Qu'est-ce qu'un ensemble de validation ? En quoi est-il différent des ensembles de données de test ?

Qu'est-ce qu'un ensemble de validation dans l'apprentissage automatique ?
Un ensemble de validation est un ensemble de données utilisé pour former l'intelligence artificielle (IA) dans le but de trouver et d'optimiser le meilleur modèle pour résoudre un problème donné. Les ensembles de validation sont également connus sous le nom de "dev sets".
Les modèles d'apprentissage supervisé et d'apprentissage automatique sont formés sur de très grands ensembles de données étiquetées, dans lesquels les ensembles de données de validation jouent un rôle important dans leur création.
La formation, l'ajustement, la sélection du modèle et le test sont effectués avec trois ensembles de données différents : la formation, le test et la validation. Les ensembles de validation sont utilisés pour sélectionner et mettre au point le modèle d'IA.
Les ensembles de données de validation utilisent un échantillon de données qui n'est pas utilisé pour la formation. Ces données sont ensuite utilisées pour évaluer toute erreur apparente. Les ingénieurs en apprentissage automatique peuvent alors ajuster les hyperparamètres du modèle, qui sont des paramètres ajustables utilisés pour contrôler le comportement du modèle. Ce processus constitue un ensemble de données indépendantes permettant de comparer les performances du modèle.
Même si les ensembles de données de validation utilisent des données de formation pour les tests, ils ne font pas partie des processus de formation ou de test. Ce processus agit comme une évaluation impartiale d'un modèle.
Quelles sont les différences entre les ensembles de données de formation, de validation et de test ?
Les ensembles de données de validation constituent une partie importante des modèles d'IA, d'apprentissage automatique et d'apprentissage profond, au même titre que les ensembles de données d'entraînement et de test. Ces modèles utilisent ces ensembles de données pour identifier et apprendre à partir de données telles que des images textuelles. Après la formation, les modèles peuvent être appliqués à des domaines tels que la génération de textes et d'images, la compréhension du langage naturel ou le domaine médical. Les ensembles de données de test, de formation et de validation sont tous utilisés pour préparer le modèle à fonctionner, mais ils sont utilisés à différents moments de son développement :
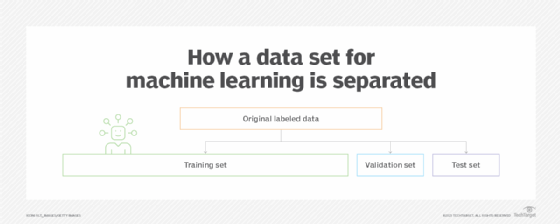
- Les jeux d'essai ne sont utilisés que lorsque le modèle final est complètement formé. Ces ensembles contiennent des données idéales qui s'étendent aux différents scénarios auxquels le modèle serait confronté en fonctionnement. Cet ensemble idéal est utilisé pour tester les résultats et évaluer les performances du modèle final.
- L'ensemble de validation utilise un sous-ensemble des données de formation pour fournir une évaluation impartiale d'un modèle. L'ensemble de données de validation diffère des ensembles de formation et de test en ce sens qu'il s'agit d'une phase intermédiaire utilisée pour choisir le meilleur modèle et l'optimiser. C'est au cours de cette phase que s'effectue le réglage des hyperparamètres. Le sur ajustement est vérifié et évité dans l'ensemble de validation afin d'éliminer les erreurs qui peuvent être causées pour les prédictions et observations futures si une analyse correspond trop précisément à un ensemble de données spécifique.
La formation de modèles avec des ensembles de formation, de validation et de test doit être divisée en fonction du nombre d'échantillons de données et du modèle en cours de formation. Différents modèles peuvent nécessiter beaucoup plus de données que d'autres pour être entraînés. De même, plus il y a d'hyperparamètres, plus l'ensemble de validation doit être important. Il est également généralement considéré comme peu judicieux d'essayer de procéder à d'autres ajustements après la phase de test. Tenter d'ajouter une optimisation supplémentaire en dehors de la phase de validation augmentera probablement le sur ajustement.






