Comment planifier la reprise d’activité après sinistre à l’ère du cloud
Cet article explique les étapes nécessaires pour mettre en place les bases solides d’un plan de reprise d’activité après sinistre. Elles incluent l’évaluation des risques techniques et l’analyse d’impact.

Les programmes de reprise d’activité après sinistre proposent des stratégies et des procédures permettant aux entreprises de protéger leurs investissements dans l’infrastructure informatique. Leur principal objectif est de retrouver au plus vite un niveau de performance acceptable à la suite d’un incident grave. Le développement et l’adoption rapide des technologies dans le cloud ont considérablement amélioré le processus de reprise d’activité après sinistre.
La structure d’un plan de reprise d’activité après sinistre (alias PRA, ou, en anglais, DR plan, pour « disaster recovery ») est constante, quel que soit le cas d’usage, ce qui facilite l’organisation et la réalisation. Examinons de plus près le processus. La figure 1 est une adaptation de la norme internationale ISO 27031:2011, développée par l’Organisation internationale de normalisation (ISO).
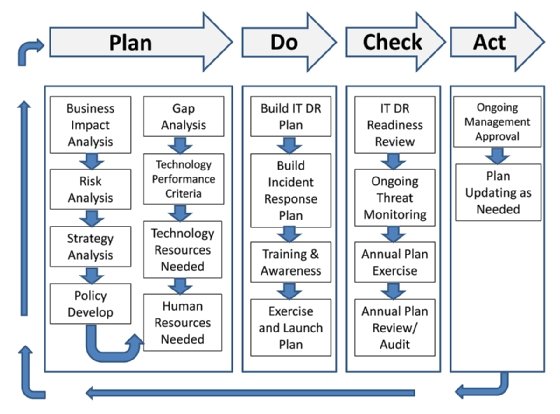
Cette structure reprend le modèle PDCA (plan-do-check-act, ou planifier, réaliser, vérifier, agir) déjà utilisé par d’autres normes ISO. Une analyse d’impact (BIA, business impact analysis) est généralement réalisée avant l’évaluation des risques, afin d’identifier les fonctions métier les plus importantes ainsi que les systèmes et actifs informatiques dont elles dépendent. L’évaluation des risques techniques (RA, risk assessment) examine ensuite les menaces et vulnérabilités internes et externes susceptibles d’avoir des répercussions négatives sur les actifs informatiques. Le recours à des services cloud, généralement basés ailleurs, hors du contrôle du service informatique, rappelle l’importance de ces deux analyses.
Une fois définis les systèmes et fonctions métier essentiels ainsi que les risques associés, l’étape suivante consiste à définir des stratégies visant à limiter les risques et les menaces pour ces actifs. Vous pouvez par exemple envisager de stocker les données et systèmes stratégiques hors site, en faisant appel à une société de services cloud, comme AWS ou Microsoft Azure. Vous pouvez aussi diversifier les fournisseurs de composants informatiques critiques comme les serveurs ou les routeurs.
Les grandes lignes du processus
Les PRA comprennent un processus détaillé, étape par étape, pour réagir en cas d’incident grave (tel que défini dans l’évaluation des risques). Ces étapes fournissent une procédure simple à utiliser et reproductible. Elle est destinée à récupérer les actifs informatiques endommagés et à les rendre de nouveau opérationnels le plus vite possible. Il s’agit là d’un défi intéressant, étant donné que le département informatique n’a absolument aucun contrôle sur les services fournis depuis le cloud et qu’il doit être particulièrement proactif lors de l’évaluation, puis lors de la gestion d’un fournisseur de services cloud.
Plusieurs exercices permettent de déterminer si les procédures de reprise d’activité après sinistre fonctionnent comme prévu, qu’il s’agisse d’une évaluation point par point des plans et procédures de reprise (par exemple dans une salle de conférences) ou d’un exercice de simulation grandeur nature permettant de déterminer les conséquences réelles d’une panne du système.
