Puces IA : Nvidia détaille sa prochaine génération Rubin au CES
Entre le GPU Rubin, le processeur Vera et les nouveaux contrôleurs réseau, ce ne sont pas moins de six nouvelles puces que Nvidia lancera sur le marché des centres de calcul d’ici à la rentrée prochaine.

Nvidia profite du salon CES qui se tient cette semaine à Las Vegas pour détailler les caractéristiques de sa prochaine génération de puces Rubin pour les centres de calcul, et les équipements qui iront autour : les switches réseau Spectrum-6, les cartes réseau ConnextX-9 côté calcul et BlueField-4 côté stockage, ou encore les clusters DGX dont les nœuds de calcul seront interconnectés via un nouveau réseau NVLink-6.
Chacun de ses éléments repose sur une puce conçue par Nvidia. Si l’on ajoute le processeur ARM Vera qui accompagnera dans les serveurs une paire de GPU Rubin, les nouvelles puces que Nvidia s’apprête à lancer d’ici à la rentrée prochaine seront donc au nombre de six.
Les caractéristiques de ces puces correspondent à une évolution linéaire de la génération Blackwell que Nvidia commercialise actuellement. Mais plusieurs détails semblent montrer que la génération Rubin a plus particulièrement été optimisée pour fonctionner chez les grands fournisseurs de services d’IA en cloud.
En substance, les consommations d’énergie ne sont pas mentionnées et les puces réseau évoluent pour supporter et isoler des milliers d’utilisateurs simultanés. Accessoirement, Nvidia parle à plusieurs reprises dans ses communiqués de matériels conçus pour réduire le coût des tokens, lesquels ne sont facturés qu’en cloud.
Outre les puces détaillées ici et qui sont conçues pour les équipements de centres de calcul (le fournisseur parle « d’usines d’IA »), Nvidia doit aussi lancer une carte accélératrice Rubin CPX censée prendre place dans des machines d’appoint, pour l’inférence uniquement.
Il existera a priori des versions du processeur Rubin sous forme de carte PCIe, avec sans doute moins de mémoires HBM, dont on pourra installer jusqu’à huit exemplaires dans des serveurs x86 conventionnels.
À ce stade, on ignore sur quoi débouchera le rapprochement, à Noël, entre Nvidia et l’équipe de la startup Groq qui a mis au point une puce accélératrice LPU pour l’inférence particulièrement économe en énergie (à ne pas confondre avec Grok, l’IA d’Elon Musk). Les annonces faites par Nvidia lors du CES constituent un avant-goût de celles qu’il fera lors de son événement annuel GTC, qui doit se tenir en mars prochain à San José.
Rubin : 17,5 pétaflops en FP8 pour l’entraînement des IA

Le GPU Rubin est censé délivrer une puissance de calcul de 50 pétaflops en précision FP4-sparse, mais cette caractéristique est assez controversée puisque cela correspond à des calculs effectués sur des résultats trop arrondis. Il faut plutôt s’intéresser à la puissance annoncée de 17,5 pétaflops en FP8 qui servira à entraîner les IA les plus fiables.
On comprend que le GPU Rubin serait donc presque quatre fois plus performant que l’actuel GPU Blackwell B200 de Nvidia (4,5 pétaflops en FP8). Précisons toutefois que, selon les arrondis de Nvidia, le B200 a une puissance annoncée de 5 pétaflops en FP8. Si le gain de performances exprimé par Nvidia avec un facteur « 3,5x » est plus fiable, alors la puissance réelle de Rubin sera peut-être plutôt de 15,75 pétaflops en FP8.
Toujours est-il que le gain de performances entre les deux générations sera principalement dû à l’intégration dans la puce d’une nouvelle mémoire HBM4 de 288 Go, qui offre une bande passante de 22 To/s, soit environ 1,5 fois plus de capacité pour 2,75 plus de vitesse que la mémoire HBM3e du B200 (192 Go en 8 To/s).
Nvidia ne communique pas encore sur la consommation électrique (ni la dissipation de chaleur, ce qui revient au même) de Rubin. S’il est confirmé qu’il sera finalement gravé avec la même finesse de 3 nm que l’actuel B200 (1400W), alors il sera probablement plus énergivore.
Vera : un nouveau processeur ARM avec des cœurs propriétaires

