Plakar, ce Français qui veut simplifier les sauvegardes
La startup a mis au point une commande et un format qui permettent aux équipes opérationnelles de s’occuper elles-mêmes de leurs sauvegardes et qui cantonnent les prestataires à la cybersécurité de leur stockage.
Plakar est une nouvelle solution de sauvegarde Open source, lancée en 2025 par deux Français, Gilles Chehade au code et Julien Mangeard à la direction. Elle se veut beaucoup plus simple que les logiciels habituels.
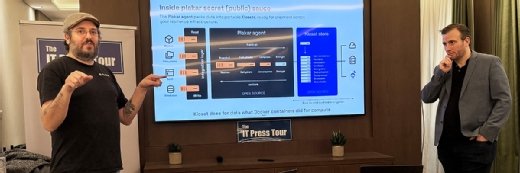
Il s’agit d’une part d’une commande – oui, une simple commande pour Windows, macOS ou Linux – qui fait furieusement penser à la commande d’archivage tar, mais à laquelle on aurait ajouté la déduplication et le support de plusieurs modes de stockage. Pour l’heure principalement de l’objet au protocole S3, en plus du classique mode fichier. D’autre part, il s’agit d’un format de stockage, le Kloset, qui, donc, stocke indifféremment les sauvegardes rapetissées de toute une variété de serveurs de données sources.
L’ensemble est disponible en Open source, mais la startup a débuté dès décembre dernier des activités commerciales. Plakar Enterprise Core revient à déployer un Kloset chez un client pour qu’il agisse comme un sas de déduplication, compression, chiffrement avant d’envoyer des sauvegardes – éventuellement faites par un autre logiciel – vers un prestataire externe de stockage.
La startup cite en exemple un CHU ayant eu la primeur du logiciel. Le poids du Kloset installé était 80 % inférieur à celui des snapshots d’origine. Mieux, le poids de ses mises à jour quotidiennes était si faible que le transfert ne prenait plus que quelques minutes, contre plus d’une journée auparavant. L’ensemble aboutit à des services de stockage moins chers et des fenêtres de sauvegarde qui ne se chevauchent plus.
Gilles Chehade (à gauche sur la photo en haut de cet article) explique que traiter la déduplication, la compression et le chiffrement à la source assure aux utilisateurs d’être totalement indépendants du service de stockage externe qu’ils contracteront. Non seulement techniquement ; ce qui leur permettrait de changer librement de prestataire. Mais aussi sur l’aspect réglementaire, puisque, même dans le cas d’un hyperscaler américain soumis au Cloud Act, la fouille des sauvegardes par une entité non autorisée se heurterait à un contenu illisible. LeMagIT a rencontré la startup à l’occasion d’un récent événement IT Press Tour consacré aux acteurs européens qui innovent dans le stockage.
Plakar Enterprise for AWS, un service lancé dès ce mois de janvier, consiste quant à lui à exécuter une commande Plakar chez AWS pour qu’il aspire automatiquement et régulièrement le contenu d’un stockage local, sans que le client ait eu besoin d’installer quoi que ce soit chez lui. Si tout se passe bien, la même fonction apparaîtra en février chez OVHcloud et en mars sur GCP.
Idéalement, il s’agit de combiner un Plakar Enterprise Core sur site avec un service Plakar Enterprise en cloud pour que l’hébergeur de cloud n’ait pas accès au chiffrement/déchiffrement des sauvegardes. Dans ce cas, le client n’a pas nécessairement besoin de déployer un Kloset chez lui, la solution se contentant d’installer sur site des proxys avec les clés de chiffrement.
Laisser les équipes opérationnelles faire leurs propres sauvegardes
Il faut entrer dans le détail de la version Open source pour comprendre l’intérêt de Plakar. Selon les présentations que partage la startup éponyme qui l’édite, le produit Open source s’est positionné durant ses premiers mois d’existence comme une solution permettant aux développeurs de réaliser eux-mêmes des sauvegardes, alors que cette fonction est d’ordinaire du ressort du service informatique. Il s’agit de permettre à des petites équipes de protéger leur travail au rythme qu’elles décident, en chiffrant tout à la source pour que personne ne puisse fouiller dedans.
D’habitude, les sauvegardes se font à partir des données en clair via des consoles (Veeam, Commvault, etc.) conçues pour les usages des administrateurs de stockage, soit des gens de la DSI, pas des équipes de développement. Les fonctions de déduplication, compression, chiffrement sont indépendantes les unes des autres, mais dépendent tantôt du logiciel de sauvegarde, tantôt du système de stockage. Cela crée des verrouillages techniques sur plusieurs solutions et aussi de la complexité, car il faut enchaîner tout cela dans un certain ordre.
