Nombreuses sont les entreprises à se tourner vers le DataOps pour tirer le meilleur parti de la gestion des données. Découvrez comment vous entourer de la bonne équipe pour garantir le succès d’une approche DataOps.
Une stratégie DataOps repose en grande partie sur la collaboration. C’est même un facteur de réussite essentiel d’une telle approche. Surtout quand il est question de faire circuler les données entre les managers et les utilisateurs dans l’ensemble de l’entreprise. C’est pourquoi il faut commencer par constituer une équipe efficace pour mener ces initiatives.
L’on pourrait naturellement résumer le DataOps à l’application de l’approche DevOps aux données. Ce n’est pas tout à fait cela. Il serait plus exact de dire que le DataOps tente d’atteindre pour les données ce que le DevOps vise pour les logiciels, c’est-à-dire une amélioration considérable de la productivité et de la qualité. La méthodologie DataOps a toutefois d’autres problèmes à résoudre. Il faut notamment savoir comment maintenir continuellement un système critique en production.
Cette distinction est loin d’être vaine lorsqu’on en vient à réfléchir à la constitution d’une équipe DataOps. Si l’approche DevOps est un modèle impliquant des chefs de produit, des Scrum Masters et des développeurs, la priorité est donnée à la livraison. Le DataOps devant aussi se focaliser sur une maintenance continue, cette démarche nécessite d’autres méthodes de travail.
Les techniques de Lean Manufacturing ont exercé une grande influence sur le DataOps. Les responsables utilisent souvent des termes tirés du système de production classique de Toyota, maintes fois étudié et imité. Des concepts comme la data factory (fabrique intelligente des données) surgissent également dès que les pipelines de données en production deviennent des sujets de conversation.
Cette méthodologie exige une structure d’équipe bien particulière, dont nous allons examiner certains rôles.
Quels sont les principaux rôles d’une équipe DataOps ?
Les rôles décrits ici sont les membres typiques d’une équipe DataOps chargée de déployer des projets stratégiques de data science en production.
Qu’en est-il des équipes moins portées sur la data science ? Ont-elles aussi besoin de recourir au DataOps, pour l’entreposage des données par exemple ? Certaines techniques sont certes similaires, mais une équipe traditionnelle constituée de développeurs ETL (Extract, Transform et Load) et de data architects (architectes de données) obtiendra de très bons résultats. De par sa nature, un entrepôt de données est moins dynamique et plus constant qu’un environnement de données constitué de pipelines Agile. Les rôles suivants d’une équipe DataOps gèrent un univers plus volatile de pipelines, d’algorithmes et d’utilisateurs en libre-service.
Pour autant, les techniques DataOps gagnent du terrain. Les responsables de data warehouse affichent leur volonté d’être plus agiles. Ils misent ainsi sur le déploiement dans le cloud et à des architectures de type « data lakehouse ».
Commençons par définir les rôles nécessaires à ces nouvelles méthodologies d’analyse.
Le data scientist
Les data scientists s’apparentent à des chercheurs. Si une entreprise sait ce qu’elle veut et qu’elle cherche simplement une personne capable d’implémenter un processus prédictif, il lui suffit de trouver un développeur qui maîtrise parfaitement les algorithmes. En revanche, le data scientist consacre sa vie à la recherche, pour découvrir au fur et à mesure ce qui est le plus pertinent et le plus significatif.
Au cours de l’exploration, un data scientist peut essayer plusieurs algorithmes, souvent dans des ensembles de différents modèles. Il peut même en écrire lui-même.
Ce rôle requiert des qualités indispensables : une curiosité insatiable, un intérêt pour le domaine et des connaissances techniques (surtout en statistiques) pour bien appréhender la signification de ce qu’il découvre et l’impact de son travail sur le monde réel.
Cette rigueur a toute son importance. Il ne suffit pas de trouver un bon modèle et de s’arrêter là, car les secteurs d’activité évoluent sans cesse. Bien qu’ils ne travaillent pas tous dans des secteurs où règnent des conflits éthiques contraignants, les data scientists, tous domaines confondus, seront tôt ou tard confrontés à des problèmes de confidentialité aussi bien personnelle que commerciale.
Il s’agit d’un rôle technique avant tout, mais n’en oublions pas pour autant l’aspect humain. Les entreprises n’embauchent pas qu’un seul data scientist. Ce dernier se doit d’être un bon communicant. Il lui revient d’exposer ses découvertes à un public non technique, souvent des cadres, tout en expliquant en termes clairs ce qui est possible et ce qui ne l’est pas.
Pour finir, le data scientist, surtout s’il travaille dans un domaine tout nouveau pour lui, ne connaîtra vraisemblablement pas toutes les sources de données opérationnelles (systèmes ERP, CRM, RH, etc.). Pourtant, il lui faudra travailler avec ces données. Si la gouvernance du système est bien conçue, il n’aura sans doute pas directement accès à toutes les données brutes de l’entreprise. Il devra donc collaborer avec d’autres rôles qui connaissent mieux les systèmes sources que lui.
Le data engineer
Il appartient généralement au data engineer de déplacer les données entre les systèmes opérationnels et le data lake, et de là entre les différentes zones du lac (données brutes, nettoyées et de production).
Le data engineer peut également être amené à gérer l’entrepôt de données. Mission qui peut s’avérer ardue puisqu’il faut à la fois suivre l’historique en vue du reporting et de l’analyse et en assurer le développement continu.
À une époque, le data engineer a pu être considéré comme un architecte de l’entrepôt de données ou un développeur ETL, selon ses compétences. Nouvelle appellation à la mode, le terme data engineer insiste davantage sur l’aspect opérationnel de ce rôle dans sa dimension DataOps.
