Dossier Stockage : les technologies clés pour 2011 (1ère partie)
Comme l'an passé, LeMagIT ouvre sa collection de dossiers par un tour d'horizon des technologies de stockage qui devraient compter en 2011. Au programme de cette première partie, hiérachisation des données, réduction des données et Scale-out NAS.

| Sommaire du dossier |
|
Optimiser le stockage a été l’un des maîtres-mots des deux dernières années et au vu des prédictions d’IDC en matière de croissance des volumes de données dans les entreprises, les administrateurs de stockage peuvent se préparer à poursuivre sur cette voie pour les années à venir. La bonne nouvelle est qu’une large partie des optimisations qu’ils devaient jusqu’alors opérer manuellement est de plus en plus assumée par les baies de stockage elles-mêmes et que de nouvelles technologies devraient se généraliser en 2011 à commencer par la hiérarchisation automatique des données (Automated Tiering), la réduction des données primaires (déduplication et compression).
Pour faire face à la croissance des données non structurées, de nouvelles approches du NAS basée sur le cluster à grande échelle sont aussi en train d’émerger comme l’attestent les rachats en 2009 et 2010 de pionniers tels qu’Ibrix (HP), Isilon (EMC),Exanet (Dell) … Ces approches promettent de pouvoir accroitre la capacité et la performance des NAS linéairement avec les besoins par simple ajout de nœuds additionnels au cluster.
Du côté de la virtualisation et du cloud, plusieurs casse-têtes restent à régler comme celui du choix des protocoles à utiliser. NFS a gagné du terrain en 2010 sur les protocoles blocs et devrait poursuivre sur sa lancée en 2011. La question de la sauvegarde des environnements virtuels reste également un sujet sensible.
Enfin, le cloud storage commence à émerger et devrait aussi être une des tendances à suivre en 2011 (même si nous y reviendrons de façon plus large dans un prochain dossier au printemps).
1. 2011 : Année de la hiérarchisation automatique de données.
La hiérarchisation des données n’est pas une nouveauté. Dans les années 90, une technologie Mainframe comme DFHSM avait déjà introduit des notions de hiérarchisation de données (selon des critères d’âge et de performance). Les données stockées sur disque pouvaient par exemple être migrées sur une librairie de bande externe après une certaine période. En 2004, Nicolas Couraud, à l’époque Directeur du Technology Solution Group d’EMC (aujourd’hui patron de la SSII Newrun), justifiait ainsi l'approche d'IBM : "le HSM faisait de la hiérarchisation de stockage à une époque ou le Gigaoctet était hors de prix en environnement mainframe". La hiérachisation de données modernes s'appuyant largement sur des disques SSD encore très coûteux, on ne peut s'empêcher de faire le parallèle (même si rien ne dit que l'arrivée de SSD abordables ne renverra pas à terme les mécanismes de hiérachisation à la remise...).
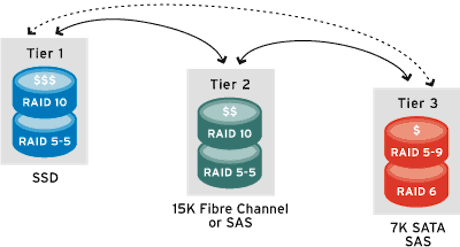
Le concept de la hierarchisation de données expliqué par Compellent
Dans la pratique, la hiérarchisation de données version 2011 reprend certains principes du HSM mais de façon bien plus sophistiquée et surtout de façon bien plus granulaire. De plus, les mouvements de données restent (pour l'instant) limités à la baie. L’idée est que les systèmes de stockage modernes ont l’intelligence nécessaire pour déplacer automatiquement des blocs de données d’une classe de stockage à une autre en fonction des règles établies par l’administrateur. C’est par exemple le cas des baies Storage Center de Compellent mais également de plusieurs baies IBM (dotées de la fonction easy tiering), des baies Clariion CX4, VNX et Symmetrix d’EMC ou des systèmes de stockages VSP d'Hitachi Data Systems.
Avec la généralisation de la virtualisation, du Thin provisionning et du tiering automatique, il est aujourd’hui possible de constituer des pools de stockage hybrides combinant par exemple un espace de stockage SSD, un espace de disques SAS et un espace de disques SATA. Pour une application typique, un volume sera composé de 5% d’espace disque SSD, de 25% de disques SAS rapides et de 70% de disques SATA et le tiering automatique se chargera du déplacement automatique des données entre ces différentes classes.
