Qu'est-ce que la génération augmentée par récupération (RAG) dans l'IA ?

La génération augmentée par récupération (RAG) est un cadre d’IA qui récupère des données à partir de sources de connaissances externes afin d’améliorer la qualité des réponses. Cette technique de traitement du langage naturel (NLP) est couramment utilisée pour rendre les grands modèles de langage (LLM) plus précis et plus actuels.
Les LLM sont des modèles d’IA qui alimentent des chatbots tels que ChatGPT d’OpenAI et Google Gemini. Les LLM peuvent comprendre, résumer, générer et prédire de nouveaux contenus. Cependant, ils peuvent encore être incohérents et échouer dans certaines tâches à forte intensité de connaissances, en particulier celles qui se situent en dehors de leurs données d’apprentissage initiales ou celles qui nécessitent des informations actualisées et de la transparence sur la manière dont ils prennent leurs décisions. Dans ce cas, le LLM peut renvoyer de fausses informations, également connues sous le nom d’hallucinations de l’IA.
Lorsque les données entraînées d’un LLM ne sont pas suffisantes, la qualité de ses réponses peut être améliorée en récupérant des informations de sources externes. La récupération d’informations à partir d’une source en ligne, par exemple, permet au LLM d’accéder à des informations actuelles sur lesquelles il n’a pas été formé au départ. Ce processus est devenu important pour les modèles d’IA de base, les chatbots et les systèmes de questions-réponses, car ils doivent répondre aux demandes des utilisateurs avec des informations spécifiques, actualisées et précises.
Que fait le RAG et pourquoi est-il important ?
Les LLM sont un élément clé des systèmes d’IA modernes, car ils permettent à l’IA de comprendre et de générer le langage humain. Cependant, les LLM présentent plusieurs contraintes et lacunes en matière de connaissances. Ils sont généralement formés hors ligne, ce qui fait que le modèle ne connaît pas les données créées après sa formation. Le RAG récupère des données en dehors du LLM, ce qui permet d’enrichir la réponse du LLM en ajoutant les données pertinentes récupérées à la réponse générative.
Ce processus permet de réduire les lacunes apparentes en matière de connaissances et les hallucinations liées à l’IA. C’est important dans les domaines qui requièrent des informations aussi actuelles et précises que possible, comme les soins de santé et l’assistance à la clientèle.
Comment utiliser le RAG avec les LLM
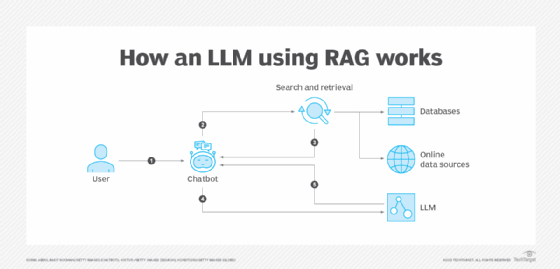
RAG combine un modèle de génération de texte avec une composante de recherche d’informations. Cette composante recherche des connaissances externes, c’est-à-dire des données recueillies à partir de n’importe quel endroit en dehors des données d’apprentissage originales du LLM. Les informations peuvent être extraites de différents endroits, tels que des sources en ligne, des interfaces de programmation d’applications, des bases de données et des dépôts de documents.
Si l’on prend l’exemple d’un chatbot, une fois que l’utilisateur a saisi un message, RAG résume ce message à l’aide d’incrustations vectorielles – qui sont généralement gérées dans des bases de données vectorielles – de mots-clés ou de données sémantiques. Les données converties sont envoyées à une plateforme de recherche pour récupérer les données demandées, qui sont ensuite triées en fonction de leur pertinence.
Le LLM synthétise ensuite les données récupérées avec l’invite augmentée et ses données de formation internes pour créer une réponse générée qui peut être transmise au chatbot. En fonction du chatbot, des liens peuvent également être fournis à l’utilisateur.
Quels sont les avantages du RAG ?
RAG offre les avantages suivants :
- Fournit des informations actualisées. Le RAG tire ses informations de sources pertinentes, fiables et actualisées.
- Accroître la confiance des utilisateurs. Selon la mise en œuvre de l’IA, les utilisateurs peuvent accéder aux sources du modèle, ce qui favorise la transparence et la confiance dans le contenu et permet aux utilisateurs d’en vérifier l’exactitude.
- Réduit les hallucinations de l’IA. Comme les LLM sont liés à des données externes, le modèle a moins de chances d’inventer ou de renvoyer des informations incorrectes.
- Réduction des coûts informatiques et financiers. Les organisations n’ont pas besoin de consacrer du temps et des ressources à l’entraînement continu du modèle sur de nouvelles données.
- Synthèse des informations. Le RAG synthétise les données en combinant les informations pertinentes issues de la recherche et des modèles génératifs pour produire une réponse.
