L'essentiel sur Proxem, pionner français de la reconnaissance sémantique et du Deep Learning
L'entreprise, fondée il y a 10 ans, est devenue experte en AI appliquée à l'analyse sémantique de « données textuelles ». Sa R&D - à la base de 30 publications scientifiques - lui permet aujourd'hui d'appliquer la discipline bien au-delà de l'analyse d'avis de consommateurs.

« L'AI c'est comme le sexe chez les adolescents : tout le monde en parle, mais cela reste souvent très théorique », blague François-Régis Chaumartin président et fondateur de Proxem, sur la scène d'une des salles de conférence de Big Data Paris 2018.
La plaisanterie rappelle que derrière le buzzword et l'AI-Washing (la fausse intelligence artificielle), la "vraie" Intelligence Artificielle est une histoire « de maths purs ». Proxem est bien placé pour en parler. Bien que de taille modeste (une trentaine de personne), la société maitrise sa technologie de bout en bout.
 AI et Deep Learning : des maths, encore des maths
AI et Deep Learning : des maths, encore des maths
Transformer les textes en données utilisables
Fondé en 2007, Proxem édite un outil SaaS pour « non Geek » (Proxem Studio) - « utilisable par les métiers, de manière autonome », sans son assistance ou aide d'un expert consultant - qui prend « tout type de corpus » pour transformer du texte en données.
Le but est de faire apparaitre des faits ou des tendances cachées dans les contenus écrits, et d'aider ainsi les entreprises à prendre des décisions sur la base de grandes quantités de texte.
« Aujourd'hui, 80% des données disponibles sont dans du texte », contextualise François-Régis Chaumartin. « C'est logique. Les machines échangent des datas. Lorsque nous, humains, nous échangeons des mots dans des mails, des pages web, des CV, des brevets, des offres d'emplois, des avis, des verbatims juridiques... et des appels d'offres ».
Techniquement sa solution est hébergée sur le Cloud de Microsoft. Elle s'appuie sur un mélange de briques open-source (MongoDB, ElasticSearch) et propriétaire (.NET). Le service est également disponible via une API Rest.
Faire simple est compliqué
La simplicité de la promesse de Proxem - structurer une donnée sémantique non structurée - n'est qu'apparente. Elle cache de réels défis technologiques et mathématiques. « Nous oublions souvent que nous avons épuisé la patience de nos parents pendant trois à quatre ans avant d'apprendre à parler. Et que nous avons étudié quinze ans avant de savoir faire un résumé ».
Les analogies avec l'évolution du cerveau des enfants et avec l'apprentissage scolaire expliquent bien pourquoi le domaine de Proxem - la connaissance et la compréhension sémantique - se rattache à une des parties les plus "dures" de l'AI, notamment le fameux Deep Learning.
La maturité technologique de l'analyse sémantique ouvre de nouveaux champs
Initialement, Proxem faisait de l'analyse d'avis clients postés sur les sites webs ou les réseaux sociaux. Depuis, l'entreprise a étendu son champs d'action aux Ressources Humaines (évaluation de ressenti des salariés via l'analyse des entretiens annuels, des baromètres sociaux, etc.) et à la veille (analyse d'un marché).
L'évolution de l'offre traduit également, en creux, les progrès de la R&D sous-jacente.
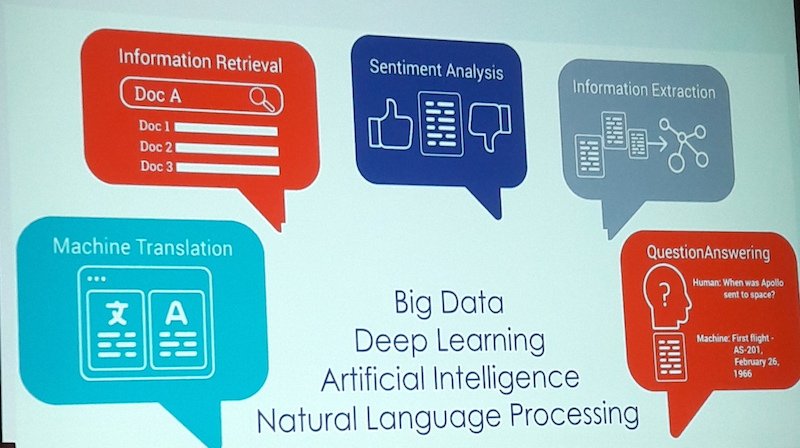 Les domaines d'application de Proxem
Les domaines d'application de Proxem
« Aujourd'hui, la technologie a atteint une maturité suffisante pour automatiser des taches qui échappaient totalement au domaine de l'automatisation », assure François-Régis Chaumartin.
