
somartin - Fotolia
Qwen3.6-Plus : nouveau fer de lance d’Alibaba dans les IA qui codent
Alibaba lance une nouvelle version de son LLM qui met l’accent sur le codage. Des benchmarks mettent Qwen3.6-Plus devant ses concurrents chinois et au coude à coude avec les modèles haut de gamme Opus 4.5 d’Anthropic et Gemini 3 Pro de Google.

Avec Qwen3.6-Plus, Alibaba se repositionne dans la course de l’IA agentique appliquée au développement logiciel.
Son dernier modèle en date sait décomposer un objectif, comprendre une documentation, gérer des dépôts de code, planifier des tâches, et même comprendre un dessin ou une vidéo pour générer un front-end et du code fonctionnel. C’est en tout cas la promesse d’Alibaba.
Un des atouts de ce modèle est son énorme fenêtre de contexte qui atteint un million de tokens (moins que Kimi, mais quasiment autant que Gemini 3 Pro).
Qwen3.6-Plus intègre également des fonctions de raisonnement multimodal.
Qwen3.6-Plus vs Claude Opus 4.5 et Gemini 3 Pro
Pour prouver la performance de Qwen3.6-Plus, Alibaba a publié une douzaine de benchmarks où le nouveau modèle est comparé à Kimi K2.5 (réputé pour sa fenêtre de contexte de 2 millions de tokens), GLM5 (son autre concurrent direct en Chine), le modèle haut de gamme d’Anthropic, Opus 4.5, et à un des modèles les plus récents de Google, Gemini 3 Pro.
Ces benchmarks montrent que la volonté d’Alibaba n’est pas simplement de générer du code, mais plutôt de comprendre un problème, de modifier un dépôt, d’exécuter des tests et de corriger des erreurs. Bref, de prendre en charge la totalité du cycle de développement.
Sur la capacité d’un agent à interagir avec un terminal (Terminal-Bench), Qwen3.6-Plus dépasserait d’une courte tête Opus 4.5 et largement GLM5 et Kimi. Pour la résolution de problèmes issus de dépôts GitHub, il rivalise avec Opus, mais cette fois-ci c’est le modèle de Claude qui reste légèrement meilleur, plus encore dans un contexte multilingue.
Claude mène également la danse dans la gestion de tâches successives (Claw-Eval (pass@3)), mais Qwen3.6-Plus reste bien devant ses compétiteurs chinois. Il serait même loin devant tout le monde sur un autre benchmark, mais interne, ce qui limite la pertinence de cette évaluation. Sur la recherche internet (Elo Rating), Alibaba et Anthropic sont encore au coude à coude. En revanche, sur NL2Repo (capacité à suivre un objectif complexe en plusieurs étapes avec un grand nombre de fichiers), le modèle est distancé par Claude.
Une synthèse des points forts d’Opus et de Gemini 3 Pro
Sur les tâches multimodales et documentaires, les résultats sont plus en faveur de Qwen que de Claude… mais cette fois-ci, c’est Google qui domine d’un cheveu, que ce soit sur MMMU (un benchmark de raisonnement multimodal), sur RealWorldQA (compréhension d’images dans des contextes réels), ou sur Video-MME (raisonnement sur et à partir d’une vidéo)
En revanche, dans la compréhension de documents complexes (OmniDocBench), Qwen3.6-Plus affiche, de loin, le meilleur score de tout le panel.
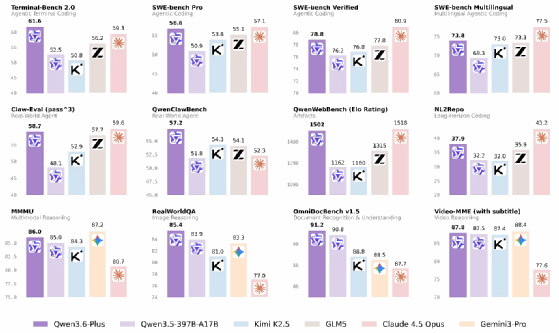
Au global, les résultats montrent donc un modèle compétitif, qui synthétise les points forts d’Opus 4.5 et ceux de Gemini 3 Pro.
Mais comme souvent avec ce type d’évaluation, plusieurs limites doivent être prises en compte. Les conditions de test, par exemple, ne sont pas détaillées. Et les écarts restent souvent faibles.
Une intégration dans l’écosystème Alibaba Cloud
Qwen3.6-Plus va être intégré à plusieurs services du groupe chinois. Il sera utilisé dans Wukong, la plateforme destinée à automatiser des tâches métiers, ainsi que dans Qwen App, l’application IA d’Alibaba.
Le modèle sera accessible via Model Studio, la plateforme de développement d’Alibaba Cloud. Il sera également compatible avec des outils tiers comme Claude Code, Cline ou OpenClaw.
Certaines versions seront partagées en open source / open weight, mais Alibaba n’a pas encore précisé lesquelles, ni quand, ni sous quelles conditions.
Plus largement, ce nouveau modèle montre encore, s'il en était besoin, que les acteurs chinois n'ont rien à envier, ou de moins en moins, aux géants américains du secteur.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
Fable 5 : Anthropic place Mythos sous contrôle
Par: Gaétan Raoul
-
![]()
LLM : pour s’émanciper d’Anthropic et d’OpenAI, Microsoft lance la famille de modèles MAI
Par: Gaétan Raoul
-
![]()
LLM gourmands, demande forte et IPO en vue : Anthropic lève 65 milliards de dollars
Par: Gaétan Raoul
-
![]()
Gemini 3.5 Flash est rapide, mais pas aussi intéressant que l’affirme Google
Par: Gaétan Raoul



