IA : « Souvent, ce qu’on appelle Big Data, ça n’existe pas »
Les professeurs Matthieu Jonckheere et Pascal Moyal estiment que le Big Data et le deep learning ne sont pas à la portée de toutes les organisations. Ils seraient même à l’origine d’un manque d’explicabilité de l’IA.
ForePaaS Partner Summit – Paris. « Il y a un engouement énorme sur l’intelligence artificielle, sur le machine learning. Est-ce que ce sont des choses vraiment utiles dans des problématiques industrielles aujourd’hui ou est-ce que nous parlons de recherche seulement ? ». C’est par cette problématique que Matthieu Jonckheere, Professeur à l’Institut de Calcul de l’université de Buenos Aires et professeur invité à Centrale-Supélec, introduit son sujet. Quel est l’état de l’art de l’IA en entreprise ? Voilà la question que se pose en substance le chercheur.
Malgré une attente forte et du « marketing parfois néfaste », le machine learning et le deep learning n’obtiennent pas encore les résultats attendus, selon l’intervenant.
« Nous voyons aujourd’hui qu’il y a des limites fortes sur des réseaux de neurones qui sont aujourd’hui très matures. Nous voyons encore des erreurs, par exemple dans le cas de système de reconnaissance d’images. Si l’on veut reconnaître une libellule, le réseau de neurones, pourtant de très bonne facture, va trouver une bouche d’égout ou confondre un champignon avec un bretzel avec une confiance de 99 % ».
Pour Matthieu Jonckheere, la reconnaissance d’images est pourtant l’un des domaines les plus avancés. « Dans d’autres domaines, nous n’obtenons pas de performance convenable. Aujourd’hui, nous luttons pour améliorer les chatbots et mathématiquement, je ne vois pas comment obtenir des performances nettement supérieures dans les cinq ans à venir ».
« Aujourd’hui, nous luttons pour améliorer les chatbots et mathématiquement je ne vois pas comment obtenir des performances nettement supérieures dans les cinq ans à venir ».
Matthieu JonckheereProfesseur, Institut de Calcul de l'Université de Buenos Aires, invité à Centrale-Supélec.
D’après le professeur, l’échec vient du fait qu’une grande majorité de projets ne vont pas en production. De plus, les algorithmes de machine learning ne sont pas interconnectés. « Ils sont bons pour faire des tâches très spécifiques et dans ce cas, ils peuvent faire mieux que l’humain ».
Le chercheur explique également que l’on a réduit l’intelligence artificielle à trois types d’apprentissage : supervisé, non supervisé et renforcé.
Or les méthodes associées, ces types d’algorithmes ont besoin de « beaucoup beaucoup de données ». « Il faut trouver un équilibre entre la phase d’entraînement et l’efficacité », affirme-t-il. « Si la phase d’entraînement est trop approfondie, le modèle sera difficilement généralisable, si elle est trop courte, il ne remplira pas sa fonction ».
« Il y a une maturité scientifique assez forte, mais pas suffisante pour pouvoir vraiment avancer dans des problématiques industrielles », assure Matthieu Jonckheere. « Le lien avec l’entreprise est encore à faire », ajoute-t-il.
Le Big Data n’est pas pour tout le monde
La source de tous ces algorithmes, malgré tout imparfaits, ce sont les données. Or, « Souvent, ce qu’on appelle Big Data, ça n’existe pas. Il y a soit un lot de données de taille modérée, soit il y a plein de données, mais elles ne sont pas utilisables », constate le chercheur.
Selon lui, une fois que les données sont traitées, nettoyées, rangées, ce n’est plus vraiment du Big Data. « Dans certains cas, si on s’appelle Google et Amazon, il est possible d’exploiter des réseaux de neurones. Souvent, il faut s’adapter à son volume de données et cette adaptation peut coûter l’échec du projet ».
« Dans certains cas, si on s’appelle Google et Amazon, il est possible d’exploiter des réseaux de neurones. Souvent, il faut s’adapter à son volume de données et cette adaptation peut coûter l’échec du projet ».
Matthieu JonckheereProfesseur, Institut de Calcul de l’université de Buenos Aires
Le Big Data a longtemps été défini par les 3V : le volume de données brutes, la variété, leur hétérogénéité et la vitesse, leur génération en continu. Selon le cabinet Gartner, ces ressources demandent d’y appliquer de l’automatisation et des processus pour en tirer de la valeur par l’analyse, les algorithmes et l’IA. Or, le volume des données ne serait pas forcément déterminant pour concevoir un algorithme de qualité.
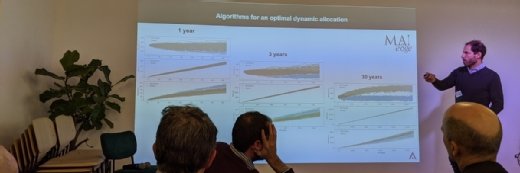
Pascal Moyal, consultant et professeur de mathématiques à l’université de Lorraine, et Matthieu Jonckheere travaillent ensemble. Les deux chercheurs ont présenté un de leurs travaux en cours en collaboration avec l’agence de la biomédecine. L’institution cherche à savoir si un algorithme ne pourrait pas les aider à optimiser le système d’allocation de greffons d’organes. Le but serait de minimiser la perte des organes et des patients tout en allongeant la durée de vie de ces derniers. Dans ce cas, les chercheurs ont adopté une approche déterminée suivant plusieurs contraintes fixes et aléatoires. « Il faut pouvoir prendre des décisions justes, équilibrées et en temps réel », déclare Pascal Moyal.
Un problème d’explicabilité
Les chercheurs ont proposé deux algorithmes de simulation du système. Le premier est une « boîte noire » qui s’appuie sur un historique de trente ans de données des greffons réalisés par l’agence de la biomédecine. Il n’explique pas les décisions qu’il propose. « L’autre algorithme est beaucoup plus léger et explicable. Il est capable de désigner la bonne décision à prendre sur un volume de données assez faible, ici 1 an d’historique de greffes », estime Pascal Moyal.
Résultat à court terme, le premier algorithme permettrait une meilleure allocation des greffons et la survie des patients. « À long terme sur 30 ans, l’algorithme léger performe beaucoup mieux et optimise le système », constate le spécialiste des processus stochastiques. « Dans un monde idéal, il faudrait coupler les deux approches », conclut-il.
Cette simulation semble révélatrice des problématiques rencontrées par les entreprises. Le Big Data, qui devait être l’objectif de tous les groupes, est devenu une réalité dans une minorité d’organisations. Enfin, l’explicabilité des données devient un enjeu désigné par les organisations, les clients et mis en avant par le Gartner.
Pour approfondir sur Outils décisionnels et analytiques