Qu'est-ce que la science des données (Data Science) ? Le guide ultime

La science des données (data science) est le domaine qui consiste à appliquer des techniques d'analyse avancées et des principes scientifiques afin d'extraire des informations précieuses à partir de données pour la prise de décisions commerciales, la planification stratégique et d'autres utilisations. Elle revêt une importance croissante pour les entreprises : les informations générées par la science des données aident les organisations à accroître leur efficacité opérationnelle, à identifier de nouvelles opportunités commerciales et à améliorer leurs programmes de marketing et de vente, entre autres bénéfices. En fin de compte, elles peuvent leur procurer des avantages concurrentiels par rapport à leurs rivaux.
La science des données englobe diverses disciplines, telles que l'ingénierie des données, la préparation des données, l'exploration de données, l'analyse prédictive, l'apprentissage automatique et la visualisation des données, ainsi que les statistiques, les mathématiques et la programmation logicielle. Elle est principalement pratiquée par des scientifiques des données (data scientists) qualifiés, bien que des analystes de données de niveau inférieur puissent également y participer. De plus, de nombreuses organisations s'appuient désormais en partie sur des data scientists citoyens, un groupe qui peut inclure des professionnels de la veille économique (BI), des analystes commerciaux, des utilisateurs professionnels avertis en matière de données, des ingénieurs de données et d'autres travailleurs qui n'ont pas de formation officielle en science des données.
Ce guide complet sur la science des données explique plus en détail ce qu'elle est, pourquoi elle est importante pour les organisations, comment elle fonctionne, les avantages commerciaux qu'elle apporte et les défis qu'elle pose. Vous y trouverez également un aperçu des applications, des outils et des techniques de la science des données, ainsi que des informations sur le travail des scientifiques des données et les compétences dont ils ont besoin. Tout au long du guide, des hyperliens renvoient vers des articles TechTarget connexes qui approfondissent les sujets abordés ici et offrent des informations et des conseils d'experts sur les initiatives en matière de science des données.
Pourquoi la science des données est-elle importante ?
La science des données joue un rôle important dans pratiquement tous les aspects des opérations et des stratégies commerciales. Par exemple, elle fournit des informations sur les clients qui aident les entreprises à créer des campagnes marketing plus efficaces et des publicités ciblées afin d'augmenter les ventes de produits. Elle facilite la gestion des risques financiers, la détection des transactions frauduleuses et la prévention des pannes d'équipement dans les usines de fabrication et autres environnements industriels. Elle aide à bloquer les cyberattaques et autres menaces de sécurité dans les systèmes informatiques.
D'un point de vue opérationnel, les initiatives en matière de science des données peuvent optimiser la gestion des chaînes d'approvisionnement, des stocks de produits, des réseaux de distribution et du service à la clientèle. À un niveau plus fondamental, elles ouvrent la voie à une efficacité accrue et à une réduction des coûts. La science des données permet également aux entreprises d'élaborer des plans business et des stratégies fondés sur une analyse éclairée du comportement des clients, des tendances du marché et de la concurrence. Sans elle, les entreprises risquent de manquer des occasions et de prendre des décisions erronées.
La science des données est également essentielle dans des domaines autres que les opérations commerciales courantes. Dans le secteur de la santé, elle est utilisée notamment pour le diagnostic médical, l'analyse d'images, la planification des traitements et la recherche médicale. Les établissements universitaires utilisent la science des données pour suivre les performances des étudiants et améliorer leur marketing auprès des futurs étudiants. Les équipes sportives analysent les performances des joueurs et planifient leurs stratégies de jeu grâce à la science des données. Les agences gouvernementales et les organismes chargés des politiques publiques en sont également de grands utilisateurs.
