Ao Zaa Studio - stock.adobe.com
Informatica mise sur l’IA agentique au service de la gouvernance de l’IA et des données
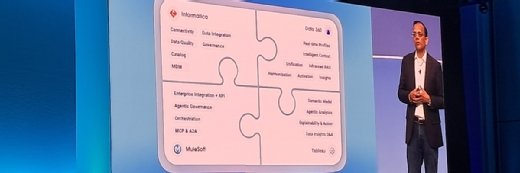
Bien que son approche soit similaire à celle de ses concurrents, Informatica entend se distinguer en ne séparant pas la gouvernance de l’IA de celle des données. La filiale de Salesforce mise donc sur un seul jeu d’outils dédié aux data stewards et aux développeurs.

Lors d’Informatica World 2026 du 19 au 21 mai à Las Vegas, Salesforce a orienté les discussions sur le rapprochement de sa plateforme avec les solutions de sa nouvelle filiale acquise en mai 2025. Or, à l’applaudimètre, ce sont plutôt les annonces consacrées à la gouvernance de données qui ont suscité la plus grande attention des clients.
L’un des points largement mis en avant par les deux acteurs n’est autre que l’adoption de l’approche « headless ». Il ne sera plus nécessaire de passer par l’interface d’Informatica pour interagir avec son back-end. Il faut entendre par là que chaque brique Informatica bénéficiera de son ou ses serveurs MCP pouvant être intégrés à un outil agentique. La suite Cloud Data Governance & Catalog (CDCG) n’y échappe pas. Toutefois, il faut attendre la fin de la deuxième moitié 2026 pour en profiter. Les porte-parole d’Informatica ont profité de l’événement pour démontrer les futures capacités accessibles à travers son agent data stewardship et les IDE agentiques comme Claude Code, ainsi que Slack.
Unifier la gouvernance de l’IA et des données
Avec l’accès aux politiques de gouvernance configurés dans CDCG, aux données sources et aux spécifications agentiques, le LLM peut identifier les règlements internes et externes auxquels un projet de gestion de données ou d’IA doit se conformer pour espérer passer en production.
Les spécifications sont composées de « skills », concoctés par Informatica et d’un document d’exigences produit. Ce dernier renseigne les objectifs et les caractéristiques d’un projet. Les skills sont des instructions en langage naturel qui renferment un ensemble de bonnes pratiques de gestion de données, de gouvernance et d’usage de la plateforme Informatica.
Une fois cette étape de vérification agentique effectuée, un data steward en chair et en os peut examiner si le projet est bien conforme. « En tant que développeur, cela permet d’obtenir un accord avant même d’avoir écrit une seule ligne de code », promet Sumeet Agrawal, vice-président gestion produit chez Informatica.
À la manière de ServiceNow et son AI Control Tower ou de son concurrent Alation, la filiale de Salesforce commence par la mise en conformité avec l’AI Act européen et l’AI Risk Management Framework du NIST, ainsi que le RGPD. D’autres réglementations suivront.
« Policy to Code » : Informatica veut appliquer les règles de protection de données à l’exécution
Informatica veut aller plus loin. Cette validation ne doit pas être un simple coup de tampon sur un formulaire numérique. L’approbation devra enclencher un flux de travail automatisé pour mettre en application les règles au niveau du code. « Quelles que soient les politiques que vous avez définies avec vos data stewards ou celles que d’autres définissent dans votre catalogue, nous pouvons les convertir en éléments exécutables », affirme Sumeet Agrawal auprès du MagIT.
Pour rappel, les outils « policy as code » servent majoritairement à appliquer des règles de sécurité et de conformité au niveau du réseau et de l’infrastructure dans un langage lisible par les machines. Ici, l’éditeur évoque une approche légèrement différente de « policy to code ».
Ici, Informatica combine des garde-fous appliqués au LLM et aux serveurs MCP – la fameuse Flex Gateway de MuleSoft – avec des techniques d’automatisation plus traditionnelle basées sur des règles et des détections opérées par des modèles de machine learning. Tout cela devrait aider à masquer les données sensibles, s’assurer d’un accès seulement aux bonnes données, l’application du chiffrement, etc.
« L’approche policy as code concerne par exemple la limitation du débit, le filtrage des IP, la configuration du chiffrement, etc. », distingue Sumeet Agrawal. « Notre vision du policy to code est de bloquer les données sensibles avant qu’elles n’atteignent l’agent IA de raisonnement ».
Les nuances de la gouvernance IA chez Informatica, Alation et Collibra
En sus de ce système « policy to code » pour la gestion de données, Informatica prépare la mise en place d’une fonctionnalité de notification des dérives. Son agent Data Stewardship peut être connecté au data lineage au sein de la plateforme Informatica Data Management Cloud (IDMC). « Si de nouvelles sources de données sont ajoutées pour alimenter une instance Snowflake, nous pourrons faire une vérification automatique des dépendances avec tous les systèmes d’IA », assure Sumeet Agrawal. De la sorte, un data steward fera appliquer des règles sur les nouvelles données ou notifiera les développeurs pour qu’ils modifient l’application cible.
