sites (SRE) de configurer des indicateurs de niveau de service (SLI) et des objectifs de niveau de service (SLO), de définir automatiquement des lignes de base et de suivre la fiabilité des microservices en fonction de ces indicateurs de performance.
Selon les bêta-testeurs de New Relic SLM, la mise à jour parue cette semaine reflète la façon dont la transition vers une architecture de microservices a élargi le rôle joué par les outils d’observabilité et les SRE dans leurs entreprises.
En fin de compte, l’apport de plusieurs types de monitoring et de métriques pour capturer l’expérience de l’usager, plutôt que de surveiller les mesures brutes des composants d’infrastructure individuels, différencie le suivi des microservices des monolithes, l’observabilité du monitoring, et les SRE des administrateurs système traditionnels, d’après un utilisateur de New Relic SLM.
« L’observabilité nous aide à comprendre l’état d’un système distribué en examinant toutes les données qu’il génère, et pas seulement les [ressources] individuelles. »
Andrew MyersResponsable SRE senior, Zip.co
« Le monitoring est très pratique lorsque les modes de défaillance sont maîtrisés, par exemple l’épuisement de ressources IT finies comme la mémoire ou les threads », explique Andrew Myers, responsable SRE senior chez Zip.co, une société australienne de paiements en ligne. « L’observabilité nous aide à comprendre l’état d’un système distribué en examinant toutes les données qu’il génère, et pas seulement les [ressources] individuelles ».
Les SRE et l’observabilité créent l’harmonie à partir du chaos
À titre d’exemple, les SRE ont joué le rôle de facilitateur au fur et à mesure que les microservices se sont imposés chez Achievers, un éditeur d’une plateforme consacrée à l’engagement des employés basé à Toronto. Pour cela, les SRE ont créé une pile d’observabilité centralisée avec New Relic afin d’orchestrer la communication entre les développeurs, les ingénieurs et les équipes produits. En ce sens, Achievers est l’un des early adopters de l’option SLM.
« Dans un environnement monolithique, la fiabilité ne concernait que l’équipe SRE – nous étions les seuls à nous soucier des problèmes de production », explique Stefan Kolesnikowicz, responsable SRE chez Achievers.
À mesure que la culture d’Achievers et les déploiements de microservices sur Google Cloud Platform se sont développés, « tout le monde est devenu responsable de la fiabilité », poursuit-il. La nature distribuée des microservices, par définition, impose une collaboration entre les équipes qui les développent et les administrent, et leur complexité ne peut être gérée par une seule équipe.
L’équipe SRE d’Achievers a créé un portail en libre-service pour les développeurs, appelé Abattoir, en clin d’œil à l’analogie souvent citée « bétail contre animaux domestiques » qui s’est produite avec l’infrastructure hautement automatisée et éphémère qui sous-tend les environnements de microservices en évolution rapide.
New Relic SLM s’insérera dans Abattoir pour permettre aux ingénieurs logiciels et aux équipes produits de configurer et de suivre les SLI et SLO pour les services qu’ils gèrent. Cette intégration reposera sur une nouvelle intégration avec Terraform, qui crée automatiquement des objets dans la base de données d’observabilité de New Relic en coulisse.
« Nous avons une case à cocher pour cela – en gros, les ingénieurs disent simplement “Oui, j’accepte” », résume Stefan Kolesnikowicz. « Toutes ces instructions sont ensuite traduites à partir d’un fichier YAML et poussées par Terraform, [qui] parle à l’API de New Relic, pour créer tous les objets nécessaires ».
Cette approche reflète la façon dont la fiabilité du système est passée en tête de la liste des priorités chez Achievers, assure le responsable SRE, comme c’est le cas dans de nombreuses entreprises avec la généralisation des microservices.
« Nous essayons d’être plus stricts. Si le budget d’erreur s’amoindrit, cela devient notre priorité », explique Stefan Kolesnikowicz. Pour rappel, un budget d’erreur est la durée maximale pendant laquelle un SI peut-être hors service sans conséquences juridiques pour son mainteneur. « Nous devons assurer la fiabilité de la plateforme avant d’introduire de nouvelles fonctionnalités », poursuit-il. « [New Relic SLM] va nous donner un meilleur aperçu de la performance d’un système et de son impact sur le reste de la plateforme, et les intégrations avec le produit permettront aux équipes d’évaluer précisément leur budget d’erreur ».
SLI/SLO : les SRE établissent leur liste de souhaits
New Relic SLM est un framework pour configurer les métriques SLI et SLO.