Processus et cycle de vie de la science des données
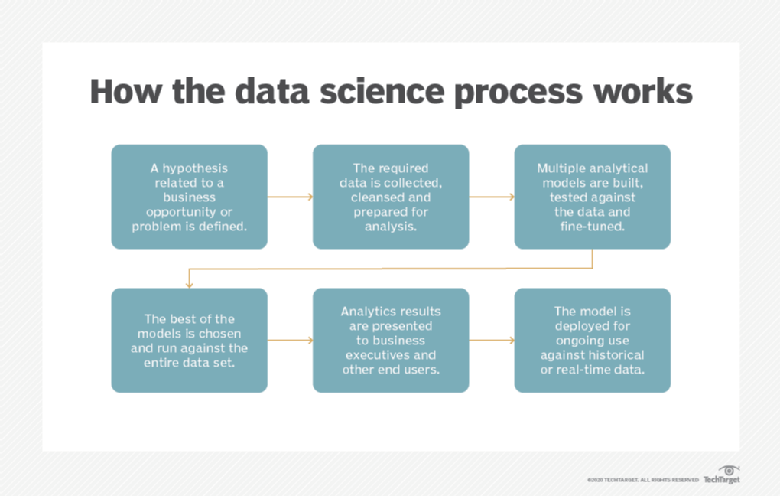
Les projets liés à la science des données impliquent une série d'étapes de collecte et d'analyse des données. Dans un article décrivant le processus de la science des données, Donald Farmer, directeur du cabinet de conseil en analyse TreeHive Strategy, a présenté les six étapes principales suivantes :
- Identifier une hypothèse liée à l'entreprise à tester.
- Recueillir les données et les préparer pour l'analyse.
- Tester différents modèles analytiques.
- Choisir le meilleur modèle et appliquez-le aux données.
- Présenter les résultats aux dirigeants d'entreprise.
- Déployer le modèle pour une utilisation continue avec des données récentes.
M. Farmer a déclaré que ce processus fait effectivement de la science des données une entreprise scientifique. Cependant, il a écrit que dans les entreprises, le travail lié à la science des données « sera toujours plus utile s'il se concentre sur des réalités commerciales simples » qui peuvent profiter à l'entreprise. Par conséquent, a-t-il ajouté, les scientifiques des données devraient collaborer avec les parties prenantes commerciales sur des projets tout au long du cycle de vie de l'analyse.
Bénéfices de la science des données
Lors d'un webinaire organisé en octobre 2020 par l'Institut des sciences computationnelles appliquées de l'université Harvard, Jessica Stauth, directrice générale chargée de la science des données au sein de l'unité Fidelity Labs de Fidelity Investments, a déclaré qu'il existait « un lien très clair » entre le travail dans le domaine de la science des données et les résultats commerciaux. Elle a cité plusieurs avantages commerciaux potentiels, notamment un retour sur investissement plus élevé, une croissance des ventes, des opérations plus efficaces, une mise sur le marché plus rapide et un engagement et une satisfaction accrus des clients.
De manière générale, l'un des principaux avantages de la science des données est de faciliter et d'améliorer la prise de décision. Les organisations qui investissent dans ce domaine peuvent intégrer des données quantifiables et factuelles dans leurs décisions commerciales. Idéalement, ces décisions fondées sur les données permettront d'améliorer les performances commerciales, de réduire les coûts et de fluidifier les processus et les flux de travail.
Les avantages commerciaux spécifiques de la science des données varient en fonction de l'entreprise et du secteur d'activité. Dans les organisations en contact direct avec la clientèle, par exemple, la science des données aide à identifier et à affiner les publics cibles. Les services marketing et commerciaux peuvent exploiter les données clients pour améliorer les taux de conversion et créer des campagnes marketing personnalisées et des offres promotionnelles qui génèrent des ventes plus importantes.
Dans d'autres cas, les avantages comprennent une réduction de la fraude, une gestion des risques plus efficace, des transactions financières plus rentables, une augmentation du temps de fonctionnement des installations de fabrication, une meilleure performance de la chaîne logistique, des protections de cybersécurité renforcées et de meilleurs résultats pour les patients. La science des données permet également d'analyser les données en temps réel au fur et à mesure qu'elles sont générées. Découvrez les avantages de l'analyse en temps réel, notamment une prise de décision plus rapide et une plus grande agilité commerciale, dans un autre article de Farmer.
