SAP Forum : en matière de Big Data, SAP mise sur la complémentarité de son offre
A l’occasion du SAP Forum qui s’est tenu fin mai à Paris, SAP a souhaité montrer qu’il disposait de la force de frappe nécessaire ainsi que de la technologie adéquate pour affronter tous les scénarios du Big Data. Un SAP Big Data Processing Framework, qui mêle notamment Hana, Sybase, BO et bien sûr Hadoop.

Parce que les enjeux autour du Big Data ne sont pas les mêmes pour toutes les entreprises, SAP propose une solution pour chaque scénario. Ce constat, qui résonne quelque peu comme un slogan marketing, pourrait résumer l’approche de l’éditeur allemand en matière de Big Data et d’analytique des données en volume. Lors de SAP Forum, qui s’est tenu à Paris à la fin mai, le groupe de Walldorf a souhaité montrer sa force de frappe en la matière, jouant la carte de la complémentarité entre différentes briques de la pile SAP : Hadoop/MapReduce/Hive, Hana, Sybase et bien sûr BO et les outils de BI analytiques et décisionnel. Bref, un stack complet, baptisé SAP Big Data Processing Framework.
Ainsi, si Hana et la technologie in-Memory du groupe étaient bien au coeur de tous les discours lors du SAP Forum - et d’autant plus sur le terrain du Big Data -, le groupe a souligné posséder également d’autres cordes à son arc pour manipuler et traiter ces très tendances données en volume. A chaque usage, sa solution, en clair. Et Jean-Michel Jurbert, responsable de marché de SAP France, de rappeler que si le Big Data pouvait être résumé en 4 composantes (Vélocité, Variété, Valeur et Volume), celles-ci pouvaient également être abordées de façon différenciée par les entreprises, en fonction de leur secteur d’activité. Certains auront davantage besoin d’aborder le Big Data par la problématique du volume et de la variété et moins par le truchement de la Vélocité, par exemple.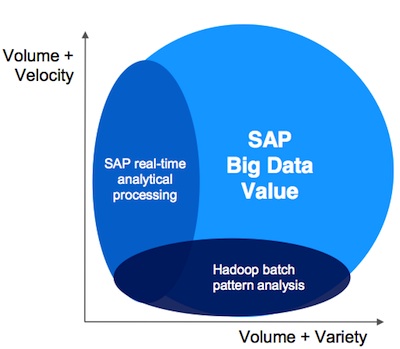
SAP a ainsi montré comment Hana et l’environnement Hadoop pouvaient interagir afin de livrer aux utilisateurs métiers des données exploitables dans BI 4.0, la plate-forme de décisionnel de Business Objects. «L’intérêt de travailler avec Hadoop et de le coupler à Hana est ainsi de considérer Hadoop comme une source de données que l’on peut ensuite restituer dans BO», explique-t-il. Rappelant que la plate-forme BI 4.0 supporte Hadoop, MapReduce et Hive depuis le SP3.
Mais cela ne forme qu’une partie du Big Data Processing Framework, indique SAP, soulignant également les travaux autour de l’intégration des outils de Sybase à l’ensemble de la pile (voir le schéma ci-dessous). Car si le volet mobilité du rachat de Sybase avait fortement été mis en avant, celui portant sur les bases de données avait été placé plus en retrait - SAP a ajouté le support de Sybase ASE à Business Suite depuis décembre 2011.
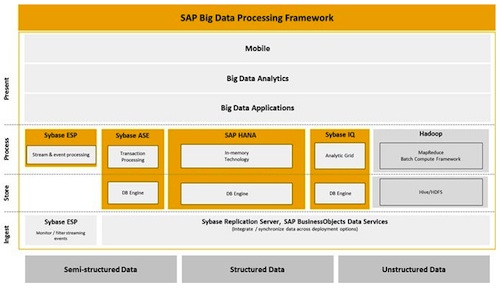
Et SAP d’exposer différentes synergies et autant de cas d’usages, mettant en avant la complémentarité de Sybase IQ avec Hana, de Hana avec Hadoop et de Sybase IQ avec Hadoop : IQ et Hana pour «un découpage possible en historique des données plus étendu, avec une composante temps réel», IQ et Hadoop - une configuration mis en place chez Comscore (voir notre cas client) -, «quelque 2 à 3 To de données arrivent dans Hadoop rafinées pour en donner 200 à 300 Go, puis viennent s’ajouter à la base Synase IQ de façon structurée», illustre François Guerin, Manager avant-vente SAP Sybase France. Celui-ci confirme par ailleurs que les équipes de SAP travaillent à favoriser l’intégration entre les deux technologies, citant l’enrichissement du requêtage de IQ avec UDF (User Defind Function) pour établir un job MapReduce dans Hadoop. Une façon «d’apprendre à IQ à utiliser du MapReduce», précise-t-il.





