Qu'est-ce que le principe « garbage in, garbage out » (GIGO) ?

Le principe « garbage in, garbage out » (GIGO), ou « si l'on entre des données erronées, on obtient des résultats erronés », fait référence à l'idée que, dans tout système, la qualité du résultat dépend de la qualité des données saisies. Par exemple, si une équation mathématique est mal formulée, il est peu probable que le résultat soit correct. De même, si des données incorrectes sont saisies dans un programme informatique, il est peu probable que le résultat soit correct ou pertinent.
GIGO signifie simplement que le résultat produit par un système dépend des données qui lui sont fournies. Si vous entrez des données erronées, il y a de fortes chances que vous obteniez un résultat erroné. Cela reste vrai même si la logique du programme est correcte. Ainsi, bien que la logique soit importante, la saisie de données correctes est tout aussi importante, voire plus, pour générer un résultat correct et utile.
Le concept GIGO est couramment utilisé en mathématiques et en informatique, en particulier dans le domaine du développement logiciel. Cependant, il peut être étendu à tout système ou processus décisionnel où des données précises et exactes sont essentielles pour générer des résultats corrects pouvant être utilisés pour prendre les bonnes décisions.
Histoire du « garbage in, garbage out »
La première utilisation connue de l'expression « garbage in, garbage out » (si l'on entre des données erronées, on obtient des résultats erronés) remonte à 1957. Cependant, c'est généralement à George Fuechsel, programmeur et formateur chez IBM, que l'on attribue la paternité de cette expression au début des années 1960. Fuechsel aurait utilisé cette expression pour expliquer de manière concise qu'un modèle ou un programme informatique ne fait que traiter les données qui lui sont fournies : si celles-ci sont erronées, les résultats seront également erronés.
Ce terme est désormais largement utilisé en mathématiques, en informatique, dans les technologies de l'information, en science des données, en intelligence artificielle (IA), en apprentissage automatique (ML) et dans l'Internet des objets (IoT). En fait, GIGO est utilisé pour désigner un large éventail de situations dans le monde réel, telles qu'une décision erronée prise à la suite d'informations incomplètes. « Rubbish in, rubbish out » ou RIRO est une autre façon d'exprimer GIGO.
Exemples concrets de « garbage in, garbage out »
Il existe de nombreux exemples concrets illustrant le principe GIGO, notamment les suivants :
- Si un éditeur de texte tente de lire un fichier binaire, il affichera un contenu illisible (sortie indésirable) car il n'est pas configuré pour lire l'entrée (binaire). Pour l'éditeur, l'entrée binaire est indésirable.
- Si un programme informatique tente d'accéder à une section de mémoire pour laquelle l'accès n'a pas été configuré, le noyau refusera l'accès. Par conséquent, le programme se fermera de manière anormale (ce que l'on appelle également un plantage ou une interruption du programme).
- Si un modèle d'apprentissage automatique ne reçoit pas les données d'entraînement correctes, il apprendra de manière incorrecte et produira des résultats erronés partout où ses connaissances seront appliquées.
- Si un psychologue ne dispose pas de toutes les informations nécessaires sur un patient pour diagnostiquer un trouble mental, il risque de poser un diagnostic erroné et de causer un préjudice involontaire au patient.
Ces dernières années, la pandémie de COVID-19 a fourni des exemples de GIGO et de ses effets. Au début de la pandémie, certains pays ont établi des prévisions chronologiques très élevées concernant les hospitalisations et les décès. Ces prévisions ont été suivies de prédictions catastrophiques, dont beaucoup ne se sont finalement pas réalisées, mais certaines oui. Plus la qualité des données (c'est-à-dire non erronées) utilisées dans ces prédictions était bonne, plus les prévisions étaient précises.