Applications et cas d'utilisation de la science des données
Les applications courantes auxquelles s'adonnent les scientifiques des données comprennent la modélisation prédictive, la reconnaissance de formes, la détection d'anomalies, la classification, la catégorisation et l'analyse des sentiments, ainsi que le développement de technologies telles que les moteurs de recommandation, les systèmes de personnalisation et les outils d'intelligence artificielle (IA) comme les chatbots et les véhicules et machines autonomes.
Ces applications donnent lieu à une grande variété de cas d'utilisation dans les organisations, notamment les suivants :
- analyse client
- détection des fraudes
- gestion des risques
- négociation d'actions
- publicité ciblée
- personnalisation du site web
- service à la clientèle
- maintenance prédictive
- logistique et gestion de la chaîne d'approvisionnement
- reconnaissance d'images
- reconnaissance vocale
- traitement du langage naturel
- cybersécurité
- diagnostic médical
Découvrez huit applications phares de la science des données et leurs cas d'utilisation dans un article rédigé par Ronald Schmelzer, analyste principal et associé directeur chez Cognilytica, un cabinet de recherche et de conseil spécialisé dans l'IA.
Les défis de la science des données
La science des données est intrinsèquement difficile en raison de la nature avancée des analyses qu'elle implique. Les énormes quantités de données généralement analysées ajoutent à la complexité et augmentent le temps nécessaire à la réalisation des projets. De plus, les scientifiques des données travaillent souvent avec des pools de mégadonnées qui peuvent contenir une variété de données structurées, non structurées et semi-structurées, ce qui complique encore davantage le processus d'analyse.

L'un des plus grands défis consiste à éliminer les biais dans les ensembles de données et les applications analytiques. Cela inclut les problèmes liés aux données sous-jacentes elles-mêmes et ceux que les scientifiques des données intègrent inconsciemment dans les algorithmes et les modèles prédictifs. Si ces biais ne sont pas identifiés et corrigés, ils peuvent fausser les résultats analytiques, conduisant à des conclusions erronées qui entraînent des décisions commerciales malavisées. Pire encore, ils peuvent avoir un impact néfaste sur certains groupes de personnes, par exemple dans le cas des biais raciaux dans les systèmes d'IA.
Trouver les bonnes données à analyser est un autre défi. Dans un rapport publié en janvier 2020, l'analyste Afraz Jaffri de Gartner et quatre de ses collègues du cabinet de conseil ont également cité le choix des bons outils, la gestion du déploiement des modèles analytiques, la quantification de la valeur commerciale et la maintenance des modèles comme des obstacles importants.
Découvrez quatre bonnes pratiques pour les projets de science des données afin de surmonter les défis dans un article rédigé par Yujun Chen et Dawn Li, deux scientifiques des données chez Finastra, une société de services de développement logiciel.
Que font les scientifiques des données et quelles compétences doivent-ils posséder ?
Le rôle principal des scientifiques des données consiste à analyser des données, souvent en grande quantité, afin de trouver des informations utiles pouvant être partagées avec les dirigeants d'entreprise, les chefs d'entreprise et les employés, ainsi qu'avec les fonctionnaires, les médecins, les chercheurs et bien d'autres encore. Les scientifiques des données créent également des outils et des technologies d'IA destinés à être déployés dans diverses applications. Dans les deux cas, ils collectent des données, développent des modèles analytiques, puis entraînent, testent et exécutent les modèles sur les données.
Par conséquent, les scientifiques des données doivent posséder à la fois des compétences en préparation de données, en exploration de données, en modélisation prédictive, en apprentissage automatique, en analyse statistique et en mathématiques, ainsi qu'une expérience des algorithmes et du codage, par exemple des compétences en programmation dans des langages tels que Python, R et SQL. Beaucoup sont également chargés de créer des visualisations de données, des tableaux de bord et des rapports pour illustrer les résultats des analyses.

Outre ces compétences techniques, les data scientists doivent posséder un ensemble de compétences plus générales, notamment des connaissances commerciales, de la curiosité et un esprit critique. Une autre compétence importante est la capacité à présenter les informations tirées des données et à expliquer leur importance d'une manière facile à comprendre pour les utilisateurs professionnels. Cela inclut la capacité à raconter des histoires à partir des données, en combinant des visualisations de données et du texte narratif dans une présentation préparée à l'avance.
