Les conseils de Zalando pour rendre votre entreprise « Big Data-driven »
Lors du Salon Big Data Paris, le « Monsieur Données » du e-vendeur d'articles de mode a partagé ses bonnes pratiques pour concevoir, mettre en production et infuser le Machine Learning dans une organisation pour que les modèles soient utilisés (et réutilisés).
Khitij Kumar est vice-président en charge des données chez Zalando, l'un des plus grands magasins en ligne d'Europe pour la mode. « Zalando a commencé comme une simple e-boutique, il y a dix ans », explique-t-il.
Aujourd'hui, le site allemand vend 300.000 articles, de 2 000 marques internationales, pour un chiffre d'affaires de 5,3 milliards d'euros.
Mais il ne vend pas de manière uniforme. Le distributeur 100 % web cherche en effet à localiser et à personnaliser son assortiment le plus possible pour augmenter les ventes et réduire les délais (et les coûts) de livraisons.
« Ce que nous vendons à Paris est différent de ce que nous vendons à Londres ou à Dublin », confirme Khitij Kumar. « Au final, Zalando est un facilitateur. Quelqu'un produit des choses. Quelqu'un consomme ces choses. Nous mettons les deux en relation. Et pour y arriver, tout que nous faisons s'appuie depuis le début sur la donnée - de la BI à l'Intelligence Artificielle en passant par la Data Science ».
Zalando est donc bien un distributeur, mais il se présente également - voire surtout - comme une entreprise technologique.
« Nous sommes probablement aujourd'hui l'une des sociétés les plus avancées au monde dans le Big Data », affirme Khitij Kumar. « Quelque soit l'outil [BI ou Data Science] que vous pouvez nommer, il y a de fortes chances que nous l'ayons déjà regardé, et même probablement utilisé [...] Nous faisons beaucoup de Data Warehouse avec des bases de données traditionnelles. Nous avons aussi un Data Lake dans le cloud. [...] Nous sommes dans le cloud - pas juste un cloud, plusieurs cloud - nous sommes très avant-gardistes et très scalables. Et nous embauchons dans le domaine de la technologie ».
« Nous sommes aujourd'hui l'une des sociétés les plus avancées au monde dans le Big Data »
Khitij KumarZalando
Pour preuve, à date, Zalando compte plus de 2000 employés dans l'IT (sur 15.000 employés), la plupart basés à Berlin.
Mettre les données au cœur des processus et impliquer des leaders
Pourquoi toute cette expertise technique ? Parce que Zalando veut que toutes ses actions s'appuient sur l'analyse des données qu'il collecte chaque jour.
« Toute l'expérience que vous avez sur le site Web découle du Machine Learning (ML) », explique le Monsieur Données de Zalando sur la scène de Big Data Paris. « Par exemple, nous faisons évidemment le "si vous achetez ça ou si vous regardez ça, alors ceci pourrait vous intéresser" ». Le matching peut se faire sur différents paramètres : « un style qui correspond au genre que vous regardez, ou une fourchette de prix qui correspond à ce que vous avez déjà acheté, etc. ». Les algorithmes sont également appliqués pour le cross-selling à la volée : « si je trouve une veste, j'aurai peut-être besoin d'un pantalon, de chaussettes, de chaussures. J'ai peut-être aussi besoin d'une cravate ».
Bref, la donnée et l'apprentissage statistique sont au cœur de nombreux processus de Zalando, et pas seulement du site. Khitij Kumar souligne en préambule que cette diffusion du Big Data dans son entreprise vient d'une volonté des dirigeants. « Le Big Data a besoin de quelqu'un qui soit prêt à prendre le taureau par les cornes [...] Il faut avoir une attitude d'entrepreneur », prévient-il.
« Le Big Data a besoin de quelqu'un qui soit prêt à prendre le taureau par les cornes [...] Il faut avoir une attitude d'entrepreneur »
Khitij KumarZalando
Chez Zalando, la gestion des stocks et de la chaîne d'approvisionnement, le marketing et les ventes, ou encore la publicité sont tous infusés avec du Big Data et du Machine Learning.
« Lorsque nous achetons des stocks pour l'année prochaine, nous voulons nous assurer que nous achetons les bonnes choses et que nous vous livrerons ce que vous voulez au moment où vous le voudrez. Dans le marketing, lorsque vous allez sur Facebook ou sur tout autre site, nous voulons nous assurer que nous vous affichons le bon message sur ce que vous voulez vraiment. En matière commerciale, nous voulons vous proposer les meilleurs rabais possibles [qui permettent de conclure une vente]. Etc., etc. ». Et tout cela avec de l'analytique Big Data pour ne pas simplement proposer un peu plus vite ce que la personne cherche, mais pour lui proposer ce qu'elle pourrait chercher, « même quand elle-même n'a pas encore pris sa décision ».
