L'exploration de texte (analyse de texte / Text Mining)

Le text mining (l'analyse de texte) est le processus d'exploration et d'analyse de grandes quantités de données textuelles non structurées à l'aide de logiciels capables d'identifier des concepts, des modèles, des sujets, des mots-clés et d'autres attributs dans les données. Il est également connu sous le nom d'analyse de texte, bien que certains fassent une distinction entre les deux termes ; dans ce cas, l'analyse de texte fait référence à l'application qui utilise les techniques d'exploration de texte pour trier les ensembles de données.
L'exploration de texte est devenue plus pratique pour les scientifiques des données et d'autres utilisateurs grâce au développement de plateformes de big data et d'algorithmes d'apprentissage profond qui peuvent analyser des ensembles massifs de données non structurées.
L'exploration et l'analyse de texte aident les organisations à trouver des informations commerciales potentiellement précieuses dans les documents d'entreprise, les courriels des clients, les journaux des centres d'appels, les commentaires verbatim des enquêtes, les messages sur les médias sociaux, les dossiers médicaux et d'autres sources de données textuelles. De plus en plus, les capacités de text mining sont également incorporées dans les chatbots et les agents virtuels que les entreprises déploient pour fournir des réponses automatisées aux clients dans le cadre de leurs opérations de marketing, de vente et de service à la clientèle.
Comment fonctionne le text mining ?
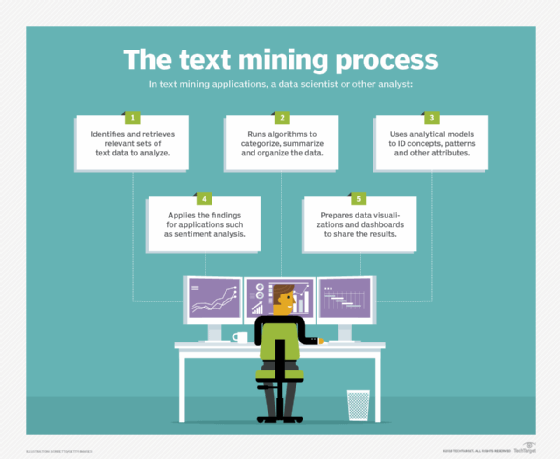
L'exploration de texte est de nature similaire à l'exploration de données, mais elle se concentre sur le texte plutôt que sur des formes de données plus structurées. Cependant, l'une des premières étapes du processus de text mining consiste à organiser et à structurer les données d'une manière ou d'une autre afin de pouvoir les soumettre à une analyse qualitative et quantitative.
Pour ce faire, il est généralement fait appel à la technologie du traitement du langage naturel (NLP), qui applique les principes de la linguistique informatique pour analyser et interpréter les ensembles de données.
Le travail initial comprend la catégorisation, le regroupement et l'étiquetage du texte, le résumé des ensembles de données, la création de taxonomies et l'extraction d'informations telles que la fréquence des mots et les relations entre les entités de données. Des modèles analytiques sont ensuite exécutés pour générer des résultats qui peuvent aider à orienter les stratégies commerciales et les actions opérationnelles.
Dans le passé, les algorithmes de NLP étaient principalement basés sur des modèles statistiques ou basés sur des règles qui fournissaient des indications sur ce qu'il fallait rechercher dans les ensembles de données. Cependant, au milieu des années 2010, les modèles d'apprentissage profond (deep learning), qui fonctionnent de manière moins supervisée, sont apparus comme une approche alternative pour l'analyse de texte et d'autres applications analytiques avancées impliquant de grands ensembles de données. L'apprentissage profond utilise des réseaux neuronaux pour analyser les données à l'aide d'une méthode itérative plus souple et plus intuitive que l'apprentissage automatique conventionnel.
Par conséquent, les outils d'exploration de texte sont désormais mieux équipés pour découvrir les similitudes et les associations sous-jacentes dans les données textuelles, même si les scientifiques des données n'ont pas une bonne compréhension de ce qu'ils sont susceptibles de trouver au début d'un projet. Par exemple, un modèle non supervisé peut organiser des données provenant de documents textuels ou de courriels en un groupe de sujets sans aucune indication de la part d'un analyste.