Pour plus d'informations sur les compétences indispensables en science des données, consultez l'article de Kathleen Walch, autre analyste principale et associée directrice chez Cognilytica.
Équipe chargée de la science des données
De nombreuses organisations ont créé une ou plusieurs équipes distinctes pour gérer les activités liées à la science des données. Comme l'explique Mary K. Pratt, rédactrice spécialisée dans les technologies, dans un article consacré à la mise en place d'une équipe dédiée à la science des données, une équipe efficace ne se compose pas uniquement de scientifiques des données. Elle peut également inclure les postes suivants :
- Ingénieur de données. Ses responsabilités comprennent la mise en place de pipelines de données et l'aide à la préparation des données et au déploiement de modèles, en étroite collaboration avec les scientifiques de données.
- Analyste de données. Il s'agit d'un poste de niveau inférieur destiné aux professionnels de l'analyse qui ne possèdent pas le niveau d'expérience ou les compétences avancées des scientifiques des données.
- Ingénieur en apprentissage automatique. Ce poste axé sur la programmation consiste à développer les modèles d'apprentissage automatique nécessaires aux applications de science des données.
- Développeur en visualisation de données. Cette personne travaille avec des scientifiques des données pour créer des visualisations et des tableaux de bord utilisés pour présenter les résultats d'analyses aux utilisateurs professionnels.
- Traducteur de données. Également appelé traducteur analytique, il s'agit d'un nouveau poste qui sert de liaison avec les unités commerciales et aide à planifier les projets et à communiquer les résultats.
- Architecte de données. Un architecte de données conçoit et supervise la mise en œuvre des systèmes sous-jacents utilisés pour stocker et gérer les données à des fins d'analyse.
L'équipe est généralement dirigée par un directeur de la science des données, un responsable de la science des données ou un scientifique en chef des données, qui peut rendre compte soit au directeur des données, soit au directeur de l'analyse, soit au vice-président de l'analyse ; le poste de scientifique en chef des données est un autre poste de direction qui a fait son apparition dans certaines organisations. Certaines équipes de science des données sont centralisées au niveau de l'entreprise, tandis que d'autres sont décentralisées dans des unités commerciales individuelles ou ont une structure hybride qui combine ces deux approches.
Business intelligence vs science des données
Tout comme la science des données, l'intelligence économique et le reporting de base visent à orienter la prise de décision opérationnelle et la planification stratégique. Mais la BI se concentre principalement sur l'analyse descriptive : que s'est-il passé ou que se passe-t-il actuellement qui nécessite une réponse ou une intervention de la part de l'organisation ? Les analystes BI et les utilisateurs BI en libre-service travaillent principalement avec des données transactionnelles structurées extraites des systèmes opérationnels, nettoyées et transformées pour les rendre cohérentes, puis chargées dans un entrepôt de données ou un data mart à des fins d'analyse. Le suivi des performances, des processus et des tendances de l'entreprise est un cas d'utilisation courant de la BI.
La science des données implique des applications analytiques plus avancées. Outre l'analyse descriptive, elle englobe l'analyse prédictive, qui prévoit les comportements et les événements futurs, ainsi que l'analyse prescriptive, qui cherche à déterminer la meilleure ligne de conduite à adopter face au problème analysé.
Les types de données non structurées ou semi-structurées (par exemple, les fichiers journaux, les données de capteurs et les textes) sont courants dans les applications de science des données, tout comme les données structurées. De plus, les scientifiques des données souhaitent souvent accéder aux données brutes avant qu'elles ne soient nettoyées et consolidées afin de pouvoir analyser l'ensemble des données ou les filtrer et les préparer pour des utilisations analytiques spécifiques. Par conséquent, les données brutes peuvent être stockées dans un lac de données basé sur Hadoop, un service de stockage d'objets dans le cloud, une base de données NoSQL ou une autre plateforme de mégadonnées.