Machine Learning et Big Data s'articulent donc intimement avec de véritables problématiques métiers. Ce qui ne va pas sans une certaine organisation (lire ci-après). « Nous autorisons par exemple une politique de retour de 100 jours. Vous pouvez acheter ce que vous voulez sur le site et nous le retourner. Typiquement, les gens essaient quatre ou cinq articles pour n'en garder qu'un seul. Mais si l'on arrive à vous proposer exactement ce que vous voulez en une seule fois, cela économise beaucoup de temps [et d'argent] ».
Étapes d'un projet de Machine Learning et bonnes pratiques
Khitij Kumar conseille que tout bon projet ML commence par l'exploration des données, leur compréhension, leur extraction et leur préparation. « Vous ne pouvez pas faire de ML si vous n'avez pas nettoyé les données et retiré celles qui sont erronées ».
Etapes d'un projet Big Data et Machine Learning, Khitij Kumar à Big Data Paris 2019
La deuxième étape consiste - évidemment - à créer le modèle et à le former. Une fois l'entrainement du modèle terminé, la troisième étape consiste à le vérifier et à l'évaluer pour voir s'il fonctionne réellement et comme prévu.
Pour faire tout cela (et les étapes suivantes), Zalando utilise principalement des outils open source. « Nous construisons beaucoup nos outils nous-mêmes, parce que dans de nombreux cas nous faisons des choses qui nous sont très spécifiques ».
« Vous ne pouvez pas faire de ML si vous n'avez pas nettoyé les données et retiré celles qui sont erronées »
Khitij KumarZalando
Néanmoins, Zalando n'est pas opposé par principe à l'utilisation de produits propriétaires. « Mais nous regardons toujours en premier lieu l'open source », insiste le responsable.
Le conseil de Khitij Kumar sur ce point est de bien regarder ce que vous faites en interne et de voir s'il n'y a pas déjà un outil, un modèle ou une compétence que vous pourriez utiliser. Si ce n'est pas le cas « travaillez avec chacun des éditeurs pour vous assurer qu'ils sont bien capables de vous fournir tout ce que vous n'avez pas pu obtenir par d'autres moyens ».
Suivre les modèles en production
Vient ensuite la mise en production. « Une fois qu'il tourne de manière opérationnelle, vous devez surveiller le modèle et voir s'il se comporte comme prévu », préconise Khitij Kumar.
« Vous devrez être en mesure de regarder, de superviser et d'obtenir des retours sur la façon dont un modèle déployé fonctionne, comme son utilisation du CPU, son utilisation de la mémoire et son utilisation du disque sur une certaine période de temps ».
« C'est une histoire sans fin »
Khitij KumarZalando
Pour y arriver, le responsable préconise de réaliser un pipeline « très classique » (sic) mais aussi complet du cycle du Big Data.
Ce workflow devra représenter où sont les données, comment les ingérer, l'entrainement des modèles, leurs déploiements et prévoir de regarder ce qui se passe en production pour, si besoin, les corriger et itérer. « C'est une histoire sans fin », plaisante Khitij Kumar.
Khitij Kumar à Big Data Paris 2019
Modèles partagés et catalogues de données
Pour réellement infuser toute sa structure au Big Data, Zalando a aussi - et surtout - créé une fonction centrale de support du Machine Learning et du Big Data (celle que dirige Khitij Kumar). « Elle couvre tout : Machine Learning, BI, Data Lake, Spark, algorithmes, gouvernance ».
Le but est d'aider les volontaires internes à se lancer. Chaque équipe peut avoir ses propres responsables et experts en ML, mais ils travaillent avec le support de l'organisation centrale.
Car chez Zalando, un modèle doit être disponible et réutilisable par tous. « Par exemple, lorsque vous cherchez une chemise sur notre site, nos équipes de recommandation ont travaillé sur le type de vêtements que nous devrions vous montrer ».
A titre d'exemple concret, Khitij Kumar s'imagine en voyage professionnel et qu'il doit acheter une veste dans un pays étranger pour une réunion. « Si le site me montre une veste à 59,99 euros et pas à 200 euros c'est que l'algorithme a peut-être été en mesure de voir que j'étais en déplacement et que je ne voulais pas acheter des choses que je ne garderais peut être pas. Et donc, il me montre une veste bon marché mais élégante ».
