Maridav - stock.adobe.com
L’Équipe utilise l'IA pour générer un podcast
En 2024, le célèbre quotidien sportif a généré chaque jour des JO de Paris un podcast de 2 minutes avec deux IA (Claude et ElevenLabs), en partenariat avec Devoteams et AWS. Résultat, un podcast sans « hallucination » et avec un niveau d’audience similaires à ceux faits par des humains lors des JO de Tokyo.

Pour un organisateur d’événements sportifs comme ASO, l’Intelligence artificielle est une opportunité de transformation. Aussi bien pour ses activités d’événements sportifs, comme avec le Marathon de Paris, que pour son activité média du groupe Amaury.
Le célèbre quotidien sportif de référence l’Équipe, en a été le parfait exemple, il y a tout juste un an, lors des JO de Paris 2024.
Un podcast de 2 minutes généré par des IA
L’Équipe a ainsi eu recours à plusieurs l’IA générative et à l’ESN Devoteam et à son département SporTech, pour créer quotidiennement et de manière automatisée, un podcast (« 2 minutes chrono ») lors des JO de Paris 2024.
Les détails techniques du projet étaient présentés au printemps lors d’une conférence intitulée « L’IA, nouveau coach invisible au service du haut niveau ».
Le projet a été mené « en moins de 30 jours » et « dans l’urgence » compte tenu des délais serrés, déclare Erwan Benech, consultant Devoteam – par ailleurs ancien champion de France de 800 m et 1500 m. La réalisation n’en demeurait pas moins complexe, insiste l’expert, qui cite plusieurs défis techniques.
« Le premier enjeu a été de faire comprendre à l’IA qui sont les athlètes français, quelles sont les performances remarquables, le tableau des médailles et la manière de prioriser les informations à intégrer dans le podcast » au sein d’une chaîne de production entièrement automatisée.
Le développement de l’application a débuté par du scraping de données – ici les contenus et informations créés par les journalistes de L’Equipe, en toute légalité donc. Un système de scoring a ensuite été défini en parallèle pour prioriser les faits en attribuant à chacun un score.
Les événements avec les scores les plus élevés ont ainsi été retenus pour un podcast qui a été écouté en moyenne par 3000 auditeurs chaque jour.
L’humain n’a cependant pas été exclu de la boucle puisque chaque podcast a été dans un premier temps généré au format texte (avec Claude d’Anthropic) – un script revu pour respecter la durée de 2 minutes et validé par la rédaction en chef.
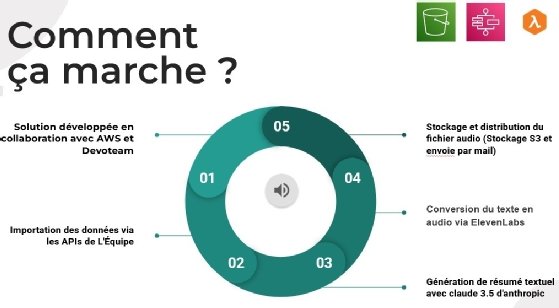
Scrapping et scoring des contenus des journalistes
Du côté des données, lorsqu’un article publié était consacré aux Jeux olympiques, l’ensemble de la page Web était scrappée et stockée sur une base de données dans le cloud (AWS). « Nous avions prompté l’IA pour qu’elle réalise un résumé en fonction du scoring. »
Une voix de synthèse – fine-tunée pour parvenir au ton voulu (avec ElevenLabs) – a été ensuite appliquée pour lire le texte final avant transfert sur les services de streaming et de L’Equipe pour diffusion.
Le bilan ressemble à une victoire pour l’Equipe. Le podcast a connu un score d’audience comparable à celui d’un podcast similaire réalisé par des humains lors des JO de Tokyo.
Une aubaine pour réduire la masse salariale ? Erwan Benech assure que non. Il insiste : la création du contenu n’était possible qu’avec les articles rédigés par les journalistes de L’Equipe. « Sans l’intelligence de base, nous n’aurions pas pu mener le projet », tranche-t-il.
Interrogé par LeMagIT, le consultant précise qu’aucune hallucination n’a été à déplorer. « Les hallucinations arrivent généralement lorsqu’il y a énormément de données […] Quand on en a trop, on multiplie les risques d’erreurs. Tous les jours, nous procédions à un reset de la base de données. Nous avions ainsi un contrôle sur sa taille », explique-t-il.
« Sur un projet de plus grande envergure, peut-être aurions-nous été obligés de penser une autre architecture pour effectuer du fact-checking, par exemple en ajoutant un agent IA dont le rôle aurait été de contrôler l’information via des sources ouvertes autres que L’Equipe », conclut-il.
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
Acrobat génère des présentations et des podcasts
Par: Philippe Ducellier
-
![]()
PDF : Acrobat évolue en « espaces » créatifs dopés à l’IA
Par: Philippe Ducellier
-
![]()
Comment Canal+ diffuse et supervise les grands matchs à l’international
Par: Gaétan Raoul
-
![]()
Sportifs et dirigeants de club : cap sur la Data et l’IA
Par: Christophe Auffray