Qu'est-ce que la reconnaissance des entités nommées (NER) ?
La reconnaissance des entités nommées (NER pour Named Entity Recognition) est une méthode de traitement du langage naturel (NLP) qui permet d'extraire des informations d'un texte. La reconnaissance des entités nommées consiste à détecter et à classer les informations importantes contenues dans un texte, appelées entités nommées. Les entités nommées font référence aux sujets clés d'un texte, tels que les noms, les lieux, les entreprises, les événements et les produits, ainsi que les thèmes, les sujets, les temps, les valeurs monétaires et les pourcentages.
Le NER est également appelé extraction, regroupement et identification d'entités. Il est utilisé dans de nombreux domaines de l'intelligence artificielle (IA), notamment l'apprentissage automatique, l'apprentissage profond et les réseaux neuronaux. La NER est un composant clé des systèmes de NLP, tels que les chatbots, les outils d'analyse des sentiments et les moteurs de recherche. Il est utilisé dans les domaines de la santé, de la finance, des ressources humaines, de l'assistance à la clientèle, de l'enseignement supérieur et de l'analyse des médias sociaux.

Quel est l'objectif du NER ?
Le NER identifie, catégorise et extrait les éléments d'information les plus importants d'un texte non structuré sans nécessiter d'analyse humaine fastidieuse. Elle est particulièrement utile pour extraire rapidement des informations clés à partir de grandes quantités de données, car elle automatise le processus d'extraction.
Le NER fournit aux entreprises des informations essentielles sur leurs clients, leurs produits, leurs concurrents et les tendances du marché. Par exemple, les entreprises l'utilisent pour détecter quand elles sont mentionnées dans des publications. Les prestataires de soins de santé l'utilisent pour extraire des informations médicales clés des dossiers des patients.
À mesure que les modèles NER améliorent leur capacité à identifier correctement les informations importantes, ils contribuent à améliorer les systèmes d'intelligence artificielle en général. Ces systèmes améliorent les capacités de compréhension du langage de l'IA dans des domaines tels que les systèmes de résumé et de traduction et la capacité des systèmes d'IA à analyser le texte.
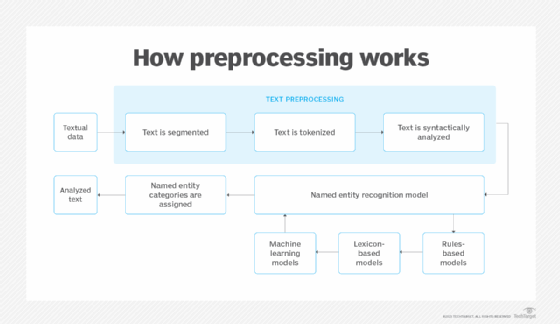
Comment fonctionne le NER ?
Le NER utilise des algorithmes basés sur la grammaire, des modèles statistiques de NLP et des modèles prédictifs. Ces algorithmes sont entraînés sur des ensembles de données étiquetés avec des catégories d'entités nommées prédéfinies, telles que les personnes, les lieux, les organisations, les expressions, les pourcentages et les valeurs monétaires. Les catégories sont identifiées par des abréviations ; par exemple, LOC est utilisé pour les lieux, PER pour les personnes et ORG pour les organisations.
Une fois formé aux données textuelles et aux types d'entités, un modèle d'apprentissage NER analyse automatiquement les nouveaux textes non structurés, en catégorisant les entités nommées et la signification sémantique sur la base de sa formation. Lorsque la catégorie d'information d'un morceau de texte est reconnue, un utilitaire d'extraction d'information extrait les informations liées à l'entité nommée et construit un document lisible par une machine que d'autres outils peuvent traiter pour en extraire le sens.

Quels sont les quatre types de NER ?
Les quatre types de systèmes NER les plus utilisés sont les suivants :
- Les systèmes basés sur l'apprentissage automatique supervisé utilisent des modèles d'apprentissage automatique formés sur des textes que les humains ont pré-étiquetés avec des catégories d'entités nommées. Les approches d'apprentissage automatique supervisé utilisent des algorithmes tels que les champs aléatoires conditionnels et l'entropie maximale, deux modèles de langage statistiques complexes. Cette méthode est efficace pour analyser les significations sémantiques et d'autres complexités, bien qu'elle nécessite d'importants volumes de données d'apprentissage.
- Les systèmes basés sur des règles utilisent des règles pour extraire des informations. Les règles peuvent inclure des majuscules ou des titres, tels que "Dr". Cette méthode nécessite une intervention humaine importante pour la saisie, le contrôle et l'ajustement des règles, et elle peut manquer des variations textuelles qui ne sont pas incluses dans ses annotations d'apprentissage. On pense que les systèmes basés sur des règles ne gèrent pas la complexité aussi bien que les modèles d'apprentissage automatique.
- Les systèmes basés sur un dictionnaire utilisent un dictionnaire doté d'un vocabulaire étendu et d'une collection de synonymes pour effectuer des vérifications croisées et identifier les entités nommées. Cette méthode peut avoir des difficultés à classer les entités nommées dont l'orthographe varie.