Cette maturité technologique ouvre de nouveaux champs à l'analyse sémantique. Désormais, moyennant une phase d'apprentissage et de « tuning », Proxem Studio peut s'attaquer en théorie à tout type de documents écrits, dans tout type de domaine.
« Et cela marche », se réjouit un représentant de Thalès qui l'utilise pour pré-analyser les appels d'offres et « mâcher le travail des juristes senior ».
Pionnier du Deep Learning et de l'AI
Parmi les différentes parties de l'AI (Cognitif, Machine Learning, etc.), le Deep Learning est un domaine sur lequel Proxem a développé une expertise propre depuis déjà quatre ans (que ce soit dans les réseaux de neurones profonds, multicouches, à convolution, ou récurrents, etc.).
L'apprentissage profond est bien adapté à l'analyse sémantique. Il reprend les mêmes techniques « que ce que fait notre vieux cerveau humain », explique François-Régis Chaumartin, c'est à dire « de l'afférence en contexte ».
 Afférence en contexte
Afférence en contexte
Pour préciser ce point, le co-fondateur s'appuie une case de la BD des Schtroumpfs. « Quand nous lisons "C'est schtroumpfant à la fin : Chaque fois que je lève ma brouette, il pleut !", nous allons inférer le fait que "schtroumpfant" signifie "agaçant" ou "énervant". L'apprentissage profond sur corpus permet justement, de cette même manière, de sortir des concepts que l'on peut ensuite valider très vite ».
Mais le Deep Learning n'est qu'une partie du processus de connaissance sémantique. Proxem utilise en fait des systèmes mixtes.
« Nous croyons dans les systèmes hybrides », confirme le président de l'éditeur. En clair, Proxem commence par de l'apprentissage sur corpus, (« mais bien fait », tient-il à souligner, une chose qui ne serait « pas si simple que cela »). Ensuite, à partir de ce résultat, Proxem fait du clustering dynamique. Puis vient le travail de l'humain. « Un chef de projet infolinguiste de chez nous va dialoguer avec les métiers de façon à faire quelques allers retours ».
De cette manière, Proxem construit dynamiquement le thésaurus, l'ontologie ou la taxonomie « sur mesure » (sic) pour traiter le problème « associé aux extracteurs d'informations qui vont bien ».
Dans la pratique, la durée de ce genre de projet se compte en semaines, un délai nécessaire pour avoir « un très bon niveau de couverture avec à la fois un bon rappel et une bonne précision ».
La R&D continue
Plus généralement, Proxem a semble-t-il beaucoup travaillé sur l'apprentissage à partir de corpus au-delà du milliard de mots, typiquement en s'appuyant sur Wikipedia, sur des actualités, sur des avis de consommateurs, voire sur des romans. « Cela nous permet de capturer des modèles vectoriels de langue », précise François-Régis Chaumartin.
En revanche, quand il s'agit de travailler sur un corpus réduit (quelques dizaines de milliers de pages), Proxem étudie aujourd'hui des technologies à base d'Adaptative Learning et de Transfert Learning. « L'idée est de tordre l'espace - c'est de la topologie - pour faire en sorte que tout ce que nous avons appris dans une langue puisse s'appliquer sur un corpus beaucoup plus petit ».
Pas question, là encore, pour « le pionnier en France de l'application de l'AI à la compréhension du texte », de se reposer sur des services tiers. « C'est vraiment de la R&D de pointe ».
En Marche vers l'international
Proxem génère un CA de €2 millions. En 10 ans, la société a mené 130 projets pour une quarantaine de clients, principalement des sociétés du CAC 40. Mais l'évolution du produit permet aussi de répondre à des cas plus particuliers. Ce fut le cas du mouvement "En Marche !", lors de l'élection présidentielle de 2017. Le parti du futur Président Macron a utilisé Proxem Studio pour synthétiser les retours de ses enquêtes terrains auprès des électeur.

La société possède plusieurs brevets. Elle consacre 30% de ses revenus à la R&D ce qui lui a permis de faire une trentaine de publications scientifiques.
Après deux levées de fonds en 2016, Proxem en prévoit une troisième en 2018 pour s'attaquer à l'international et aux leaders du marché - dont la canadien Provalis.
Pour approfondir sur Big Data et Data lake
-
![]()
Machine learning : à l’ère de l’IA agentique, Snowflake termine (enfin) ses fondations
Par: Gaétan Raoul
-
![]()
ModernBERT : Answer.ai et LightOn acollent un turbo à BERT
Par: Gaétan Raoul
-
![]()
« Petit » lexique de l’IA générative : les grands modèles de langage
Par: Gaétan Raoul
-
![]()
CRM : l’Intelligence artificielle devient indispensable, mais elle ne remplace pas un bon commercial



