
Rawpixel.com - Fotolia
Booking.com franchit le pas du machine learning vers l’IA générative
Fervent utilisateur d’algorithmes, le spécialiste de la réservation de voyage en ligne a déployé une première application d’IA générative à l’intention de ses clients américains. Un déploiement qui pousse ses experts à pointer les différences entre l’exploitation de modèles de machine learning en production et de grands modèles de langage.

Avec 150 Data Scientists et experts Data en poste, Booking.com exploite de nombreux modèles d’IA sur son site. Sanchit Juneja, directeur produit Big Data et IA chez Booking.com, révélait lors de la conférence Word AI Cannes Forum en janvier 2024 que lorsqu’il navigue sur le site de réservation, l’internaute peut activer jusqu’à 200 modèles de machine learning différents. Ceux-ci personnalisent les recherches, l’ordre de présentation des résultats, les recommandations du site, etc. Environ 350 modèles d’IA sont déployés en production et le site de réservation délivre 200 milliards de prédictions par jour, avec un temps de réponse inférieur à 20 millisecondes dans de nombreux scénarios.
Le géant de la réservation de voyage s’appuie sur AWS pour ses données
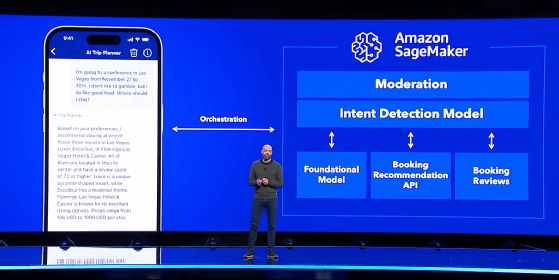
Booking.com s’est récemment allié à AWS pour propulser cette stratégie IA et gérer un volume de données qui atteint désormais… 150 Po. Lors de la conférence AWS re:Invent 2023, Rob Francis SVP et CTO de Booking.com expliquait que le nombre de Jobs lancés par les Data Scientists a pu être multiplié par trois et le nombre de jobs en échec du fait des limitations de l’infrastructure technique de Booking.com a été divisé par deux. Surtout, le délai lié à l’entraînement des modèles a été divisé par cinq, grâce à ce recours au cloud, sachant que l’apprentissage d’un modèle peut s’effectuer sur un dataset comptant jusqu’à trois milliards d’enregistrements.
En juin 2023, Booking.com faisait une première incursion dans le monde de l’IA générative avec son application AI Trip Planner, lancée aux États-Unis dans un premier temps. « L’idée était d’expérimenter comment l’IA pourrait générer de la valeur. Sans entrer dans les chiffres, la valeur apportée à l’utilisateur par une telle application est évidente », explique Sanchit Juneja. L’application s’appuie sur la plateforme SageMaker d’AWS, le LLM « open weight » Llama 2 et une architecture RAG (Retrieval Augmented Generation). L’objectif ? Exploiter tous les avis rédigés par les utilisateurs du site depuis des années et assister le client dans sa prise de décision.
Sanchit Juneja, directeur produit Big Data et IA chez Booking.com

- On peut d’une part utiliser une API publique pour faire du Prompt Engineering. C’est rapide en termes de Go to Market.
- On peut aussi mettre en place une base vectorielle et créer un RAG. Les résultats peuvent être meilleurs, mais cette approche se limite à un nombre réduit de cas d’usage.
- Enfin, le Graal, c’est le Fine Tuning, ce qui permet de personnaliser l’entraînement d’un modèle pré-entraîné. Beaucoup cherchent à en faire, mais sur des modèles relativement petits. »
Une modération des contenus a été mise en place, notamment pour s’assurer que la conversation est bien liée à un voyage, mais aussi filtrer toutes les informations personnelles que l’utilisateur va délibérément livrer au chatbot. Au cours des échanges avec le client, le LLM génère un objet JSON qui est communiqué au moteur de recommandation de Booking.com. À partir de son propre modèle de Machine Learning, ce dernier génère ses recommandations et le carrousel que l’utilisateur va pouvoir manipuler, pour choisir l’hôtel de son choix. SageMaker constitue aujourd’hui la plateforme MLOps et LLMOps de Booking.com. En revanche, Rob Francis a révélé travailler avec les équipes d’Amazon Bedrock et d’Amazon Titan pour mettre en œuvre les LLM.
De loin, cet élargissement de la stratégie IA de Booking.com semble assez naturel. « Fondamentalement, un écosystème MLOps typique doit réaliser deux choses : entraîner le modèle et l’opérer », note Sanchit Juneja. Pour rappel, l’approche MLOps vise à concevoir une chaîne pour construire les modèles, les tester, les débugger, les mettre en production. « Les approches LLMOps et FMOps [“Foundation model operations”, N.D.R.] font la même chose pour les LLM et les modèles de fondation », indique le directeur produit Big Data et IA chez Booking.com.