À la fin, les personnels qui ont confié leurs données n’ont plus la certitude qu’elles sont correctement protégées. D’autant que les administrateurs sont bien incapables de vérifier si un problème de cohérence entre les données ne se serait pas glissé dans la procédure.
« Les directeurs techniques [les responsables des développeurs, ici, N.D.R.] veulent être sûrs que leurs équipes aient accès à un outil super simple qui leur permette de faire leurs propres sauvegardes, chiffrées à la source pour que ce soit en mode zéro confiance, et qu’ensuite seulement elles en délèguent la responsabilité à quelqu’un d’autre », assure Julien Mangeard (à droite sur la photo en haut de cet article).
Avec Plakar, le service informatique ou le prestataire a toujours un rôle. Mais il se cantonne à gérer le stockage qui héberge ces sauvegardes : la gestion de sa capacité et, surtout, celle de la sécurité des accès. Si la commande Plakar se veut particulièrement économe en espace de stockage, elle n’est en effet pas elle-même conçue pour protéger les données contre les cyberattaques ; n’importe qui peut effacer ou corrompre ses sauvegardes à partir du moment où il obtient l’accès au serveur qui les héberge. La commande se contente de prévenir qu’une modification a eu lieu.
« L’IA augmente la surface de risque, surtout en interne. »
Julien MangeardCofondateur, Plakar
Plakar fonctionne aussi sans qu’un tiers s’occupe de la cybersécurité des sauvegardes. Mais les sauvegardes locales servent alors juste à protéger les collaborateurs contre leurs erreurs de manipulation. Elles seraient d’ailleurs de plus en plus fréquentes chez les développeurs depuis que ces équipes s’appuient sur l’IA pour écrire leurs codes.
« L’IA augmente la surface de risque, surtout en interne. Récemment, un agent d’IA a effacé tout le disque dur d’un développeur, car celui-ci lui avait simplement demandé de couper quelque chose au milieu de son code. Et tous les directeurs techniques auxquels nous parlons sont terrorisés à l’idée de ce qui pourrait arriver à leurs projets à cause d’une IA qui y entrerait par l’intermédiaire d’une passerelle MCP. Car les développeurs font en ce moment un usage excessif de ces passerelles [qui interconnectent les IA, N.D.R.] », illustre Julien Mangeard.
Comme une archive Tar, mais dédupliquée
L’apprentissage du logiciel est assez simple. Dans le principe, il suffit de taper la commande « plakar » avec des options pour tout faire. Le mot clé « at » indique l’endroit où stocker une sauvegarde ; un autre répertoire, un serveur FTP ou SFTP et un bucket S3 sont les options possibles au moment de l’écriture de cet article. La première fois, on le fait suivre de la sous-commande « create » pour créer à cet endroit un Kloset, une sorte de sous-répertoire à l’arborescence compliquée qui contiendra les sauvegardes. Les fois suivantes, la sous-commande « backup » servira à dire quel répertoire, serveur ou bucket source sauvegarder dans le Kloset.
Il est à noter qu’un même Kloset peut héberger les sauvegardes de plusieurs serveurs, même quand ceux-ci sont de natures différentes. « Un bon exemple est un site WordPress. Vous ne pouvez pas sauvegarder d’un côté son système de fichiers, puis, de l’autre, sa base de données. Il faut sauvegarder les deux ensemble pour préserver la cohérence du site à un instant T. C’est ce que le Kloset permet de faire », indique Julien Mangeard.
L’autre mérite de Plakar par rapport à tar est qu’il déduplique les sauvegardes. À chaque fois que cette commande « backup » sera tapée, l’outil vérifiera dans le Kloset si les sauvegardes précédentes n’avaient pas déjà les mêmes blocs, de sorte à ne sauvegarder que les nouvelles données. En termes d’économie d’espace de stockage, la déduplication est encore plus efficace que la sauvegarde incrémentale.
Comme Tar, Plakar compresse – en LZ4, ici – ce qu’il sauvegarde pour gagner encore plus d’espace. Selon la compréhension du MagIT, la mémoire des blocs déjà enregistrés, mais compressés puis chiffrés, réside dans l’index du Kloset. Cela permet à la commande de maintenir l’efficacité de sa déduplication malgré des blocs qui sont in fine transformés.
On retiendra que la commande plakar peut être installée indifféremment sur la source à sauvegarder ou sur la destination qui stocke les sauvegardes. Dans les deux cas, la source est l’emplacement indiqué après la sous-commande « backup » et le Kloset se situe à l’adresse indiquée après la sous-commande « at ». Cette manière de faire évite d’avoir à installer un agent de part et d’autre : la commande pousse les sauvegardes vers un stockage de destination, ou aspire un stockage source pour le sauvegarder, selon d’où elle est exécutée.
