NoSQL (base de données « Not Only SQL »)
Qu'est-ce qu'une base de données NoSQL ?
NoSQL est une approche de la gestion des bases de données qui peut s'adapter à une grande variété de modèles de données, y compris les formats clé-valeur, document, colonne et graphique. Une base de données NoSQL signifie généralement qu'elle est non relationnelle, distribuée, flexible et évolutive. Parmi les autres caractéristiques communes aux bases de données NoSQL figurent l'absence de schéma de base de données, le regroupement des données, la prise en charge de la réplication et la cohérence éventuelle, par opposition à la cohérence transactionnelle ACID (atomicité, cohérence, isolation et durabilité) typique des bases de données relationnelles et SQL. De nombreux systèmes de bases de données NoSQL sont également open source.
À l'origine, le terme NoSQL pouvait être pris au pied de la lettre, c'est-à-dire que SQL n'était pas utilisé comme API pour accéder aux données. Cependant, l'omniprésence et l'utilité de SQL ont poussé de nombreuses bases de données NoSQL à ajouter la prise en charge de SQL. Aujourd'hui, il est communément admis que NoSQL signifie "Not Only SQL" (pas seulement SQL).
Quels sont les types de bases de données NoSQL ?
Il existe quatre types populaires de systèmes de bases de données NoSQL. Chacun d'entre eux utilise un modèle de données différent, ce qui entraîne des différences significatives entre chaque type de base de données NoSQL.
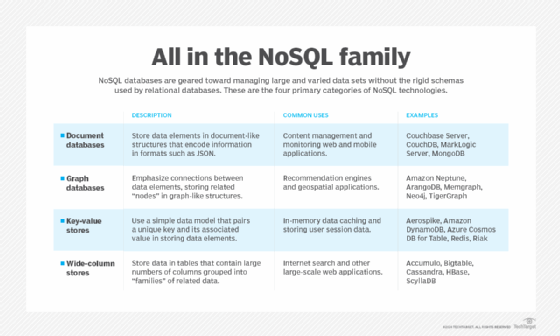
Bases de données documentaires. Également appelées magasins de documents, ces bases de données stockent des données semi-structurées et des descriptions de ces données sous forme de documents. Elles permettent aux développeurs de créer et de mettre à jour des programmes sans avoir à se référer à un schéma principal. L'utilisation des bases de données documentaires s'est développée parallèlement à l'utilisation de JavaScript et de JavaScript Object Notation (JSON), un format d'échange de données qui s'est imposé parmi les développeurs d'applications web. Les bases de données documentaires sont utilisées pour la gestion du contenu et le traitement des données des applications mobiles, telles que les plateformes de blogs, les analyses web et les applications de commerce électronique. Couchbase Server, CouchDB, MarkLogic et MongoDB sont des exemples de bases de données documentaires.
Bases de données graphiques. Les magasins de données graphiques organisent les données sous forme de nœuds, qui sont similaires aux lignes d'une base de données relationnelle, et d'arêtes, qui représentent les connexions entre les nœuds. Comme le système graphique stocke la relation entre les nœuds, il peut prendre en charge des représentations plus riches des relations entre les données. En outre, contrairement aux modèles relationnels qui reposent sur des schémas stricts, le modèle de données graphique peut évoluer au fil du temps et de l'utilisation. Les bases de données graphiques sont utilisées dans les systèmes qui doivent cartographier les relations, tels que les plateformes de médias sociaux, les systèmes de réservation ou la gestion des relations avec les clients. AllegroGraph, IBM Graph et Neo4j sont des exemples de bases de données graphiques.
Les magasins clé-valeur. Également connus sous le nom de bases de données clé-valeur, ces systèmes mettent en œuvre un modèle de données simple qui associe une clé unique à une valeur associée. Ce modèle étant simple, il peut être utilisé pour développer des applications hautement évolutives et performantes. Les bases de données clé-valeur sont idéales pour la gestion des sessions et la mise en cache dans les applications web, telles que celles nécessaires pour gérer les détails du panier d'achat des acheteurs en ligne ou pour gérer les détails de la session pour les jeux multijoueurs. Les implémentations diffèrent dans la manière dont elles sont orientées pour fonctionner avec la mémoire vive, les lecteurs à semi-conducteurs ou les lecteurs de disques. Aerospike, DynamoDB, Redis et Riak sont des exemples de bases de données clés-valeurs populaires.
Les magasins à colonnes multiples. Ces bases de données utilisent des tables, des colonnes et des lignes familières comme les tables des bases de données relationnelles, mais les noms et le formatage des colonnes peuvent différer d'une ligne à l'autre dans une même table. Chaque colonne est également stockée séparément sur le disque. Contrairement au stockage traditionnel axé sur les lignes, un magasin à colonnes multiples est optimal lorsqu'il s'agit d'interroger des données par colonnes. Les moteurs de recommandation, les catalogues, la détection des fraudes et l'enregistrement des événements sont autant d'applications typiques dans lesquelles les magasins à colonnes multiples peuvent exceller. Accumulo, Amazon SimpleDB, Cassandra, HBase et Hypertable sont des exemples de magasins à colonnes larges.