- Les systèmes d'apprentissage profond sont les plus précis des quatre. L'utilisation de réseaux neuronaux, tels que les réseaux neuronaux récurrents et les architectures de transformateurs, pour examiner la syntaxe et la sémantique des structures de phrases. Cette approche est considérée comme une amélioration par rapport à l'apprentissage automatique traditionnel, car elle permet de mieux traiter les grands ensembles de données textuelles et d'apprendre automatiquement les caractéristiques et les attributs des données d'entrée.
Méthodes NER
Il existe plusieurs méthodes pour mettre en œuvre les NER. Chacune d'entre elles est un type d'outil formé pour effectuer des tâches de NER spécifiques. La meilleure description de ces méthodes est la suivante :
- Systèmes d'apprentissage automatique non supervisés. Ces modèles utilisent des systèmes d'apprentissage automatique qui ne sont pas déjà formés sur des données textuelles annotées. Les modèles d'apprentissage non supervisés sont considérés comme capables de traiter des tâches de NER plus complexes que les systèmes supervisés.
- Systèmes d'amorçage. Également connus sous le nom d'autosupervision, ces systèmes classent les entités nommées en fonction de caractéristiques grammaticales, telles que les majuscules, les parties du discours et d'autres catégories pré-entraînées et prédéfinies. Une personne affine ensuite le système bootstrap, en étiquetant ses prédictions comme correctes ou incorrectes et en ajoutant les prédictions correctes à un nouvel ensemble d'apprentissage.
- Systèmes de réseaux neuronaux. Ils construisent un modèle NER à l'aide de réseaux neuronaux, de modèles d'apprentissage à architecture bidirectionnelle, tels que BERT (Bidirectional Encoder Representations from Transformers), et de techniques d'encodage. Cette approche minimise l'interaction humaine.
- Systèmes statistiques. Ces systèmes utilisent des modèles probabilistes formés sur des modèles et des relations textuels pour prédire les entités nommées dans de nouvelles données textuelles d'entrée.
- Systèmes d'étiquetage des rôles sémantiques. Ceux-ci prétraitent un modèle NER avec des techniques d'apprentissage sémantique pour lui enseigner le contexte et les relations entre les catégories.
- Les systèmes hybrides. Ils utilisent des aspects de plusieurs systèmes dans une approche combinée.

Qui utilise les NER ?
Diverses industries et applications utilisent la NER de différentes manières. Chaque cas d'utilisation simplifie la recherche et l'extraction d'informations importantes à partir de gros volumes de données, ce qui permet de consacrer du temps à des tâches plus utiles. Voici quelques exemples :
- Chatbots. L'IA générative d'OpenAI, ChatGPT, Bard de Google et d'autres chatbots utilisent des modèles NER pour identifier les entités pertinentes mentionnées dans les requêtes et les conversations des utilisateurs. Cela leur permet de comprendre le contexte de la question de l'utilisateur et d'améliorer les réponses du chatbot.
- Soutien à la clientèle. Les NER organisent les commentaires et les plaintes des clients par nom de produit et identifient les plaintes courantes ou tendancielles concernant des produits spécifiques ou des succursales. Cela aide les équipes d'assistance à la clientèle à se préparer aux demandes entrantes, à y répondre plus rapidement et à mettre en place des systèmes automatisés qui dirigent les clients vers les services d'assistance et les sections des pages de la FAQ qui les intéressent.
- Finance. NER extrait des chiffres des marchés privés, des prêts et des rapports sur les bénéfices, ce qui augmente la rapidité et la précision de l'analyse de la rentabilité et du risque de crédit. NER extrait également les noms et les entreprises mentionnés dans les médias sociaux et autres publications en ligne, aidant ainsi les institutions financières à surveiller les tendances et les développements qui pourraient affecter les prix des actions.
- Soins de santé. Les outils NER extraient des informations essentielles des rapports de laboratoire et des dossiers médicaux électroniques des patients, aidant ainsi les prestataires de soins de santé à réduire leur charge de travail, à analyser les données plus rapidement et avec plus de précision, et à améliorer les soins.
- L'enseignement supérieur. NER permet aux étudiants, aux chercheurs et aux professeurs de résumer rapidement des volumes d'articles et de documents d'archives, ainsi que de trouver des sujets, des thèmes et des thèmes pertinents.
- RH. Ces systèmes rationalisent le recrutement et l'embauche en résumant les CV des candidats et en extrayant des informations telles que les qualifications, la formation et les références. Le NER filtre également les plaintes et les demandes des employés vers les services concernés, ce qui permet d'organiser les flux de travail internes.
- Les médias. Les fournisseurs d'informations utilisent le NER pour analyser les nombreux articles et messages des médias sociaux qu'ils doivent lire et pour classer le contenu en fonction des informations importantes et des tendances. Cela les aide à comprendre rapidement les nouvelles et les événements actuels et à en rendre compte.
- Moteurs de recommandation. De nombreuses entreprises utilisent la NER pour améliorer la pertinence de leurs moteurs de recommandation. Par exemple, des sociétés comme Netflix utilisent les RCE pour analyser les recherches et l'historique de visionnage des utilisateurs afin de fournir des recommandations personnalisées.