 Richard Villars, IDC : "Nous en sommes aux premiers stades de la hiérarchisation de données"
Richard Villars, IDC : "Nous en sommes aux premiers stades de la hiérarchisation de données"
L’émergence des SSD est une incitation majeure à l’utilisation de la hiérarchisation automatique des données. Un disque SSD coûte environ 10 fois plus cher qu’un disque traditionnel et il est assez difficile pour la plupart des applications de justifier son coût dans le cadre d’un usage statique. Le tiering automatique, en rendant dynamique le positionnement des données assure que la classe de service SSD est utilisée à son plein potentiel. Au passage, cette optimisation permet de réduire le nombre de disques FC dans la baie au profit de plus de disques SATA, ce qui permet d’optimiser les coûts, mais aussi la consommation électrique de la baie. Bref, les bénéfices du tiering sont multiples. Il est à noter que le niveau de granularité dans la gestion des blocs par les mécanismes de tiering varie d’un constructeur à l’autre. Compellent est ainsi capable de gérer des pages de données de 512 Ko, 2Mo et 4 Mo, tandis que la technologie Fast des Clariion procède par bloc de 1Go et que celle des Symmetrix (Fast VP) fonctionne par page de 8Mo. Le Tiering dynamique d’Hitachi fonctionne quant à lui sur des pages de 42 Mo.
En savoir plus
Une vidéo de Compellent expliquant le concept de la hiérachisation de données.
Un billet de blog sur l'impact du tiering et du cache sur les performances d'une baie Clariion
La technologie de tiering appliquée aux postes de travail par Marvell
A ce jour, les fonctions de hiérarchisation de données ne s’appliquent qu’à l’échelle d’une baie, mais l’on peut envisager qu’elles s’étendront à terme à plusieurs baies. D’ailleurs HDS a annoncé le support du tiering automatique pour les baies tierces depuis son contrôleur virtualisé VSP pour 2011. «Nous en sommes aux premiers stades", explique Richard Villars, vice-président, systèmes de stockage d’IDC. "Il y a deux ans, le Thin provisioning était vu comme une chose risquée. Aujourd’hui c’est une exigence de fait, en particulier dans les environnements virtualisés. Je pense qu’il va en être de même pour la hiérarchisation automatique des données et que l’évolution va se faire sur un cycle similaire au cours des deux prochaines années ".
2. La réduction des données s'attaque au stockage primaire
Comme en 2010, les technologies de réduction de données devraient être un sujet fort pour les administrateurs de stockage. D’autant que les grands constructeurs ont multiplié les rachats et les développements dans ce secteur pour pouvoir intégrer ces technologies à leurs offres. Après le rachat de Data Domain par EMC en 2009, Dell a acquis cette année Ocarina Networks et IBM a racheté le spécialiste de la compression de données primaires Storwize. EMC, de son côté, a annoncé l’intégration de la compression dans ses Clariion, Celerra et VNX, tandis que Hewlett-Packard affichait son intention d’étendre sa technologie de déduplication StoreOnce à son offre de stockage NAS X9000 ainsi qu’à son offre de sauvegarde. Dans le même temps, Permabit Technology a aussi noué des accords OEM pour son logiciel de déduplication intégrée avec BlueArc et Xiotech, tandis que Hitachi signait avec Falconstor.
Si la plupart de ces acteurs sont aujourd’hui à même d’offrir la déduplication pour la sauvegarde, 2011 devrait marquer l’entrée en force des technologies de réduction de données dans le stockage primaire. Ainsi , on attend des annonces en ce sens de Dell (Compellent prévoit notamment d’apporter la déduplication à ses baies dans le courant du premier semestre) et IBM. De même, HP devrait proposer StoreOnce sur ses NAS dans le courant de l’été. NetApp, qui propose la déduplication primaire sur ses baies depuis 2007, a aussi ajouté une nouvelle corde à son arc en novembre 2010 avec l'intégration de la compression dans son OS OnTap 8.01.
Compression et déduplication sont complémentaires. Comme l’explique Brian Garrett, le vice-président d’ESG Lab. "La première réduit la taille des données tandis que l'autre [déduplication] fonctionne sur des morceaux redondants. » Les effets peuvent être différents. La déduplication fournit ses meilleurs résultats lorsque l’on stocke fréquemment les même données au fil du temps (scénario de backup, de poste de travail virtualisés…). La compression fait un meilleur travail sur les applications où les données se répètent peu et où la faible latence est un critère important, ce qui est le cas des bases de données et de la messagerie.
3. Le Scale-out NAS
La technologie de Scale-out NAS (ou clustered NAS) a longtemps été une technologie à la recherche d’un problème. Mais l’explosion du volume des données non structurées lui permet aujourd’hui d’apparaître comme la solution pour le stockage des millions de fichiers qui s’accumulent aujourd’hui dans les entreprises. Le Scale-out NAS répond aussi aux besoins spécifiques de certains secteurs verticaux comme les médias, le monde du calcul numérique, la simulation biomédicale…
Face à l’explosion du volume de données non structurées, nombre d’entreprises se sont pour l’instant contentées de multiplier les îlots de serveurs NAS. Il n’est pas rare, chez certains grands comptes, de trouver des dizaines, voire des centaines de NAS autonomes. Problème : aucun de ces NAS n’a été conçu pour être intégré avec les autres au sein d’un espace de stockage unifié, d’où un vrai casse-tête d’administration et une explosion des coûts de gestion de ces serveurs NAS.