Ces classifications de base des bases de données NoSQL ne sont que des guides. Au fil du temps, les fournisseurs ont mélangé et associé des éléments de différentes familles de bases de données NoSQL pour obtenir des systèmes plus généralement utiles. Cette évolution est visible, par exemple, chez MarkLogic, qui a ajouté un magasin de graphes et d'autres éléments à ses bases de données documentaires d'origine. Couchbase Server prend en charge les approches clé-valeur et document. Cassandra a combiné des éléments clé-valeur avec un magasin à colonnes multiples et une base de données graphique. Parfois, des éléments NoSQL sont mélangés à des éléments SQL, créant ainsi une variété de bases de données appelées bases de données multimodèles.
Avantages de NoSQL
L'utilisation des bases de données NoSQL présente plusieurs avantages, notamment
- Les bases de données NoSQL simplifient le développement d'applications, en particulier pour les applications web interactives en temps réel, telles que celles qui utilisent une API REST et des services web.
- Ces bases de données offrent une certaine flexibilité pour les données qui n'ont pas été normalisées, qui nécessitent un modèle de données flexible ou qui ont des propriétés différentes pour les différentes entités de données.
- Ils offrent une évolutivité pour les ensembles de données plus importants, qui sont courants dans les applications d'analyse et d'intelligence artificielle (IA).
- Les bases de données NoSQL sont mieux adaptées aux besoins en matière d'informatique dématérialisée, de téléphonie mobile, de médias sociaux et de big data.
- Elles sont conçues pour des cas d'utilisation spécifiques et sont plus faciles à utiliser que les bases de données relationnelles ou SQL générales pour ces types d'applications.
Inconvénients de NoSQL
Les inconvénients de l'utilisation d'une base de données NoSQL sont les suivants :
- Chaque base de données NoSQL possède sa propre syntaxe pour l'interrogation et la gestion des données. Cela contraste avec SQL, qui est la lingua franca des systèmes de bases de données relationnelles et SQL.
- L'absence d'un schéma de base de données rigide et de contraintes supprime les garanties d'intégrité des données qui sont intégrées dans les systèmes de bases de données relationnelles et SQL.
- Un schéma avec une certaine structure est nécessaire pour utiliser les données. Avec NoSQL, cette tâche doit être effectuée par le développeur de l'application plutôt que par l'administrateur de la base de données.
- Étant donné que la plupart des bases de données NoSQL utilisent le modèle de cohérence éventuelle, elles n'offrent pas le même niveau de cohérence des données que les bases de données SQL. Il arrive que les données ne soient pas cohérentes, ce qui signifie qu'elles ne sont pas adaptées aux transactions nécessitant une intégrité immédiate, telles que les transactions bancaires et les transactions aux guichets automatiques.
- Les bases de données NoSQL étant plus récentes, il n'existe pas de normes industrielles complètes comme c'est le cas pour les offres de SGBD relationnels et SQL.
NoSQL vs. SQL : Quelle est la différence ?
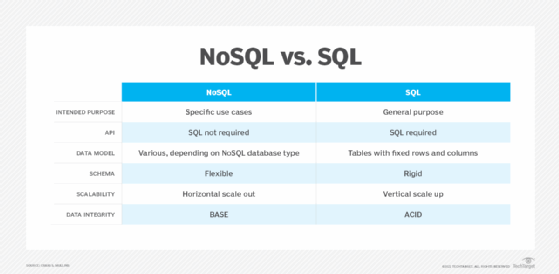
À un niveau élevé, les bases de données SQL sont d'usage général, tandis que les bases de données NoSQL sont conçues pour des cas d'utilisation spécifiques. Les principales différences entre les bases de données NoSQL et SQL peuvent être résumées dans les cinq catégories suivantes : API, modèle de données, exigences en matière de schéma, évolutivité et intégrité des données. Chacune déploie une approche différente de ces aspects du stockage et de la récupération des données.
API. Pour les bases de données NoSQL, SQL n'est pas nécessaire en tant qu'API pour les données de la base, bien que de nombreuses bases de données NoSQL proposent un langage d'interrogation de type SQL. Pour les bases de données SQL, SQL est généralement la seule interface, ou l'interface prédominante, avec les données.