- Moteurs de recherche. La NER aide les moteurs de recherche à identifier et à classer les sujets mentionnés sur le web et dans les recherches. Cela permet aux plateformes de recherche de comprendre la pertinence des sujets par rapport à la recherche d'un utilisateur et de fournir à ce dernier des résultats précis.
- Analyse des sentiments. Le NER est un élément clé de l'analyse des sentiments. Il extrait les noms de produits, les marques et d'autres informations mentionnées dans les commentaires des clients, les messages des médias sociaux et d'autres textes non structurés. L'outil d'analyse des sentiments analyse ensuite les informations pour déterminer les sentiments de l'auteur à l'égard d'un produit, d'une entreprise ou d'un autre sujet. La NER est également utilisée pour analyser le sentiment des employés dans les réponses aux enquêtes et les plaintes.
Avantages et défis des NER
Les NER présentent plusieurs avantages et défis.
Avantages du NER
La reconnaissance des entités nommées offre une série d'avantages lorsqu'elle est utilisée de manière appropriée :
- Automatise l'extraction d'informations à partir de grandes quantités de données.
- Analyse des informations clés dans un texte non structuré.
- Facilite l'analyse des tendances émergentes.
- Élimine l'erreur humaine dans l'analyse.
- Il est utilisé dans presque toutes les industries.
- Libère du temps pour que les employés puissent effectuer d'autres tâches.
- Améliore la précision des tâches et des processus de la PNL.
NER challenges
Les NER posent également leur propre série de problèmes :
- A des difficultés à analyser les ambiguïtés lexicales, la sémantique et l'évolution des usages de la langue dans les textes.
- Il se heurte à des problèmes de variations orthographiques.
- Ne connaît pas tous les mots étrangers.
- Peut avoir des problèmes avec les textes parlés, comme les conversations téléphoniques.
- Cela conduit à ce que de nombreux modèles de NER à la pointe de la technologie présentent des mesures de performance limitées.
- Peut nécessiter de grandes quantités de données d'apprentissage ou une intervention humaine importante.
- Les résultats peuvent être faussés si l'algorithme de ML comporte des biais cachés.
Bonnes pratiques NER
Les entreprises doivent suivre un ensemble de bonnes pratiques lors de la formation, de l'utilisation et de la maintenance de leurs systèmes de NER. Ces pratiques sont les suivantes
- Utiliser les bons outils. Différents fournisseurs proposent des outils adaptés aux tâches de NER. Il s'agit notamment de modèles de langage et de bibliothèques tels que BERT, Stanford NER tagger, Natural Language Toolkit (NLTK) et SpaCy.
- Étiqueter et annoter clairement les données. Il est important de définir clairement les types d'entités et de disposer d'un système d'annotation que les modèles de NER respecteront lorsqu'ils effectueront des tâches. Cela est nécessaire lors de la préparation des données utilisées pour entraîner les modèles de NER.
- Ingénierie des caractéristiques. Pour affiner un modèle de NER, l'ingénierie des caractéristiques est utilisée pour fournir des caractéristiques importantes, telles que l'étiquetage de la partie du discours et l'intégration des mots. Elle permet également de représenter les mots sous forme de valeurs numériques afin que les systèmes informatiques puissent les traiter et les comprendre dans leur contexte.
- Évaluation continue du modèle. Une réévaluation continue des modèles NER est nécessaire après leur mise en œuvre. Par exemple, l'analyse des performances au fil du temps pour identifier les erreurs permet de déterminer les domaines à améliorer.
Natural Language Toolkit vs. SpaCy
NLTK et SpaCy sont deux programmes de NER présentant des différences uniques. NLTK est basé sur la bibliothèque NLP de Python et fournit plusieurs algorithmes. NLTK est souvent utilisé pour enseigner le TAL aux débutants, ainsi qu'aux chercheurs qui créent des applications à partir de la base. Il utilise des chaînes de caractères comme entrées et sorties dans le prétraitement. Il permet la tokenisation, le stemming, le marquage de la partie du discours et l'analyse syntaxique, et peut être entraîné sur des données personnalisées.
SpaCy, en revanche, est un logiciel libre qui utilise un algorithme de troncature unique adapté à des tâches concrètes. Il est souvent utilisé pour construire des applications NLP professionnelles et est orienté objet dans le prétraitement. SpaCy est également capable de traiter de grands volumes de données, d'extraire les relations entre les entités et de prendre en charge les vecteurs de mots. Il est considéré comme plus rapide que NLTK.
La reconnaissance des entités nommées est un élément essentiel du traitement du langage naturel. Découvrez comment le NLP améliore l'analyse des entreprises.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que l'apprentissage profond (Deep Learning) et comment fonctionne-t-il ?
Par: Ed Burns
-
![]()
Qu'est-ce que le fractionnement des données ?
Par: Alexander Gillis
-
![]()
Qu'est-ce que l'apprentissage automatique (AutoML) ?
Par: Ben Lutkevich
-
![]()
Qu'est-ce que l'apprentissage par renforcement ?
Par: Joseph Carew