Les grandes différences entre MLOps et LLMOps
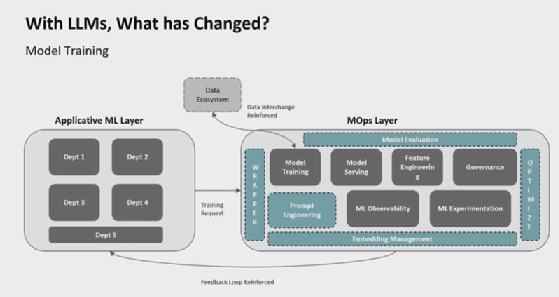
Toutefois, pour l’expert, les LLM impactent de nombreux points dans l’architecture d’entraînement. « Les LLM sont venus ajouter un certain nombre d’éléments supplémentaires comme le Prompt Engineering. De plus, les LLM sont coûteux et nécessitent des GPU ce qui implique le déploiement d’une couche d’optimisation. Une couche d’évaluation du modèle devient nécessaire, car de nombreux LLMs sont disponibles sur le marché. Comment savoir si FLAN-T5 est meilleur que Falcon 7.5B pour tel ou tel cas d’usage ? », s’interroge-t-il.
Alors que les méthodologies et les outils spécifiques au machine learning sont maintenant connus, voire maîtrisés par les data scientists, pour Sanchit Juneja, les LLM constituent un véritable changement de paradigme.
« Avec les LLM, vous n’avez plus nécessairement besoin d’héberger vous-même le modèle. C’est là que les wrappers entrent en jeu », explique-t-il. « Vous pouvez créer votre propre wrapper, mais beaucoup d’éditeurs proposent leur propre solution : Bedrock chez AWS, Vertex AI chez Google, Nvidia AI Foundry. Avec ce wrapper, il devient possible d’appeler directement l’API OpenAI pour accéder à GPT 4, ou appeler un modèle sur AWS. »
Le monde de l’Open Source n’est pas en reste, avec des solutions comme LangChain et LLamaIndex qui ont déjà de fortes communautés d’utilisateurs derrière elles.
Autre différence majeure introduite par les LLM, la puissance de calcul qu’ils requièrent si l’on souhaite les entraîner soi-même. « Avant les LLM, même les modèles de Machine Learning les plus complexes pouvaient être portés par un GPU unique. Un Nvidia H100 a suffisamment de puissance pour porter des applications d’e-commerce les plus complexes », avance-t-il. « Avec les LLM, le nouveau paradigme d’apprentissage est arrivé et il faut évoluer avec un entraînement distribué sur de multiples GPU. Un GPU ne suffit plus. Falcon a mobilisé 2 000 GPU lors de son entraînement », illustre-t-il. Pour l’expert, cette course à la puissance pourrait bien pousser les entreprises à s’intéresser aux composants spécialisés comme les puces Inferentia et Trainium d’AWS, ou les TPU de Google.
En matière de stockage de données, les LLM font aussi bouger les lignes, notamment sur la couche de feature engineering. Cette couche sert plus spécifiquement à préserver plusieurs configurations de poids d’un modèle, pouvant faire varier considérablement ses résultats. « Pour une entreprise comme Booking.com, il est important de capturer les features qui se répètent. Avant même l’arrivée des LLM, les gros utilisateurs de machine learning utilisaient des feature stores. Avec l’arrivée des LLM et la mise en place des RAG, on cherche maintenant à transformer ces Feature Store en Vector stores », poursuit-il. « De même, pour créer des chatbots très efficaces, on commence à voir apparaître des Prompt Store. »
L’arrivée des LLM impose aussi de renforcer les couches d’observabilité, notamment de mettre en place une modération afin de recadrer les LLM toujours sujets aux hallucinations. Il faut aussi pouvoir évaluer et optimiser les modèles en fonction du cas d’usage. Sanchit Juneja évoque la solution d’observabilité SageMaker Clarify ainsi que les solutions d’optimisation proposées par Nvidia avec sa technologie Triton ou encore Nemo Microservices (Nvidia NIM).
Pour approfondir sur Data Sciences, Machine Learning, Deep Learning, LLM
-
![]()
ClickFix : la menace va un cran plus loin avec un faux écran bleu de Windows
Par: Valéry Rieß-Marchive
-
![]()
Qu'est-ce que la génération augmentée par récupération (RAG) dans l'IA ?
Par: Alexander Gillis
-
![]()
L’IA, une opportunité encore à saisir pour les DSI
Par: Cliff Saran
-
![]()
AgentKit : OpenAI renforce sa galaxie d’outils autour de ses modèles
Par: Gaétan Raoul