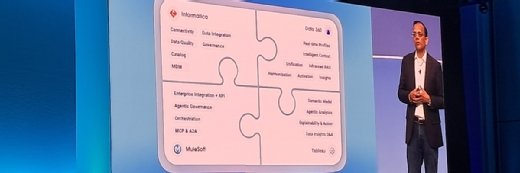
Types de données d'entrée qui génèrent des données de sortie erronées
Dans les situations GIGO, les données erronées peuvent être du type suivant :
- Incorrect (contient des erreurs).
- Obtenu ou enregistré de manière incorrecte.
- Trop différent des autres données (également appelé valeur aberrante).
- Trop similaire à d'autres données.
- Disparu.
- Ne s'applique pas à la situation ou à l'application particulière.
Si les données sont incorrectes en raison d'erreurs, celles-ci peuvent résulter de fautes commises lors de la collecte ou de l'enregistrement des données. Les données qui ne sont pas obtenues de manière appropriée ou auprès des bonnes sources peuvent également être considérées comme inutiles. Les points de données qui diffèrent trop des autres points de données de l'ensemble sont appelés « valeurs aberrantes ». Ils ont généralement des valeurs anormalement supérieures ou inférieures à la moyenne, ce qui affecte les calculs et fausse les résultats.
Les points de données trop similaires aux autres points de données sont dits fortement corrélés ou colinéaires. Ils rendent le modèle ou le système instable, ce qui entraîne des inférences incorrectes et produit des résultats erronés. Les données manquantes ou qui ne s'appliquent pas à la situation ou à l'application peuvent empêcher le système de générer des résultats significatifs ou produire des informations biaisées.
Dans tous ces cas, lorsque les données sont saisies dans le système, cela peut donner lieu à des résultats trompeurs ou incorrects.
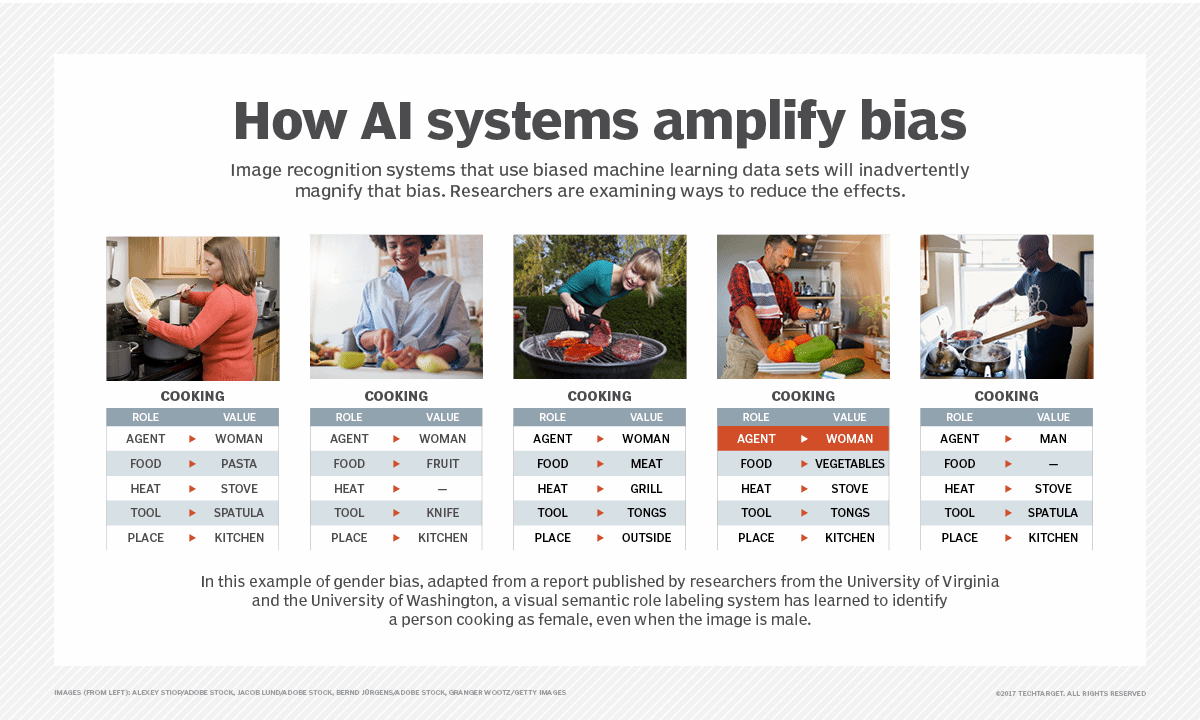
Autres raisons expliquant la production de déchets
Les données erronées ne sont pas la seule cause des résultats indésirables. Le principe GIGO fait également référence à des raisonnements incorrects, des hypothèses erronées et des biais. Ces trois éléments constituent des problèmes courants dans les applications de ML et d'IA. Si le data scientist ou le modélisateur ne comprend pas les problèmes modélisés, fait preuve de partialité dans une certaine direction ou émet des hypothèses sans preuve, le modèle obtenu peut être inexact et produire des résultats indésirables.