Le processeur Vera disposera de 88 cœurs « Olympus ». A priori, Nvidia abandonne les cœurs génériques Neoverse, que l’on trouve sur les processeurs ARM mis au point par les hyperscalers AWS, Azure et GCP, pour un design de cœur ARM maison, comme le fait désormais Ampere sur les processeurs qu’il vend à Oracle pour son cloud OCI.
Le bénéfice de ce design est que les cœurs accepteront désormais d’exécuter deux threads à la fois (comme les x86), soit 176 flux d’instructions simultanés au lieu de 72 threads sur 72 cœurs pour l’actuel processeur Grace. En revanche, tous ces processeurs ARM, Neoverse ou non, sont compatibles puisqu’ils exécutent tous le même jeu d’instruction Arm v9.
Le cache L2 de chaque cœur passe de 1 à 2 Mo et le cache L3, partagé entre tous, passe de 114 Mo à 162 Mo. La mémoire associée à la puce reste de la LPDDR5X, mais sa capacité peut grimper à 1,5 To contre 480 Go sur le processeur Grace. Le processeur Vera communique avec sa RAM à la vitesse de 1,2 To/s, contre 512 Go/s précédemment.
Enfin, Vera gérera des extensions en PCIe 6.0 a priori deux fois plus rapide que le PCIe 5.0 de Grace. L’intérêt du PCIe 6.0 sera a priori le support du protocole CXL 3.1, qui permet au processeur d’utiliser la RAM et les SSD NVMe d’un autre serveur comme s’il s’agissait des siens. À cette fin, Nvidia a racheté en septembre dernier la startup Enfabrica, spécialisée dans les contrôleurs CXL.
NVLink 6 : une puce pour transférer 28,8 To/s entre deux GPU d’un cluster
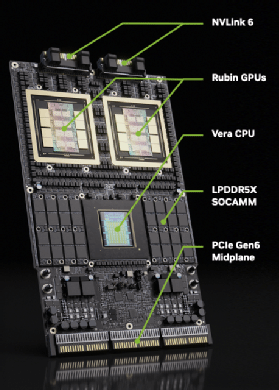
Deux GPU Rubin communiquent à la vitesse de 3,6 To/s dans les deux sens (soit jusqu’à 7,2 To/s au total) via leur bus NVLink, tandis que la vitesse de communication entre un processeur Vera et un GPU Rubin est de 1,8 To/s dans chaque sens. Rappelons que le bus NVLink, propriétaire de Nvidia, permet à deux composants de partager le même adressage mémoire : le processeur Vera a accès aux données situées dans la mémoire HBM d’un GPU Rubin et un GPU Rubin a accès aux données situées dans la mémoire HBM d’un autre GPU Rubin ou dans la mémoire LPDDR5X accolée à un processeur Vera.
Brancher deux puces ensemble à un moment ou à un autre est la fonction de la puce de commutation NVLink, dont la nouvelle version NVLink 6 supporte de router 28,8 To/s (soit quatre communications) depuis et vers 72 puces Nvidia adressables, que celles-ci soient situées ou non dans des serveurs différents.