Toutes les fonctions au bout des doigts
La sous-commande « scheduler start » sert à lancer en tâche de fond des sauvegardes à intervalle régulier. La bonne pratique semble de définir la source, la destination et l’intervalle depuis un fichier de configuration en YAML qu’on indique avec l’option « -tasks ». Chaque sous-commande supporte des options. Pour « backup », ce sera le plus souvent « -check » afin de vérifier que la sauvegarde est restaurable.
Ajoutons à cela les sous-commandes « sync », pour synchroniser le Kloset avec une copie située ailleurs (typiquement chez un hébergeur), et « ui » qui affiche une console graphique (en ouvrant automatiquement un navigateur web). En l’état, cette console sert juste à lister les snapshots, à constater qu’ils ont été sauvegardés correctement et à alerter s’ils ont été altérés entretemps.
Autre sous-commande de sauvegarde notable, « ptar » regroupe toute l’arborescence d’un Kloset dans une seule archive .ptar, un format inventé par la startup. L’intérêt d’un seul fichier .ptar par rapport à une arborescence Kloset n’est cependant pas très clair. Lors de sa présentation, l’équipe de Plakar s’est contentée de comparer l’archive .ptar à une archive .tar : elle pèse moins lourd puisque tout est dédupliqué, comme dans le Kloset. On suppose qu’il serait sans doute plus simple, lors des transferts, de déplacer une seule archive plutôt que toute une arborescence.
À ce stade, la startup ne mentionne pas l’éventualité de faire disparaître le format Kloset au profit du format .ptar.
Dans l’autre sens, la sous-commande « restore » permet de restaurer une sauvegarde à son origine. On lui ajoutera « - to » pour indiquer un autre endroit où restaurer cette sauvegarde. Il est aussi possible de restaurer un snapshot précédent. Le mot clé « ls » sert à lister tous ceux présents dans un Kloset. Ils sont indiqués sous la forme de numéros de série et il suffit d’indiquer en fin de commande celui à restaurer.
Il serait même possible de restaurer des données dans un type de stockage différent de celui d’origine, par exemple un système de fichiers dans un bucket S3. Les scénarios manquent néanmoins encore pour trouver l’usage pertinent de cette fonctionnalité. La startup a rapidement évoqué la possibilité d’utiliser des moteurs de recherche.
L’évolution : des connecteurs additionnels pour gérer les différents types de stockage
Pour sauvegarder depuis et vers autre chose que le système de fichiers local, il faut installer, avec la sous-commande « pkg add », des connecteurs qui prennent en charge un type de stockage en particulier. Une page référence tous ceux qui existent. À l’heure où nous écrivons cet article, il existe déjà des connecteurs en version beta pour quelques services de stockage en ligne (Dropbox, Google Drive, OneDrive, iCloud drive), pour une poignée de services applicatifs (CalDAV, Imap, Notion), ainsi que pour des serveurs de stockage ordinaires (FTP, SFTP, S3, mais pas NFS, ni SMB).
« Oui sauvegarder des bases SQL (Oracle, MySQL, PostgreSQL) est prévu. Mais nous procédons par étape. »
Julien MangeardCofondateur, Plakar
Julien Mangeard promet que la liste des connecteurs ne va pas cesser de s’allonger. « Oui sauvegarder des bases SQL (Oracle, MySQL, PostgreSQL) est prévu. Mais nous procédons par étape », dit-il, sans s’avancer sur une date. Gilles Chehade précise qu’un SDK est disponible pour permettre à quiconque de créer ses propres connecteurs.
Un point à prendre en considération est que « pkg add » n’accepte de télécharger des connecteurs qu’à partir du moment où l’utilisateur a reçu un identifiant de la part de l’éditeur de Plakar. Pour l’heure, cette procédure est plus ou moins simplifiée. Il suffit de taper « plakar login -email » suivi d’une adresse électronique pour recevoir un identifiant sur sa boîte, ou « plakar login » tout court pour ouvrir automatiquement le navigateur sur GitHub et s’y authentifier, si on possède un compte GitHub. A priori, aucun connecteur ne nécessitera de s’abonner à une version payante.
Définir ensuite le stockage source ou destination se fait via la commande « plakar store add », suivie d’un nom de raccourci et des détails de la connexion à ce stockage (le protocole, par exemple « s3:// », puis l’adresse, le login, le mot de passe). Par la suite, les commandes de sauvegarde et restauration utiliseront simplement le raccourci, préfixé du caractère « @ », pour accéder en lecture ou en écriture à ce stockage.
Il semble d’ailleurs qu’attribuer une bonne fois pour toutes un raccourci vers un Kloset soit une bonne idée, car cela évite d’avoir à taper à tout bout de champ le mot de passe d’accès au Kloset.