Technologies, techniques et méthodes liées à la science des données
La science des données repose largement sur les algorithmes d'apprentissage automatique. L'apprentissage automatique est une forme d'analyse avancée dans laquelle des algorithmes apprennent à partir d'ensembles de données, puis recherchent des modèles, des anomalies ou des informations dans ces ensembles. Il utilise une combinaison de méthodes d'apprentissage supervisé, non supervisé, semi-supervisé et par renforcement, les algorithmes recevant différents niveaux de formation et de supervision de la part des scientifiques des données.
Il existe également le deep learning, une branche plus avancée du machine learning qui utilise principalement des réseaux neuronaux artificiels pour analyser de grands ensembles de données non étiquetées. Dans un autre article, M. Schmelzer, de Cognilytica, explique la relation entre la science des données, le machine learning et l'IA, en détaillant leurs différentes caractéristiques et la manière dont ils peuvent être combinés dans des applications analytiques.
Les modèles prédictifs constituent une autre technologie fondamentale de la science des données. Les scientifiques des données les créent en appliquant des algorithmes d'apprentissage automatique, d'exploration de données ou statistiques à des ensembles de données afin de prédire des scénarios commerciaux et des résultats ou comportements probables. Dans la modélisation prédictive et d'autres applications analytiques avancées, l'échantillonnage des données est souvent utilisé pour analyser un sous-ensemble représentatif de données. Il s'agit d'une technique d'exploration de données conçue pour rendre le processus d'analyse plus facile à gérer et moins chronophage.
Les techniques statistiques et analytiques couramment utilisées dans les projets de science des données comprennent les suivantes :
- classification, qui sépare les éléments d'un ensemble de données en différentes catégories ;
- régression, qui trace les valeurs optimales des variables de données connexes sur une ligne ou un plan ; et
- le regroupement, qui rassemble des points de données présentant une affinité ou des attributs communs.

Outils et plateformes de science des données
De nombreux outils sont à la disposition des scientifiques des données pour le processus d'analyse, notamment des options commerciales et open source :
- plateformes de données et moteurs d'analyse, tels que Spark, Hadoop et les bases de données NoSQL ;
- langages de programmation, tels que Python, R, Julia, Scala et SQL ;
- outils d'analyse statistique tels que SAS et IBM SPSS ;
- plateformes et bibliothèques d'apprentissage automatique, notamment TensorFlow, Weka, Scikit-learn, Keras et PyTorch ;
- Jupyter Notebook, une application web permettant de partager des documents contenant du code, des équations et d'autres informations ; et
- outils et bibliothèques de visualisation de données, tels que Tableau, D3.js et Matplotlib.
De plus, les éditeurs de logiciels proposent un ensemble varié de plateformes de science des données dotées de caractéristiques et de fonctionnalités différentes. Cela comprend des plateformes d'analyse pour les data scientists expérimentés, des plateformes d'apprentissage automatique automatisées qui peuvent également être utilisées par les data scientists amateurs, ainsi que des hubs de workflow et de collaboration pour les équipes de science des données. La liste des fournisseurs comprend Alteryx, AWS, Databricks, Dataiku, DataRobot, Domino Data Lab, Google, H2O.ai, IBM, Knime, MathWorks, Microsoft, RapidMiner, SAS Institute, Tibco Software et d'autres.
Pour plus d'informations sur les meilleurs outils et plateformes de science des données, consultez l'article du rédacteur technique Pratt.
Carrières dans la science des données
À mesure que la quantité de données générées et collectées par les entreprises augmente, leur besoin en data scientists s'accroît également. Cela a entraîné une forte demande en travailleurs ayant une expérience ou une formation en science des données, ce qui rend difficile pour certaines entreprises de pourvoir les postes disponibles.
Dans une enquête menée en 2020 par Kaggle, une filiale de Google qui gère une communauté en ligne pour les scientifiques des données, 51 % des 2 675 répondants employés comme scientifiques des données ont déclaré être titulaires d'un master, tandis que 24 % étaient titulaires d'une licence et 17 % d'un doctorat. De nombreuses universités proposent désormais des programmes de premier cycle et de deuxième cycle en science des données, qui peuvent constituer une voie directe vers l'emploi.