- Plus facile à former. Comme le RAG utilise des sources de connaissances récupérées, la nécessité de former le LLM sur une quantité massive de données est réduite.
- Peut être utilisé pour des tâches multiples. Outre les chatbots, RAG peut être adapté à divers cas d’utilisation spécifiques, tels que les systèmes de résumé de texte et de dialogue.
Quelles sont les limites du RAG ?
Si le système RAG présente de nombreux avantages, il s’accompagne également de défis et de limites, notamment les suivants :
- Précision et qualité des données. Étant donné que le RAG s’appuie sur des sources externes, l’exactitude de sa réponse dépend de la qualité des données qu’il utilise. Le RAG ne peut pas déterminer lui-même l’exactitude des données qu’il recueille. Cela signifie que l’exactitude des données extraites dépend de la qualité et de la fiabilité des sources de données.
- Coût informatique. RAG nécessite un modèle et une composante d’extraction capables d’intégrer efficacement les données extraites, ce qui est un processus à forte intensité de ressources.
- Explicabilité. Certains systèmes peuvent ne pas être conçus pour permettre aux utilisateurs de savoir d’où proviennent les données, ce qui peut affecter la confiance des utilisateurs.
- Temps de latence. L’ajout d’une étape de recherche à un LLM peut augmenter sa latence. Cela est particulièrement vrai si le mécanisme de recherche doit parcourir des bases de connaissances plus importantes.
Recherche par génération augmentée vs recherche sémantique
La recherche sémantique est une technique de recherche de données qui se concentre sur la compréhension de l’intention et des significations contextuelles des requêtes de recherche. Pour ce faire, elle applique des algorithmes de NLP et d’apprentissage automatique à divers facteurs, tels que les termes utilisés dans une requête, les recherches précédentes et la localisation géographique. Cette méthode est plus efficace que les recherches basées sur des mots-clés, qui tentent de correspondre aux mots ou phrases exacts d’une requête. La recherche sémantique est largement utilisée dans les moteurs de recherche web, les systèmes de gestion de contenu, les chatbots et les plateformes de commerce électronique.
Alors que le RAG tente d’améliorer la qualité des réponses d’un LLM en utilisant des données externes, la recherche sémantique se concentre plutôt sur l’amélioration de la précision de la recherche en comprenant la requête de recherche et l’intention qui la sous-tend.
Ces deux types de recherche peuvent avoir des objectifs complémentaires. La recherche sémantique peut améliorer la qualité des requêtes basées sur les RAG, car elle se concentre sur une compréhension plus approfondie des recherches. Les systèmes RAG produisent ainsi des résultats plus précis et plus significatifs.
La recherche sémantique est quant à elle idéale pour les applications où il est primordial de comprendre l’intention de l’utilisateur afin d’améliorer la précision de la recherche.
Histoire du RAG
Au début des années 1970, des chercheurs ont commencé à expérimenter et à créer des systèmes de questions-réponses capables d’accéder à des textes sur des sujets spécifiques. Le processus, connu sous le nom de text mining, analyse de grandes quantités de texte non structuré et est assisté par un logiciel qui peut identifier des attributs de données tels que des concepts, des modèles, des sujets et des mots-clés. Dans les années 1990, Ask Jeeves – un précurseur de Google, aujourd’hui appelé Ask.com – a popularisé les systèmes de réponse aux questions.
L’article de Google intitulé « Attention Is All You Need », publié en 2017, a présenté l’architecture des transformateurs, marquant un tournant dans la capacité à créer et à former des LLM à la fois évolutifs et efficaces. L’année suivante, le GPT d’OpenAI a été publié, GPT signifiant Generative Pre-trained Transformer (transformateur génératif pré-entraîné).
Ce n’est qu’en 2020 que le cadre du RAG a été introduit. Une équipe de Facebook, aujourd’hui Meta, travaillant dans un laboratoire d’IA londonien a développé un moyen de condenser plus de connaissances dans les paramètres d’un LLM. Ils ont intégré un système de recherche à un LLM pour permettre au modèle de créer des réponses plus dynamiques et mieux fondées.
L’utilisation de RAG ne cesse de croître et d’évoluer. Il est mis en œuvre dans de nombreux chatbots IA importants, dont ChatGPT, par exemple.
En savoir plus sur les modèles d’IA générative, tels que les VAE, les GAN, la diffusion, les transformateurs et les NeRF.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Red Hat Summit : Red Hat AI 3.4 va désormais au-delà du serveur d’inférence
Par: Yann Serra
-
![]()
Qu'est-ce que la chaîne de pensée (CoT) ? Exemples et avantages
Par: Lev Craig
-
![]()
OpenRAG : Meritis veut faciliter le test des architectes RAG
Par: Gaétan Raoul
-
![]()
Elastic automatise la migration vers son SIEM à coup d’IA générative
Par: Gaétan Raoul