Le DataOps engineer
Encore un ingénieur ? Oui, et qui plus est, un ingénieur spécialisé dans les opérations. Mais son domaine de compétence diffère : sa mission est de faciliter le travail du data scientist.
De son côté, le data scientist s’intéresse à la modélisation et à l’exploitation optimale des données. Toutefois, force est de constater que, bien souvent, ce qui fonctionne bien dans le cadre des tests peut être difficile ou coûteux à déployer en production. Il arrive qu’un algorithme s’exécute trop lentement pour le jeu de données de production. De même, il peut tirer trop de puissance de calcul ou de stockage pour évoluer efficacement. C’est là qu’intervient le DataOps engineer : les tests, les ajustements et la gestion des modèles pour la production sont de son ressort.
Il sait comment garantir la performance d’un modèle au fil du temps, à mesure de l’évolution des données. Il sait aussi à quel moment il faut recycler le modèle ou le reconceptualiser, même si ce travail relève des attributions du data scientist.
Le DataOps engineer veille à ce que les modèles respectent les contraintes de budget et de ressources, sujet qu’il maîtrise mieux que quiconque dans l’équipe.
Le data analyst
Dans une entreprise moderne, le data analyst possède parfois un large éventail de compétences : connaissances techniques, compréhension esthétique de la visualisation et qualités dites non techniques, comme le sens de la communication et la collaboration. Il a souvent reçu une formation technique moins poussée qu’un DBA, par exemple.
Son appropriation des données et son influence dépendront moins de sa position hiérarchique dans l’entreprise que de son engagement personnel et de sa volonté de s’attaquer à un problème.
Chaque service a son data analyst. Regardez autour de vous. Toute personne qui, indépendamment de son titre, sait où se trouvent les données, comment les exploiter et comment les présenter efficacement est le « spécialiste des données ».
Ce rôle devient de plus en plus formel aujourd’hui, mais soyons honnêtes, un grand nombre d’analystes de données ont accédé à cette fonction grâce à leurs connaissances métier et non techniques.
Le sponsor exécutif
Le sponsor exécutif est-il un membre de l’équipe ? Peut-être pas directement, mais sans lui, l’équipe n’ira pas bien loin. Un cadre dirigeant joue un rôle essentiel : il met en adéquation les projets spécifiques d’une équipe DataOps avec la vision stratégique et les décisions tactiques de l’entreprise. Il peut aussi veiller à ce que l’équipe dispose d’un budget et de ressources en accord avec les objectifs fixés à long terme.
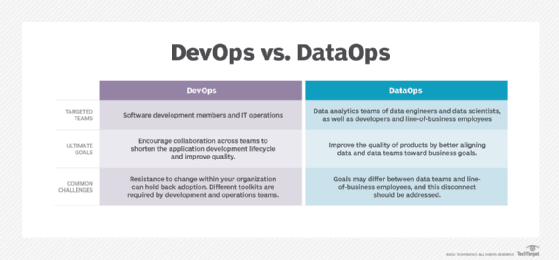
La différence entre DevOps et DataOps
Comment modeler l’équipe aux besoins de l’entreprise ?
Rares sont les entreprises à pouvoir, ou à vouloir, constituer immédiatement une équipe de quatre membres ou plus simplement pour mener une approche DataOps. Les capacités et la valeur de l’équipe doivent grandir au fil du temps.
Mais, comment faire évoluer une équipe ? Quel doit-être le premier poste à pourvoir ? Tout dépend du point de départ choisi par l’entreprise, mais un sponsor exécutif doit être présent dès le premier jour.
Il est peu probable que l’équipe parte de zéro. Les entreprises ont recours au DataOps précisément parce qu’elles ont des travaux en cours dont elles souhaitent optimiser les opérations. Elles commencent à s’intéresser à cette méthodologie, car leurs data scientists dépassent constamment les limites de ce qu’ils sont en mesure de réellement gérer.
Dans ce cas, il convient d’embaucher en tout premier lieu un ingénieur DataOps. C’est en effet à lui de mettre en œuvre les projets de data science et d’en faciliter la gestion, l’évolution et la globalité pour en faire un outil stratégique.
Il est par ailleurs possible qu’une entreprise dispose d’un data warehouse traditionnel et qu’elle compte dans ses rangs des data engineers et des data analysts. Dans ce cas, l’équipe DataOps doit se doter d’un data scientist et lui confier les analyses les plus avancées.
L’équipe DataOps peut faire toute la différence entre une entreprise qui fait un coup d’éclat un jour et celle qui peut compter en continu sur des données, des analyses et des indicateurs efficaces et fiables.
Reste une question importante : faut-il créer une organisation formelle ou une équipe virtuelle ? C’est là une autre raison d’être du sponsor exécutif, qui a sûrement beaucoup à dire à ce sujet. De nombreuses équipes DataOps commencent sous la forme de groupes virtuels qui travaillent de manière transversale pour garantir la fiabilité et la crédibilité des données et de leur flux.
Plus ou moins étroitement liées, ces diverses disciplines gagnent en force et en impact au fil du temps. Leur orientation stratégique et leur usage des ressources s’inscrivent dans un cadre cohérent facilitant l’exploration et la livraison. Au fur et à mesure, l’entreprise peut développer l’ingénierie pour améliorer la montée à l’échelle et la gouvernance, et recourir à davantage de data scientists et d’analystes pour une interprétation plus pertinente des données. À ce stade, quel que soit le point de départ de l’entreprise, l’équipe deviendra plus structurée et gagnera en reconnaissance.
C’est une aventure passionnante. L’équipe DataOps peut faire toute la différence entre une entreprise qui fait un coup d’éclat un jour et celle qui peut compter en continu sur des données, des analyses et des indicateurs efficaces et fiables.
Pour approfondir sur Intelligence Artificielle et Data Science