Dans un premier temps, les constructeurs ont espéré résoudre ce problème en misant sur les appliances de virtualisation de NAS. L’idée de base était intéressante : il s’agissait d’insérer une ou plusieurs appliances en frontal des multiples serveurs NAS afin de les intégrer dans un espace de nommage global (Global NameSpace), mais aussi de faciliter au passage les migrations et déplacements de données entre ilôts autrefois disparates. Séduit par le concept, EMC a ainsi racheté Rainfinity, tandis que Brocade mettait la main sur NuView pour créer StorageX. F5 Networks a, de son côté, acquis Acopia et créé la gamme ARX, tandis que Cisco s’emparait de NeoPath Networks.
Tous ces rachats, effectués entre 2005 et 2007, n’ont toutefois pas connu le succès espéré, et ce sont finalement les technologies de cluster NAS qui semblent vouloir prendre le relais. Ces architectures présentent l’avantage de permettre l’utilisation de composants banalisés - dans la pratique des serveurs x86 bourrés de disques ou reliés à de simples piles de disques (ou JBOD) - pour assembler des systèmes NAS de grande capacité à des prix au Go défiant toute concurrence. Un autre avantage est leur évolutivité. Si l’on désire plus de performances ou de capacité, il suffit de rajouter des nœuds au cluster. Chaque serveur additionnel adjoint au cluster lui ajoute en effet de nouveaux ports d’entrée/sorties, ainsi qu’une capacité additionnelle. En général, capacité et performances augmentent quasi-linéairement avec le nombre de nœuds dans le cluster - la linéarité dépendant notamment du type de systèmes, de l’efficacité du logiciel et du type de connexions utilisées au sein du cluster.
 Un cluster NAS Isilon
Un cluster NAS Isilon
L’un des premiers grands constructeurs à se rallier au concept a été HP, qui a acquis PolyServe en février 2007 et en a fait le cœur de sa baie StorageWorks 9100 Extreme Data Storage. HP a ensuite délaissé Polyserve au profit d’IBrix une autre technologie de scale-out NAS bien plus aboutie et intégrée aujourd’hui à ses NAS StorageWorks X9000. IBM s’est lui aussi intéressé dès 2008 au marché des grands NAS. Big Blue a ainsi construit une offre aujourd’hui baptisée SoNAS (Scale-Out NAS) en réunissant ses technologies de systèmes de fichiers en cluster GPFS, avec un développement maison permettant d’exposer la capacité ainsi agrégée via des protocoles de partage de fichier standards (technologie dite SoFS). En février 2010, Dell a racheté les actifs technologiques d’Exanet, actifs que l’on devrait sans doute voir renaître au sein d’une solution de cluster NAS signée Dell dans le courant 2011. Mais le plus gros rachat est celui opéré par EMC sur Isilon, l’un des pionniers et des leaders du secteur. Un système Isilon IQ peut ainsi agréger jusqu’à 144 nœuds et un total de plus de 10 Po de données au sein d’un système de fichier unique.
A suivre aussi
Gluster, une solution de scale-out NAS libre
Le retour de Symantec sur le marché des appliances avec son Scale-out NAS FileStore (avec Huawei)
Active Circle, un acteur français sur le segment du scale-out NAS
Il est à noter que la montée en puissance des grands NAS doit certes beaucoup à l’explosion des données non structurées, mais qu’elle est aussi tirée par l’intérêt des grands opérateurs, hébergeurs et fournisseurs de services pour des infrastructures de stockage partagé NFS à même de soutenir l’expansion de leurs fermes de serveurs virtualisés. Comme le notait Brett Helsel, le patron de la technologie d’Isilon, lors d’une visite au siège de la société en novembre, NFS se prête aussi bien au déploiement d’infrastructures virtualisées à grande échelle : « Il y a encore un an, 85 % des déploiements VMware se faisaient sur des architectures blocs. En 2010, on ne devrait pas être loin de 55%. Ce qui veut dire que les 45% restants se font maintenant sur NFS, donc sur des protocoles fichiers ». Bref, les grands NAS viennent aussi chasser sur le terrain des baies SAN en mode bloc pour les infrastructures virtualisées.
Pour approfondir sur SAN et NAS
-
![]()
Comprendre la différence entre SDS et virtualisation du stockage
Par: Paul Kirvan
-
![]()
Les NAS de Pure Storage se reconfigurent désormais « en temps réel »
Par: Yann Serra
-
![]()
Stockage : IBM ajoute la déduplication à Spectrum Virtualize et à ses baies Storwize
Par: Christophe Bardy
-
![]()
Reduxio lève 32 M$ additionnels pour sa technologie de stockage originale
Par: Christophe Bardy