Nvidia va a priori conserver l’actuel design NVL72 pour ses clusters de serveurs. Celui-ci correspond à une baie rack de 18 serveurs physiques, contenant chacun deux nœuds de calcul, et chaque nœud de calcul se compose d’un processeur ARM connecté à deux GPU. Si la connexion NVLink entre les puces d’un même nœud est assurée par un chipset interne, celle entre les nœuds de calcul relève d’une collection de switches basés, donc, sur ces fameuses puces de commutation NVLink 6.
Pour que chacun des 72 GPU présents dans un cluster NVL72 puisse communiquer avec n’importe quel autre, simultanément, sans aucun goulet d’étranglement, Nvidia a calculé que ce cluster devait embarquer 36 puces NVLink 6.
ConnectX-9 : CXL 3,1 pour le stockage, meilleure isolation pour les hyperscalers

Outre les communications entre les GPU d’un même cluster NVL72, les nœuds de calcul doivent aussi communiquer avec leur stockage, voire avec le reste d’un datacenter. Pour ce faire, chaque nœud de calcul NVL72 contient quatre cartes réseau (deux par GPU) basées sur la puce ConnectX-9 et équipées chacune d’un port en 800 Gbit/s. Cette carte peut communiquer en Ethernet (plus exactement en Spectrum-X Ethernet, la déclinaison RDMA de Nvidia, optimisée pour son protocole GPUDirect), en Infiniband (stockage du supercalcul) et même, désormais, en CXL 3.1.
En plus du CXL, la puce ConnectX-9 dispose de nouveaux moyens de chiffrement à la volée. Cela dit, ceux-ci ne seront utiles qu’avec un stockage lui-même équipé de cartes réseau Nvidia (en l’occurrence les BlueField-4), soit dans le cas où le cluster NVL72 est relié à un ou plusieurs autres clusters NVL72 pour former un SuperPOD.
Ces possibilités de chiffrement participent manifestement d’un effort de meilleure isolation des calculs par client, ce qui n’est utile que pour les fournisseurs de services d’IA en cloud.
BlueField-4 : un véritable processeur Grace dans les cartes réseau

Contre toute attente, la puce DPU BlueField-4 – qui équipe les cartes réseau Spectrum-X Ethernet à mettre dans les baies de stockage, voire dans les serveurs applicatifs qui parlent à un cluster NVL72 – sera certainement celle qui aura le plus évolué par rapport à la génération actuelle.
La caractéristique la plus saillante étant qu’elle intégrera un processeur Grace ! Plus exactement une version légèrement raccourcie du processeur qui équipe les actuels nœuds de calcul GB200, puisqu’on y trouvera 64 cœurs ARM Neoverse V2 au lieu de 72. L’actuelle puce BlueField-3 ne contient que 16 cœurs ARM Cortex-A78. On passera donc d’un groupe de cœurs surtout conçus pour copier/transformer des données à la volée à une flotte de cœurs capables d’exécuter des applications pour serveurs.
Les capacités seront à l’avenant : 128 Go de mémoire par carte, contre 32 Go aujourd’hui, 250 Go/s de bande passante, contre 75 Go/s. En revanche, le débit est juste doublé (800 Gbit/s contre 400 Gbit/s aujourd’hui), tout comme le nombre d’accès en NVME/RoCE (20 millions d’IOPS au lieu de 10).
Manifestement, la seule caractéristique notable qui semble bénéficier de ce bond de puissance est la quantité de destinations que cette puce pourra empiler dans sa mémoire pour ne pas perdre les paquets qu’elle leur envoie : 128 000 contre 32 000 aujourd’hui. Pour y parvenir, il fallait multiplier la RAM par 4 et afin de gérer autant de RAM, il fallait autre chose qu’un Cortex-A78. Recycler des processeurs Grace était peut-être la solution la plus économique.
128 000 destinations conservées en mémoire c’est une quantité énorme, qui n’est atteignable que dans un seul scénario d’usage : quand la carte est installée chez un hyperscaler.
BlueField-4 : mais aussi un ConnectX-9 pour gérer le stockage comme de la RAM
Pour le reste, on retrouvera les mêmes possibilités d’isolement et de chiffrement que sur la puce ConnectX-9 intégrée aux serveurs. Et pour cause : selon les documentations, la puce BlueField-4 sera en réalité un processeur Grace auquel Nvidia aura simplement greffé une puce réseau ConnectX-9.
C’est d’ailleurs dans cette partie ConnectX-9 et son support du CXL 3.1 que les prochaines cartes réseau de Nvidia pourraient présenter une vraie avancée dans le stockage, en gérant dès le DPU BlueField-4 le SSD NVMe sur lequel un flux de données doit être lu ou écrit.
Nvidia évoque à ce propos une nouvelle technologie, l’Inference Context Memory Storage (ICMS), qui consiste à stocker sur des SSD NVMe l’historique des tokens calculés au fil d’une conversation avec un chatbot. Le détail technique est que les tokens ne sont pas stockés sous forme de blocs de longueur fixe, traditionnels dans le stockage, mais sous la forme d’informations clé-valeur de taille variable. À la manière du système de stockage DAOS qui pilote les SSD NVMe comme s’il s’agissait d’une RAM avec des adresses.
Spectrum -6 : des switches Ethernet photoniques