Dans un environnement cloud, le fournisseur de services de reprise d’activité peut proposer ses propres exercices de reprise. Il est alors important d’examiner les mesures à prendre éventuellement avant de signer un contrat de service cloud. Il est notamment primordial de savoir quelles ressources le fournisseur utilisera, quelle quantité de données de performance l’exercice permettra d’obtenir, et quel pourra être le degré d’implication des utilisateurs pendant l’exercice.
Lors des mises à jour du plan, un processus doit permettre de prendre en compte la gestion des modifications, les changements de personnel, et toute autre situation pouvant altérer l’efficacité ou le contenu du plan. Les mises à jour permettent de vérifier que le plan est adapté aux objectifs et qu’il est en phase avec les effectifs et les activités métier en cours.
Les fournisseurs de services de PRA en cloud peuvent assurer une certaine dose de flexibilité pendant le développement et la mise à jour du plan. Il est indispensable de passer au peigne fin tous les services proposés par un fournisseur de cloud, et de comparer le coût d’une gestion par un prestataire externe à celui d’une gestion en interne.
Analyse d’impact (BIA)
Pour la réalisation d’une analyse d’impact, l’ISO propose une norme qui fournit des conseils utiles de planification et d’exécution. Il s’agit de la norme ISO 22317:2015. L’analyse d’impact constitue l’amorce. Elle consiste à déterminer les processus métier les plus indispensables à l’activité et les actifs informatiques dont ils dépendent. Cette étape permet aussi de détecter d’autres conséquences inattendues pour l’entreprise en cas de perturbation de fonctions métier clés, comme la perte de clients, la baisse des performances financières, la dégradation de la réputation, et leurs effets sur les employés et les chaînes d’approvisionnement.
Après avoir identifié les principales activités métier ainsi que les systèmes et données dont elles dépendent, il convient de lister leurs risques. Une BIA utilise une série de questions présentées à des managers et à des spécialistes de chacune des unités opérationnelles de l’entreprise, service informatique compris. Ces questions doivent porter au minimum sur les points suivants :
- Connaissance du mode de fonctionnement de chaque unité opérationnelle.
- Identification des processus essentiels, au sein de ces unités opérationnelles, qui dépendent de l’infrastructure informatique (sur site).
- Identification des processus essentiels, au sein de ces unités opérationnelles, qui dépendent de l’infrastructure informatique (dans le cloud).
- Valeur financière des processus métier essentiels (par exemple, revenus horaires générés).
- Dépendances vis-à-vis des organisations internes.
- Dépendances vis-à-vis des prestataires externes, notamment les fournisseurs de services cloud.
- Exigences en matière de données.
- Conditions système requises.
- Temps minimum nécessaire pour récupérer les données et restaurer leur état d’utilisation antérieur.
- Temps minimum requis pour rétablir l’état de fonctionnement normal ou quasi normal de l’infrastructure informatique à la suite d’un incident.
- Nombre minimum d’employés nécessaires à la poursuite des opérations.
- Technologie minimale nécessaire à la poursuite des opérations.
- Durée maximale d’indisponibilité des technologies, avant que l’entreprise cesse de pouvoir fournir ses produits et services.
Les résultats de l’analyse d’impact donnent un aperçu clair des retombées réelles sur l’activité, en termes de problèmes éventuels et de coûts prévisibles. Ils permettent de déterminer les éléments à protéger, le degré de tolérance de l’entreprise aux perturbations, les niveaux minimums de service informatique requis et le temps maximum d’indisponibilité avant que l’entreprise commence à dysfonctionner.
Évaluation des risques techniques (RA)
Pour l’analyse des risques techniques, il existe également une norme américaine formulée par le NIST (National Institute for Standards and Technology) : NIST SP 800-30 (2012). Les responsables informatiques se polarisent généralement sur l’un ou plusieurs des scénarios de risque suivants, dont la survenue aurait très certainement un impact négatif sur la capacité de l’entreprise à poursuivre ses opérations :
- Perte d’accès
- Perte de données
- Perte de fonction
- Perte de compétences
- Perte de contrôle
Le recours à des services dans le cloud implique un risque de perte de contrôle certain pour les départements informatiques. Sur site, il est possible de planifier et de gérer la reprise d’activité après sinistre de bout en bout, tandis que dans le cloud, le contrôle de nombreuses fonctions revient au prestataire externe. Il incombe aux directeurs informatiques de décider si le risque lié à l’utilisation du cloud en vaut la chandelle.