« Les entreprises doivent avoir conscience de la nécessité d'une organisation centrale [ pour diffuser largement le Big Data en interne ] »
Khitij KumarZalando
Une équipe a pu créer un tel moteur de recommandations avec un paramètre de qualification géographique. « [Mais] il y a d'autres personnes au sein de l'entreprise qui peuvent vouloir l'utiliser : pourquoi ne pas le leur donner et les laisser faire ? [...] Il faut donc que ce modèle soit rendu disponible pour tous nos employés. Il faut aussi s'assurer que les gens le sachent et sachent comment l'utiliser en toute sécurité ». D'où l'intérêt d'une fonction centrale dédiée au Big Data pour rappeler ces points et aider au partage.
Zalando ne veut pas s'arrêter aux modèles de Machine Learning. « Si vous utilisez MicroStrategy (NDR : dont Zalando est client pour la BI) ou Tableau et que vous créez des APIs, pourquoi ne pas le partager avec tous les autres ? »
Pour y arriver, Zalando dispose de catalogues de données mais, ajoute Khitij Kumar, « un catalogue de données qui ne liste pas seulement des données stockées dans des tables. Ajoutons-y les modèles, les API, et bien d'autres choses. Bien sûr, il faut faire cela en ayant à l'esprit la sûreté et la sécurité. Il faut donc aussi être en mesure d'avoir une gouvernance sécurisée autour de tout cela »... et donc, à nouveau, une structure dédiée centralisée.
Ce qui ne veut pas dire que tout soit centralisé, bien au contraire. « Certains de nos spécialistes ML les plus pointus ne font pas partie de mon équipe. Ils sont dans les unités métiers, qui utilisent certains des outils que nous mettons à leur disposition ».
Dernier avantage, en diffusant les bonnes pratiques et la réutilisation des modèles Big Data, une telle organisation accélère la conception de nouvelles applications opérationnelles à base de Machine Learning. « Les entreprises doivent avoir bien conscience de la nécessité d'une [telle] fonction centrale », conclut Khitij Kumar.

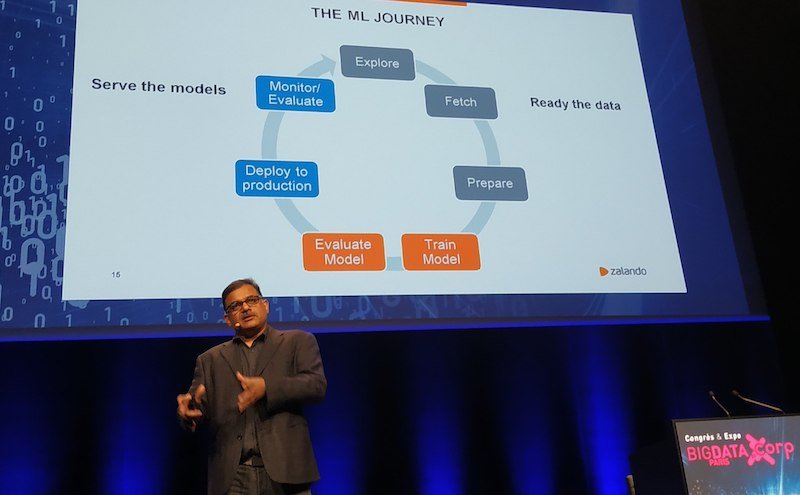 Etapes d'un projet Big Data et Machine Learning, Khitij Kumar à Big Data Paris 2019
Etapes d'un projet Big Data et Machine Learning, Khitij Kumar à Big Data Paris 2019
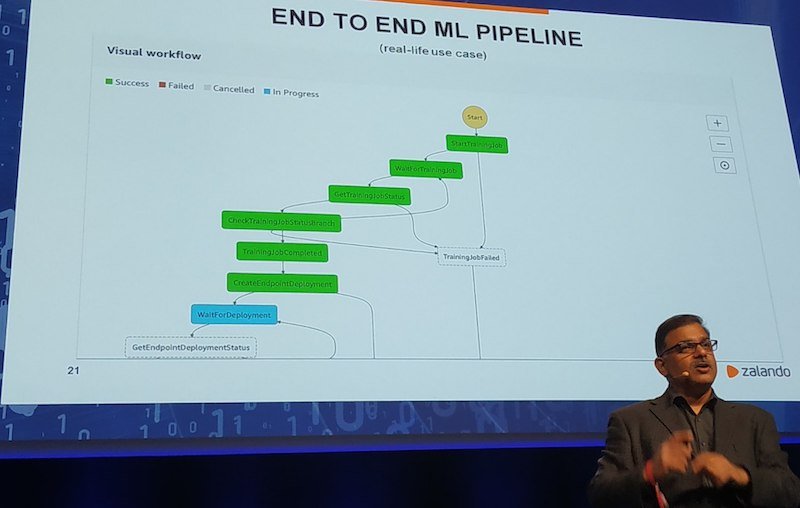 Khitij Kumar à Big Data Paris 2019
Khitij Kumar à Big Data Paris 2019





