fotogestoeber - Fotolia
MariaDB : une plateforme pour rapprocher les données transactionnelles de leur traitement analytique
L’éditeur open source a décidé de connecter étroitement les données de son système transactionnel à sa solution analytique pour faciliter les cas d’usage hybride, dit HTAP.

MariaDB plus proche du translytique. L’éditeur de la base de données open source a présenté une plateforme dont la vocation est de créer des passerelles très étroites entre les bases transactionnelles et analytiques du groupe pour répondre aux usages hybrides dits HTAP (Hybrid Transactional / Analytical Processing). Objectif : rapprocher les données historiques transactionnelles de leurs traitements analytiques. Un moteur de recommandation peut être un cas d’usage type.
Au lieu de créer une unique base, cette MariaDB Platform a été conçue pour que les données soient d’abord synchronisées d’un socle transactionnel (MariaDB TX) où les données sont stockées en ligne, vers un socle analytique (MariaDB AX) où les données sont stockées en colonnes. Puis, et c’est la seconde fonction qui la prépare aux usages HTAP, la société a développé une moteur de requête intelligent qui route les requêtes, transactionnelles ou analytiques, vers le traitement adapté. MaxScale prend en charge ce routage, comme le laisse entrevoir l’architecture de la plateforme.
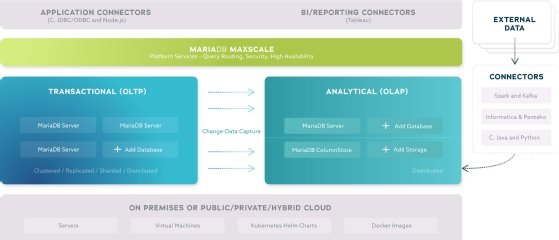
La synchronisation repose sur un module de CDC (Change-Data-Capture) qui sert à répliquer les données de MariaDB TX vers AX. « Tous les inserts, les mises à jour et les suppressions de données sur le stockage en ligne sont automatiquement appliqués au stockage en colonne pour l’analytique », explique Shane Johnson, directeur en charge du Marketing Produit chez MariaDB.
En fait, CDC garantit que « toutes les données transactionnelles soient disponibles pour l'analytique, et ce, sans délai (souvent en quelques secondes) », ajoute le responsable. Toutefois, toutes les données ne transitent pas nécessairement. « Le DBA peut spécifier quelles données sont répliquées dans le stockage en colonnes. Dans de nombreux cas, il n’est pas pratique de répliquer toutes les tables, en particulier celles comportant un petit nombre de lignes. Ainsi, le DBA peut déterminer quelles tables doivent être répliquées dans le stockage en colonnes et celles qui ne doivent pas l'être. »
Les données sont stockées sur disque. Pour des cas d’usage liés au HTAP, plusieurs éditeurs mettent quant à eux en avant leurs technologies de base In-Memory, censées accélérer l’accès et les traitements analytiques. C’est notamment le cas d’AeroSpike, ou encore de GridGain ou Redis Labs.
« De nombreuses bases de données transactionnelles ne peuvent stocker que quelques mois de données. C'est particulièrement vrai pour les bases de données stockant des données en colonnes et en mémoire. Il n'y a tout simplement pas assez de mémoire pour stocker des années de données », rappelle-t-il.
Mais pour MariaDB, le stockage en mémoire n’est pas « une nécessité », reprend Shane Johnson, qui estime « efficace et rentable » le stockage sur disque. Toutefois, ajoute-t-il, le stockage en mémoire peut être utilisé pour la partie analytique « quand cela est possible », mais « ce n’est pas un prérequis ».
« Le stockage en colonne cache en mémoire autant de données que possible mais cela n’est pas indispensable. Si le système dispose de suffisamment de mémoire pour contenir l’ensemble du jeu de données, celui-ci sera alors stocké à la fois sur disque et en mémoire », résume-t-il. Ce stockage en mémoire, pour la partie analytique (stockage en colonnes donc) est également ce qui permet d’éviter les problèmes de performances… et la mise en place d’un étage de caching supplémentaire. De plus, les données sont répliquées du système transactionnel vers l’analytique de façon asysnchrone, comme un système primaire répliquerait ses données sur un système secondaire pour garantir de la haute-disponibilité, souligne encore le responsable.
Cette mécanique est également applicable dans un environnement hybride dans lequel, par exemple, les données transactionnelles seraient conservées sur site et répliquées dans le cloud sur un système en colonnes.
Pour approfondir sur Open Source
-
![]()
LTAP : la réponse de Databricks aux limites des systèmes translytiques (HTAP)
Par: Gaétan Raoul
-
![]()
Au nom de l’IA agentique, MariaDB prépare le rachat de Gridgain
Par: Gaétan Raoul
-
![]()
Recherche vectorielle : MariaDB veut détrôner les bases de données spécialisées
Par: Gaétan Raoul
-
![]()
MariaDB officialise son introduction en bourse
Par: Gaétan Raoul