Toutefois, New Relic SLM n’est pas parfait. Les premiers usagers de l’outil aimeraient que des alertes intégrées autour des budgets d’erreur soient ajoutées dans une prochaine version. Ils peuvent utiliser le langage de requête de New Relic pour configurer des alertes personnalisées, lorsque les taux d’épuisement du budget d’erreur atteignent certains seuils, mais il serait plus facile si cette alerte était préintégrée à SLM.
« Ce serait également formidable d’avoir des outils intelligents pour aider les équipes à décider d’objectifs réalistes pour les niveaux de service, sur la base des données historiques dont nous disposons comme référence », souligne Andrew Myers de Zip.co. « C’est un point sur lequel nous avons dû former nos équipes en interne ».
Un autre réajustement potentiel pour SLM à l’avenir serait une prise en charge étendue des métriques Prometheus qu’Achievers surveille dans ses clusters Kubernetes individuels via le maillage de services Istio, selon Stefan Kolesnikowicz. New Relic One agrège déjà les métriques Prometheus pour d’autres utilisations, mais cela n’a pas encore été intégré à SLM.
« Si vous êtes familier avec le “livre SRE”, [il dit] que vous pouvez rapprocher les mesures de l’utilisateur pour améliorer leur qualité », affirme-t-il faisant référence au manuel fondateur de Google Site Reliability Engineering. « Aujourd’hui, nous mesurons [les SLI] du côté du serveur – nous voulons les mesurer sur l’équilibreur de charge, qui serait dans notre instance Istio ».
Les taux d’épuisement du budget d’erreur et la prise en charge des métriques Prometheus figurent tous deux sur la feuille de route à court terme selon un porte-parole de l’éditeur.
Les outils d’observabilité entrent dans une phase de consolidation brutale
Tout comme Achievers, certaines entreprises ont commencé à consolider les outils d’observabilité avec New Relic, en ajoutant les logs et les traces distribuées aux outils traditionnels de supervision des performances des applications (APM) de New Relic au fur et à mesure de leur évolution ; ainsi que les métriques et l’agrégation de données provenant d’outils tiers tels que Prometheus, et en éliminant progressivement les outils concurrents tels que Splunk et Grafana en conséquence.
Cependant, certaines organisations font des choix de consolidation qui favorisent d’autres éditeurs. New Relic tente de rattraper son retard : deux de ses principaux concurrents, Dynatrace et Datadog, disposent de fonctionnalités de surveillance SLI et SLO depuis 2020 et 2019, respectivement.
Les concurrents couvrent également une catégorie entière de supervision dans la sécurité IT et DevSecOps que New Relic n’a pas encore abordée. Le marché de l’observabilité est mûr pour de nouvelles attritions et consolidations, car les équipes IT continuent de réduire le nombre d’outils de gestion informatique qu’elles utilisent, dont ceux nécessaires à la sécurité. Et New Relic doit suivre le rythme des compétiteurs, y compris ceux actifs sur le segment du SIEM, pour réussir à long terme.
Selon un de ses porte-parole, New Relic prévoit également d’annoncer une offre de sécurité cette année, mais ne donne pas plus de détails. FutureStack, la conférence annuelle de l’éditeur, est programmée en mai et est généralement le théâtre de dévoilement de nouveaux produits.
« [L’ajout d’outils de sécurité des applications] serait judicieux puisque New Relic cible davantage le cycle de vie de livraison des logiciels et les développeurs », déclare Stephen Elliot, analyste chez IDC. « L’analyse du code est un domaine intéressant, tout comme les évaluations de vulnérabilité ».
New Relic a subi un grand chamboulement en mai 2021, lorsqu’il a nommé un nouveau PDG et remanié son portefeuille de produits pour créer New Relic One, une plateforme d’observabilité unifiée. Selon le dernier rapport sur les résultats de l’entreprise, son chiffre d’affaires n’a cessé de croître depuis lors, avec 14 600 clients au troisième trimestre fiscal, qui s’est terminé en janvier.
Cependant, alors qu’il subit le dilemme de l’innovateur, qui provoque également des turbulences pour Splunk et ServiceNow, New Relic n’a pas encore retrouvé la rentabilité. L’entreprise prévoit des revenus relativement stables pour son quatrième trimestre fiscal et ne s’attend pas à être dans le vert avant la fin de l’exercice 2023.
Pour approfondir sur Administration et supervision du Cloud