Une autre voie professionnelle consiste à former des personnes occupant d'autres postes pour qu'elles deviennent des scientifiques des données, une option très prisée par les organisations qui ont du mal à trouver des candidats expérimentés. Outre les programmes universitaires, les futurs scientifiques des données peuvent participer à des stages intensifs et suivre des cours en ligne sur des sites éducatifs tels que Coursera et Udemy. Divers fournisseurs et groupes industriels proposent également des cours et des certifications en science des données, et des quiz en ligne permettent de tester et d'acquérir des connaissances de base dans ce domaine.
En décembre 2020, le site Glassdoor, spécialisé dans la recherche d'emploi et les avis sur les entreprises, indiquait un salaire de base moyen de 113 000 dollars pour les data scientists aux États-Unis, avec une fourchette allant de 83 000 à 154 000 dollars ; le salaire moyen d'un data scientist senior était de 134 000 dollars. Sur le site d'emploi Indeed, les salaires moyens étaient de 123 000 dollars pour un data scientist et de 153 000 dollars pour un data scientist senior.
Comment les industries s'appuient sur la science des données
Avant de devenir eux-mêmes des fournisseurs de technologies, Google et Amazon ont été parmi les premiers à utiliser la science des données et l'analyse des mégadonnées pour des applications internes, tout comme d'autres entreprises Internet et de commerce électronique telles que Facebook, Yahoo et eBay. Aujourd'hui, la science des données est largement répandue dans toutes sortes d'organisations. Voici quelques exemples de son utilisation dans différents secteurs :
- Divertissement. La science des données permet aux services de streaming de suivre et d'analyser ce que regardent les utilisateurs, ce qui aide à déterminer les nouvelles séries télévisées et les nouveaux films à produire. Des algorithmes basés sur les données sont également utilisés pour créer des recommandations personnalisées en fonction de l'historique de visionnage d'un utilisateur.
- Services financiers. Les banques et les sociétés émettrices de cartes de crédit exploitent et analysent les données afin de détecter les transactions frauduleuses, de gérer les risques financiers liés aux prêts et aux lignes de crédit, et d'évaluer les portefeuilles clients afin d'identifier les opportunités de vente incitative.
- Santé. Les hôpitaux et autres prestataires de soins de santé utilisent des modèles d'apprentissage automatique et d'autres composants liés à la science des données pour automatiser l'analyse des radiographies et aider les médecins à diagnostiquer les maladies et à planifier les traitements en fonction des résultats obtenus précédemment chez d'autres patients.
- Fabrication. Les applications de la science des données chez les fabricants comprennent l'optimisation de la gestion de la chaîne d'approvisionnement et de la distribution, ainsi que la maintenance prédictive pour détecter les défaillances potentielles des équipements dans les usines avant qu'elles ne se produisent.
- Commerce de détail. Les détaillants analysent le comportement des clients et leurs habitudes d'achat afin de proposer des recommandations personnalisées et des publicités, des campagnes marketing et des promotions ciblées. La science des données les aide également à gérer leurs stocks de produits et leurs chaînes d'approvisionnement afin de maintenir les articles en stock.
- Transport. Les entreprises de livraison, les transporteurs de fret et les prestataires de services logistiques utilisent la science des données pour optimiser les itinéraires et les horaires de livraison, ainsi que les meilleurs modes de transport pour les expéditions.
- Voyages. La science des données aide les compagnies aériennes à optimiser la planification des vols, la gestion des équipages et le remplissage des avions. Des algorithmes permettent également de fixer des tarifs variables pour les vols et les chambres d'hôtel.
D'autres utilisations de la science des données, dans des domaines tels que la cybersécurité, le service à la clientèle et la gestion des processus opérationnels, sont courantes dans différents secteurs. Un exemple de cette dernière utilisation est l'aide au recrutement des employés et à l'acquisition de talents : l'analyse permet d'identifier les caractéristiques communes des meilleurs éléments, de mesurer l'efficacité des offres d'emploi et de fournir d'autres informations utiles au processus de recrutement.