Applications de l'exploration de textes
L'analyse des sentiments est une application d'exploration de texte très répandue qui permet de suivre le sentiment des clients à l'égard d'une entreprise. Également connue sous le nom de "opinion mining", l'analyse des sentiments exploite le texte des avis en ligne, des réseaux sociaux, des courriels, des interactions avec les centres d'appels et d'autres sources de données afin d'identifier les points communs qui indiquent des sentiments positifs ou négatifs de la part des clients. Ces informations peuvent être utilisées pour résoudre des problèmes liés aux produits, améliorer le service à la clientèle et planifier de nouvelles campagnes de marketing, entre autres.
D'autres utilisations courantes du text mining sont les suivantes :
- Présélectionner les candidats à l'emploi sur la base du libellé de leur CV.
- Blocage des courriers électroniques non sollicités.
- Classification du contenu des sites web.
- Signaler les demandes d'assurance susceptibles d'être frauduleuses.
- Analyser les descriptions de symptômes médicaux pour faciliter les diagnostics.
- Examen des documents d'entreprise dans le cadre des processus de découverte électronique.
Les logiciels de text mining offrent également des capacités de recherche d'informations similaires à celles des moteurs de recherche et des plateformes de recherche d'entreprise, mais il s'agit généralement d'un élément des applications de text mining de niveau supérieur, et non d'une utilisation en soi.
Les chatbots répondent aux questions sur les produits et gèrent les tâches de base du service clientèle. Pour ce faire, ils utilisent la technologie de compréhension du langage naturel (NLU), une sous-catégorie du NLP qui aide les bots à comprendre la parole humaine et le texte écrit afin de pouvoir y répondre de manière appropriée.
La génération de langage naturel (NLG) est une autre technologie connexe qui exploite des documents, des images et d'autres données, puis crée du texte de manière autonome. Par exemple, les algorithmes de NLG sont utilisés pour rédiger des descriptions de quartiers pour les annonces immobilières et des explications sur les indicateurs clés de performance suivis par les systèmes de veille stratégique.
Avantages du text mining
L'utilisation du text mining et de l'analytique pour mieux comprendre le sentiment des clients peut aider les entreprises à détecter les problèmes liés aux produits et à l'activité, puis à les résoudre avant qu'ils ne se transforment en problèmes majeurs qui affectent les ventes. L'exploration du texte dans les commentaires et les communications des clients peut également permettre d'identifier les nouvelles fonctionnalités souhaitées pour renforcer les offres de produits. Dans tous les cas, la technologie permet d'améliorer l'expérience globale du client, ce qui, espérons-le, se traduira par une augmentation des recettes et des bénéfices.
Le text mining peut également aider à prédire l'attrition de la clientèle, ce qui permet aux entreprises de prendre des mesures pour éviter les défections potentielles au profit de concurrents, dans le cadre de leurs programmes de marketing et de gestion des relations avec la clientèle. La détection des fraudes, la gestion des risques, la publicité en ligne et la gestion du contenu web sont d'autres fonctions qui peuvent bénéficier de l'utilisation d'outils de text mining.
Dans le domaine des soins de santé, l'exploration de texte peut aider à diagnostiquer des maladies et des états pathologiques chez les patients sur la base des symptômes qu'ils signalent.
Défis et problèmes liés à l'exploration de texte
L'exploration de textes peut s'avérer difficile car les données sont souvent vagues, incohérentes et contradictoires. Les efforts d'analyse sont encore compliqués par les ambiguïtés qui résultent des différences de syntaxe et de sémantique, ainsi que de l'utilisation de l'argot, du sarcasme, des dialectes régionaux et du langage technique spécifique aux industries verticales individuelles. Par conséquent, les algorithmes d'exploration de texte doivent être formés pour analyser ces ambiguïtés et ces incohérences lorsqu'ils catégorisent, étiquettent et résument des ensembles de données textuelles.
En outre, les modèles d'apprentissage profond utilisés dans de nombreuses applications d'exploration de texte nécessitent de grandes quantités de données d'entraînement et de puissance de traitement, ce qui peut rendre leur exécution coûteuse. Les biais inhérents aux ensembles de données sont un autre problème qui peut conduire les outils d'apprentissage profond à produire des résultats erronés si les scientifiques des données ne reconnaissent pas les biais au cours du processus de développement du modèle.
Il existe également un grand nombre de logiciels de text mining. Des dizaines de technologies commerciales et open source sont disponibles, y compris des outils des principaux fournisseurs de logiciels, dont IBM, Oracle, SAS, SAP et Tibco.