Ici, il s’agit de rassurer les entreprises quant à la mise en production de leurs agents IA. Néanmoins, les porte-parole d’Informatica ne disent rien à propos de la réception des régulateurs sur l’application de l’AI Act et des standards du NIST par des systèmes d’IA, hormis d’assurer que tout cela pourra être audité. En la matière, le concurrent Alation a été plus clair concernant l’auditabilité des actifs IA (serveurs MCP et LLM). Toutefois, Alation se contente d’un suivi en direct des validations par les équipes de conformité, plutôt que d’appliquer automatiquement les politiques.
Le Belge Collibra se situe entre Alation et Informatica tout en s’approchant de ServiceNow. En préversion privée, son AI Command Center inclut déjà une brique d’observabilité des déviations des modèles, propulsé par son partenaire français Giskard. Toutefois, comme le nom l’indique, la solution se concentre d’abord sur le suivi des projets d’IA. Les actions doivent être prises avant le déploiement des cas d’usage et les outils sont là pour alerter des problèmes en production, pas pour les empêcher. Cela pourrait changer : Giskard développe Guards, un système « conscient du contexte » qui applique des règles sous forme de policy as code (OPA/REGO), en combinant les sujets de gouvernance, de qualité des résultats, de sécurité et de cybersécurité. Cerise sur le gâteau, cette passerelle pourra s’installer sur site.
À l’opposé, Informatica veut rassembler sous le même toit la gouvernance des données et de l’IA.
Les porte-parole d’Informatica semblent d’ailleurs plus préoccupés par la prise en charge des données non structurées. Les mécanismes décrits ci-dessus ne sont en majorité valable que pour les données structurées. Or, le cabinet d’analystes IDC estime qu’environ 90 % des données en possession des entreprises sont sous la forme de documents.
Gouverner les données non structurées et en améliorer la qualité
D’ici à la fin de l’année 2026, Informatica compte enregistrer ces documents dans le data catalog de CDGC et pouvoir les classifier. « Nous souhaitons que les utilisateurs puissent désigner un espace de stockage objet contenant toutes leurs données non structurées, puis déterminer lesquelles sont des CV, des factures, des bons de commande, et ainsi de suite », détaille Gaurav Pathak, vice-président sénior gestion des produits IA et métadonnées pour Informatica chez Salesforce, auprès du MagIT. « Cette fonctionnalité sera disponible en juillet, et nous pourrons alors également effectuer une classification approfondie au sein de ce référentiel ».
Il s’agit non seulement d’identifier la nature des documents, mais également la présence ou non de données sensibles (financières et personnelles, par exemple). En clair, Informatica entend exploiter des scanners (algorithmes de machine learning et LLM as-a-judge) pour étiqueter les données non structurées avec des métadonnées. Ces scanners seront accessibles à travers l’agent IA data stewardship.
« Nous examinons les données non structurées à la fois sous forme de fichiers bruts et dans des bases de données vectorielles, où elles sont également segmentées sous forme de chunks. Mais nous commencerons par les fichiers bruts », indique Gaurav Pathak.
La première base de données vectorielle prise en charge sera Pinecone, selon la présentation de l’éditeur. Elle sera l’une des premières plateformes avec Salesforce et Google Cloud à bénéficier des fonctions de gouvernance de l’IA assisté par l’IA agentique.
Il faudra néanmoins attendre la première moitié de l’année 2027 pour que la plupart de ces fonctionnalités se concrétisent. Les fonctions de « policy to code » ou de gouvernance d’IA au runtime seront lancées l’année prochaine, tout comme la notification des dérives de métadonnées (une autre fonction inspirée de l’infrastructure as code). À ce moment-là, les services d’AWS, Databricks et Microsoft Azure seront également pris en charge.
Concernant les données non structurées, Informatica veut s’attaquer à un chantier plus complexe. À savoir, l’analyse de leur qualité.
« Il y a encore des problèmes flagrants de qualité avec les systèmes RAG [Retrieval Augmented Generation, N.D.L.R.] », justifie Gaurav Pathak. « Un LLM peut avoir du mal à interpréter un document complexe, mais sous forme de chunks, l’information est répétée à plusieurs endroits, ce qui peut polluer les classements et donc les résultats. Le balisage avec des métadonnées peut améliorer leur gouvernance et leur mise en qualité ».
Dans un même temps, les fournisseurs de LLM observent que les agents IA s’en sortent mieux pour explorer des documents quand ils sont découpés en fichiers Markdown ou sous la forme de fichiers HTML correctement balisés. C’est la technique exploitée par les ingénieurs d’Anthropic et de ServiceNow, entre autres. Toutefois, les architectures RAG s’appuient sur les mêmes techniques de recherche sémantique avancée : une fois en place, un LLM n’est pas nécessaire pour retrouver les données.
Au vu de ces évolutions, Gaurav Pathak estime qu’Informatica doit encore éprouver sa technique de balisage des documents et des chunks. « Ce sont des idées que nous explorons actuellement », tempère-t-il.
Pour approfondir sur MDM - Gouvernance - Qualité
-
![]()
IA agentique : SAS rattrape son retard et mise sur la gouvernance
Par: Gaétan Raoul
-
![]()
Horizon : Snowflake étoffe sa couche de gouvernance pour l’IA
Par: Gaétan Raoul
-
![]()
Informatica chez Salesforce : ces zones d’ombre à éclaircir
Par: Gaétan Raoul
-
![]()
MDM et IA agentique : Informatica consolide ses ponts avec Salesforce
Par: Gaétan Raoul