Histoire de la science des données
Dans un article publié en 1962, le statisticien américain John W. Tukey écrivait que l'analyse des données « est intrinsèquement une science empirique ». Quatre ans plus tard, Peter Naur, pionnier danois de la programmation informatique, proposait la datalogie, « la science des données et des processus de données », comme alternative à l'informatique. Il utilisa plus tard le terme « science des données » dans son ouvrage publié en 1974, Concise Survey of Computer Methods, le décrivant comme « la science du traitement des données », mais toujours dans le contexte de l'informatique et non de l'analyse.
En 1996, la Fédération internationale des sociétés de classification a inclus la science des données dans le nom de la conférence qu'elle a organisée cette année-là. Dans une présentation lors de cet événement, le statisticien japonais Chikio Hayashi a déclaré que la science des données comprend trois phases : « la conception des données, la collecte des données et l'analyse des données ». Un an plus tard, C. F. Jeff Wu, professeur d'université aux États-Unis né à Taïwan, a proposé que les statistiques soient rebaptisées « science des données » et que les statisticiens soient appelés « scientifiques des données ».
Découvrez 13 ouvrages consacrés à la science des données qui vous permettront d'approfondir vos connaissances sur les enjeux, les outils et les techniques dans ce domaine.
L'informaticien américain William S. Cleveland a défini la science des données comme une discipline analytique à part entière dans un article intitulé « Data Science: An Action Plan for Expanding the Technical Areas of Statistics » (La science des données : un plan d'action pour élargir les domaines techniques des statistiques), publié en 2001 dans l'International Statistical Review. Deux revues scientifiques consacrées à la science des données ont vu le jour au cours des deux années suivantes.
La première utilisation du titre professionnel de « data scientist » est attribuée à DJ Patil et Jeff Hammerbacher, qui ont décidé conjointement de l'adopter en 2008 alors qu'ils travaillaient respectivement chez LinkedIn et Facebook. En 2012, un article de la Harvard Business Review coécrit par Patil et l'universitaire américain Thomas Davenport qualifiait le métier de data scientist de « métier le plus sexy du XXIe siècle ». Depuis lors, la science des données n'a cessé de gagner en importance, en partie grâce à l'utilisation croissante de l'IA et de l'apprentissage automatique dans les organisations.
L'avenir de la science des données
À mesure que la science des données devient de plus en plus répandue dans les organisations, les data scientists citoyens devraient jouer un rôle plus important dans le processus d'analyse. Dans son rapport Magic Quadrant 2020 sur les plateformes de science des données et d'apprentissage automatique, Gartner indique que la nécessité de prendre en charge un large éventail d'utilisateurs de la science des données est « de plus en plus la norme ». L'une des conséquences probables est l'utilisation accrue de l'apprentissage automatique, y compris par des data scientists expérimentés qui cherchent à rationaliser et à accélérer leur travail.
Approfondissez vos connaissances dans ce domaine en suivant ces blogs consacrés à la science des données.
Gartner a également mentionné l'émergence des opérations d'apprentissage automatique (MLOps), un concept qui adapte les pratiques DevOps issues du développement logiciel dans le but de mieux gérer le développement, le déploiement et la maintenance des modèles d'apprentissage automatique. Les méthodes et outils MLOps visent à créer des flux de travail standardisés afin que les modèles puissent être planifiés, construits et mis en production plus efficacement.
Parmi les autres tendances qui auront une incidence sur le travail des scientifiques des données à l'avenir, citons la pression croissante en faveur d'une IA explicable, qui fournit des informations permettant aux gens de comprendre le fonctionnement des modèles d'IA et d'apprentissage automatique et de déterminer dans quelle mesure ils peuvent se fier à leurs conclusions pour prendre des décisions, ainsi que l'accent mis sur les principes d'une IA responsable, conçus pour garantir que les technologies d'IA sont équitables, impartiales et transparentes.
Pour approfondir sur IA appliquée, GenAI, IA infusée
-
![]()
Qu'est-ce que la data science ? Le guide ultime
Par: Craig Stedman
-
![]()
Les 14 compétences les plus recherchées en science des données pour réussir
Par: Kathleen Walch
-
![]()
Qu'est-ce que la régression logistique ?
Par: Ed Burns
-
![]()
Qu'est-ce que la détection d'anomalies ? Présentation et explication
Par: George Lawton