L’évaluation des risques techniques permet de définir les menaces et les vulnérabilités susceptibles d’entraîner les conséquences mentionnées plus haut. Il existe de nombreuses méthodes d’analyse des risques. Le tableau ci-dessous à droite fournit néanmoins une approche simple, facile à mettre en œuvre. La difficulté consiste à faire valider les estimations de facteurs de risque par les dirigeants.
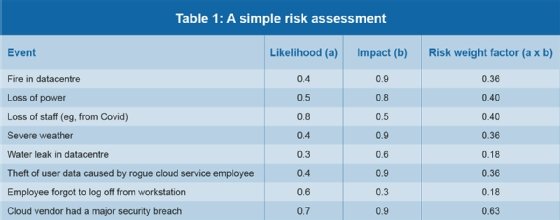
Ce tableau présente des exemples réalistes d’événements à risque dans des environnements sur site ou dans le cloud. D’après des expériences réelles et les statistiques disponibles, issues par exemple de compagnies d’assurances ou de données actuarielles, il est possible d’estimer la probabilité de certains événements sur une échelle de 0 à 1 (0,0 = ne se produira jamais, et 1,0 = se produira toujours). On peut ensuite appliquer la même procédure à l’impact de l’événement, toujours sur une échelle de 0 à 1 (0,0 = aucun impact, et 1,0 = perte totale d’exploitation).
La dernière colonne indique le produit de la probabilité (Likelihood) multipliée par l’impact. On obtient ainsi le « facteur de pondération du risque ». Les situations présentant le facteur de pondération du risque le plus élevé sont à inscrire dans le plan de reprise d’activité après sinistre. Voici des exemples de traitement des risques :
- Prévenir – événements à probabilité et à impact élevés (tenter activement de les limiter)
- Accepter – événements à probabilité et à impact faibles (rester vigilant)
- Limiter – événements à probabilité élevée et à impact faible (réduire leur probabilité de survenue)
- Transférer – événements à probabilité moyenne et à impact moyen à élevé (transférer le risque à un tiers, comme une compagnie d’assurances)
- Planifier – événements à probabilité faible et à impact élevé (planifier les mesures à prendre en cas de survenue)
Corréler BIA et RA
Une fois l’analyse d’impact et l’évaluation des risques terminées, l’étape suivante consiste à corréler les données de ces activités dans un tableau (ou sous une autre forme) qui illustre les menaces et les impacts critiques pour l’entreprise que représente chaque risque. Ce tableau inclut en outre l’objectif de délai de récupération (RTO, recovery time objective). Cette métrique développée à partir de la BIA indique pendant combien de temps un système ou un processus peut rester indisponible avant que cela empêche l’entreprise de fonctionner normalement. Le tableau 2 ci-dessous à droite illustre l’une des façons de présenter les résultats de la BIA et de la RA dans un rapport destiné à la direction.

Pour résumer, l’analyse d’impact et l’évaluation des risques sont des activités primordiales associées à la création et à la gestion de programmes de reprise d’activité après sinistre technologique. Le recours à des services dans le cloud donne lieu à de nouvelles formes d’analyse, qui ne s’appuient plus systématiquement sur les datacenters. Lors du développement d’un plan de reprise d’activité après sinistre, il est essentiel de se familiariser avec les risques informatiques, notamment en ce qui concerne les services cloud, ainsi que leur incidence sur les opérations de l’entreprise.
Pour approfondir sur PRA, Reprise après incident
-
![]()
AIOps : 6 façons d’utiliser l’IA pour la reprise d’activité après incident
Par: Stuart Burns
-
![]()
Planifier la reprise d’activité après un incident : les 11 étapes clés
Par: Brien Posey
-
![]()
Cyberhebdo du 6 février 2026 : comme un air de reprise dans la douleur
-
![]()
Continuité des activités dans le cloud : avantages, enjeux et conseils
Par: Brien Posey