Modèle de données. Avec les systèmes de base de données NoSQL, les données ne sont pas modélisées sous forme de tables avec des lignes et des colonnes fixes, comme avec un SGBD SQL. En revanche, selon la base de données NoSQL, les données peuvent être modélisées sous forme de documents JSON, de graphes avec des nœuds et des arêtes, ou de paires clé-valeur. Les magasins à colonnes multiples utilisent le concept de table et de ligne, mais les colonnes peuvent être dynamiques d'une ligne à l'autre au sein d'une table.
Schéma. Le schéma d'une base de données NoSQL est flexible, ce qui signifie qu'il n'y a pas de structure fixe pour les données, les types de données et les longueurs des éléments de données. Les données peuvent être stockées sous une forme libre, ou sans schéma. Cette approche offre aux programmeurs une plus grande flexibilité, ce qui peut faciliter les efforts de développement.
Avec SQL, les bases de données, le schéma est fixe, avec des types de données et des longueurs rigides pour chaque colonne, et chaque ligne doit correspondre à la disposition et à la structure définies de la colonne. Par exemple, si une colonne est définie comme un nombre entier, seules des données entières peuvent être stockées dans la colonne et toute tentative de faire autrement est rejetée par le SGBD. Cette approche permet d'améliorer la qualité des données, car le SGBD applique les règles au fur et à mesure que des données sont ajoutées.
Évolutivité. Les bases de données NoSQL mettent généralement en œuvre une mise à l'échelle horizontale, également connue sous le nom de "scaling out". La mise à l'échelle implique l'ajout de matériel à un système, généralement sous la forme de nouveaux serveurs de base. Les systèmes NoSQL utilisent fréquemment le partitionnement horizontal, qui consiste à diviser les grandes bases de données en éléments plus petits répartis sur plusieurs serveurs, à l'aide du sharding.
L'approche SQL est typiquement la mise à l'échelle verticale, également appelée mise à l'échelle supérieure. Dans ce cas, des ressources supplémentaires sont ajoutées, telles qu'une unité centrale plus puissante ou de la mémoire supplémentaire, afin de gérer une charge de travail supplémentaire ou d'améliorer les performances.
Intégrité des données. Les bases de données NoSQL et SQL utilisent des approches différentes pour protéger l'intégrité des données lorsqu'elles sont créées, lues, mises à jour et supprimées par les applications et les utilisateurs.
La plupart des systèmes de bases de données NoSQL gèrent l'intégrité des données selon une approche connue sous le nom de BASE (Basically Available, Soft State with Eventual Consistency). Avec l'approche BASE, les données peuvent être incohérentes pendant un certain temps, mais la réplication de la base de données finit par mettre à jour toutes les copies des données pour qu'elles soient cohérentes. Certaines applications peuvent tolérer ce type de données incohérentes, d'autres non.
L'approche utilisée par les bases de données SQL est l'approche ACID susmentionnée. Chacune de ses quatre qualités - atomicité, cohérence, isolation et durabilité - contribue à la capacité d'une transaction à garantir l'intégrité des données. Grâce à l'ACID, chaque transaction, lorsqu'elle est exécutée seule, dans un état cohérent de la base de données, peut soit s'achever et produire des résultats corrects, soit se terminer sans effet. Dans les deux cas, l'état de la base de données qui en résultera sera toujours un état cohérent.
Évolution de NoSQL
Le langage SQL et les systèmes de bases de données relationnelles sont omniprésents parce qu'ils offrent un bon mécanisme à usage général pour répondre à la plupart des exigences en matière de gestion des données. Ils sont conçus pour être fiables, précis et utiles pour les applications planifiées et les requêtes ad hoc. Néanmoins, certaines exigences SQL et relationnelles - par exemple, un schéma rigide et une ACID stricte - peuvent les rendre moins adaptées aux applications qui nécessitent des données flexibles et une grande rapidité.
En réaction, des systèmes de base de données NoSQL ont vu le jour pour répondre à ces besoins, nombre d'entre eux ayant été développés par des entreprises telles qu'Amazon avec son DynamoDB, Facebook avec son Apache Cassandra, et Google avec sa base de données BigTable pour répondre à leurs besoins spécifiques. Un autre système de base de données NoSQL influent est Berkeley DB, développé à l'Université de Californie, Berkeley, au début des années 1990, Berkeley DB a été largement décrit comme une base de données intégrée qui répondait étroitement aux besoins de stockage d'applications spécifiques. Ce logiciel à code source ouvert fournissait un simple magasin clé-valeur. Berkeley DB a été commercialisé par Sleepycat Software en 1999. La société a ensuite été rachetée par Oracle en 2006. Oracle a continué à soutenir le logiciel libre Berkeley DB.
Le terme NoSQL peut s'appliquer à certaines bases de données antérieures au système de gestion de bases de données relationnelles (SGBDR), mais il fait plus communément référence aux bases de données construites au début des années 2000 dans le but de regrouper des bases de données à grande échelle dans des applications cloud (en mode SaaS) et des applications web.