Des modèles théoriques et conceptuels incorrects sont également à l'origine de la production de données inutiles, tout comme les données mal étiquetées. Les théories du complot constituent un exemple de tels modèles. Parmi les autres sources de données inutiles, on peut citer :
- Mauvaise compréhension de la causalité.
- Documentation incomplète, manquante ou inexacte.
- Hypothèses erronées.
- Recherche insuffisante.
- Utilisation de méthodes ou de tests statistiques incorrects.
- Problèmes de communication.
- Mauvaise compréhension des objectifs.
- Jugements erronés et confiance excessive dans l'intuition humaine.
Aller trop vite et prendre des raccourcis peut également être une source de déchets.
Comment la gestion des données de référence peut éliminer le problème GIGO
La gestion des données de référence (MDM) consiste à créer un enregistrement de référence unique pour toutes les sources de données et toutes les applications. Les meilleurs processus MDM utilisent plusieurs technologies et processus pour préparer l'enregistrement de référence :
- Intégration des données.
- Rapprochement des données.
- Gouvernance.
- Automatisation.
- Intelligence artificielle
Les activités MDM nettoient et enrichissent les données et suppriment les entrées en double, redondantes et erronées. Elles permettent également de suivre les sources de données et de créer des pistes d'audit des modifications. Elles fournissent ainsi des données cohérentes et fiables qui peuvent ensuite être utilisées pour un large éventail d'applications sans causer de problème GIGO. Le MDM permet également aux entreprises de prendre des décisions plus éclairées, fondées sur les données.
Outre la gestion des données de référence (MDM), voici quelques autres moyens d'améliorer la qualité des données saisies et d'éviter le syndrome GIGO :
- Nettoyez les données d'entrée en corrigeant ou en supprimant les valeurs erronées.
- Combiner les données provenant de plusieurs sources.
- Reformatez les données, si nécessaire.
- Divisez les données en ensembles d'apprentissage, de test et de validation avant de construire le modèle.
- Définissez des critères de réussite et évaluez les performances du modèle en fonction de ces critères.
- Vérifiez régulièrement les ensembles de données afin de corriger les inexactitudes.
Découvrez la gouvernance des données et votre stratégie de gestion des données de référence, et explorez 9 problèmes liés à la qualité des données qui peuvent compromettre les projets d'IA. Découvrez pourquoi une bonne qualité des données est indispensable pour l'apprentissage automatique.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Informatica chez Salesforce : ces zones d’ombre à éclaircir
Par: Gaétan Raoul
-
![]()
Que sont les hallucinations de l'IA et pourquoi constituent-elles un problème ?
Par: Ben Lutkevich
-
![]()
Qu'est-ce que l'IA boîte noire ?
Par: Kinza Yasar
-
![]()
Qu’est-ce que l’apprentissage automatique antagoniste ?
Par: Alexander Gillis