Enfin, la prochaine puce contrôleur Spectrum-6 pour les switches réseau Spectrum-X Ethernet – qui s’interfacent donc entre des ConnectX-9 côté nœuds de calculs et des BlueField-4 côté baies de stockage – sera photonique !
Comme sur les derniers switches Quantum-X de Nvidia pour réseaux InfiniBand, elle intégrera autour de ses circuits de routage une couronne de convertisseurs optiques. Ceux-ci évitent aux utilisateurs d’avoir à acheter eux-mêmes des embouts SFP pour brancher des fibres optiques dans des connecteurs électriques. Ces embouts coûtent d’ordinaire plus de 1 000 € l’unité pour convertir un connecteur 400 ou 800 Gbit/s en optique, et ils sont excessivement énergivores.
L’année dernière, Nvidia a mis au point un nouveau design CPO (Co-Packaged Optics) qui intègre des circuits photoniques à des circuits électroniques, de sorte que les fibres optiques sortent directement de la puce jusqu’à des connecteurs optiques femelles à l’arrière du switch. Ce design n’élimine pas le problème de la consommation électrique. En revanche, en regroupant ainsi tous les convertisseurs photoniques au même endroit, il autorise un refroidissement du switch par liquide qui résout le problème de dissipation thermique des embouts SFP optiques.
Une puce Spectrum-6 sera capable de router 102,4 Tbit/s entre un maximum de 512 ports réseau (à raison de 200 Gbit/s par port). Cela dit, son packaging CPO n’offrira que 32 connecteurs optiques qui ne pourront véhiculer chacun que 1,6 Tbit/s, soit un total de 51,2 Tbit/s. On en déduit que le switch SN6810 (128 ports Ethernet en 800 Gbit/s), qui sera fabriqué sur cette nouvelle technologie, aura deux puces Spectrum-6 qui communiqueront entre elles en 51,2 Tbit/s et que chacune gérera, en plus, 64 ports physiques en 800 Gbit/s à l’arrière de la machine.
Précisons que décliner une fibre interne qui véhicule 1,6 Tbit/s en deux fibres externes de 800 Gbit/s, ou en quatre de 400 Gbit/s, ou en huit de 200 Gbit/s est relativement facile, puisqu’il s’agit juste de superposer des longueurs d’onde et de les séparer avec un prisme.
Nvidia annonce également un switch 512 ports en 800 Gbit/s qui, en toute logique, sera équipé de huit puces Spectrum-6.
Pour approfondir sur Hardware IA (GPU, FPGA, etc.)
-
![]()
PDG de Nvidia : « nous atteindrons un CA de 1000 milliards de dollars en 2027 »
Par: Yann Serra
-
![]()
GTC 2026 : Nvidia impose un nouveau type de stockage
Par: Yann Serra
-
![]()
GTC 2026 : maintenant, Nvidia part à la conquête des serveurs
Par: Yann Serra
-
![]()
Puces : AMD bat encore ses propres records de vente
Par: Yann Serra



