
zapp2photo - Fotolia
Cinq composants fondamentaux d’une architecture de microservices
Vous vous apprêtez à construire votre application sur une architecture de microservices ? Commencez par examiner de plus près ses composants et leurs capacités.

Comme son nom l’indique, une architecture de microservices est un regroupement complexe de code, de bases de données, de fonctions d’application et d’une logique de programmation, étendu à différents serveurs et plateformes. Certains composants fondamentaux d’une architecture orientée microservices, assurent la cohésion de toutes ces entités à l’échelle d’un système distribué.
Dans cet article, nous examinons cinq composants clés dont les développeurs et les architectes d’application auront besoin s’ils envisagent de s’engager dans la voie des services distribués. Nous commencerons par les microservices proprement dits, avant de nous intéresser à la couche additionnelle de maillage de services (ou service mesh, en anglais), à la gestion d’applications via la découverte des services, au déploiement reposant sur des containers et aux passerelles API.
-
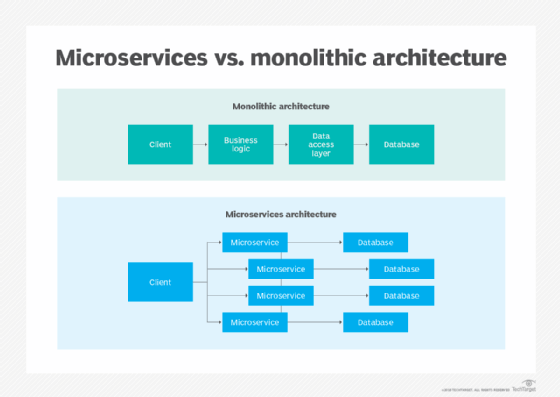
Microservices, l’unité de base d’une architecture de microservices
Les microservices constituent le socle de l’architecture de microservices. Le terme de microservices décrit le procédé de décomposition d’une application en services autonomes (Self-Contained) généralement plus petits, développés dans n’importe quel langage et qui communiquent via des protocoles légers. Les microservices indépendants permettent aux équipes de développement de logiciels de mettre en œuvre des processus de développement itératifs, ainsi que de créer et de mettre à jour des fonctions de manière flexible.
Les équipes doivent décider d’une taille de microservice appropriée, en gardant à l’esprit qu’un ensemble trop granulaire de services segmentés à l’excès engendrera une plus grande complexité d’administration et de gestion. Les développeurs doivent aussi fortement découpler les services pour minimiser leurs interdépendances et promouvoir leur autonomie. En outre, il est recommandé d’utiliser des mécanismes de communication légers, tels que REST et HTTP.
-
Containers
Les containers sont des unités logicielles qui enveloppent des services et leurs dépendances, conservant ainsi une homogénéité unitaire au cours des phases de développement, de test et de production. Les containers ne sont pas nécessairement dédiés au déploiement de microservices et l’inverse est également vrai. Toutefois, dans le cadre d’une architecture microservices, les containers peuvent écourter le délai de déploiement et améliorer le rendement des applications bien plus efficacement que d’autres environnements de déploiement, tels que les machines virtuelles (VM).
La principale différence entre VMs et containers, tient à ce que les seconds peuvent partager un système d’exploitation (OS) et des composants intermédiaires (middleware), là où une VM inclura un OS entier pour son seul usage. En éliminant la nécessité pour une VM de fournir un OS distinct pour chaque petit service, les entreprises sont à même d’exécuter un ensemble plus étendu de microservices sur un même serveur.
L’autre avantage des containers tient à leur capacité à se déployer à la demande, sans impacter négativement les performances de l’application. Les développeurs peuvent en outre les remplacer, les déplacer et répliquer au prix d’un effort assez minime. L’indépendance et l’homogénéité des containers jouent un rôle critique en permettant l’évolution de certains éléments de l’architecture de microservices (en fonction des charges de travail) plutôt que celle de l’ensemble de l’application. En outre, une image Docker orchestrée depuis Kubernetes, par exemple, peut être redéployée en cas de défaillance, ce qui entraînera le redémarrage du microservice.
Initialement plateforme open source dédiée à la gestion des containers, Docker est l’un des produits/éditeurs phare dans cet espace. Toutefois, la réussite de Docker a entraîné dans son sillage l’évolution d’un important écosystème d’outils, donnant alors naissance à des orchestrateurs tels que Kubernetes.
-
Maillage de services
Dans une architecture orientée microservices, le maillage de services induit une couche de messagerie dynamique visant à faciliter la communication entre microservices. La couche communication devient alors « abstraite » au sens où les développeurs n’ont plus besoin de coder aucune communication interprocessus lorsqu’ils construisent leur application.
Les outils du maillage de services font généralement appel à un modèle dit « side-car ». Celui-ci crée un container de délégation (proxy container) qui s’installe en périphérie des containers renfermant soit une instance unique de microservices, soit un ensemble de services. Le side-car achemine le trafic depuis et vers le container, et dirige la communication avec d’autres proxy sidecar, maintenant ainsi les connexions de service.
Istio, un projet lancé par Google parallèlement à IBM avec Lyft, et Linkerd, projet sous l’égide de la Cloud Native Computing Foundation, sont deux des options de maillage de services les plus répandues actuellement. Istio et Linkerd sont liés à Kubernetes, bien qu’ils présentent des différences notables dans des domaines tels que l’environnement sans container ou encore les capacités de contrôle du trafic.
-
Découverte de services
Que ce soit à cause des variations des workloads, de mises à jour ou d’atténuation des défaillances, le nombre d’instances de microservices actives dans un déploiement est fluctuant. Sur des emplacements réseau distribués à l’échelle d’une architecture d’applications, tenir le compte d’un grand nombre de services peut s’avérer difficile.
La découverte des services contribue à adapter les instances de services à un déploiement en constante évolution, ainsi qu’à répartir en conséquence une charge entre les microservices. Le composant d’exploration des services comprend trois parties :
- Un fournisseur de services qui génère des instances de services sur un réseau ;
- Un registre des services qui agit comme une base de données stockant l’emplacement des instances de services disponibles ;
- Un consommateur de services qui récupère, dans le registre, l’emplacement d’une instance de service puis communique avec celle-ci.
En outre, la découverte des services consiste en deux schémas principaux :
- Un modèle de découverte côté client recherche le registre des services afin de localiser un fournisseur de services, sélectionne une instance de service adéquate et disponible en faisant appel à un algorithme d’équilibrage de charge, puis émet une requête.
- Dans un modèle de découverte côté serveur, le routeur recherche le registre des services et, une fois l’instance de service applicable trouvée, transfère la demande en conséquence.
Les données présentes dans le registre des services doivent être systématiquement actualisées. Ainsi les services liés peuvent trouver les instances qui leur sont associées au moment de l’exécution. En outre, si le registre des services est défaillant, il immobilise tous les services. C’est pourquoi, pour éviter des défaillances régulières, les entreprises recourent généralement à un logiciel de gestion de configuration pour systèmes distribués, tel qu’Apache ZooKeeper.
-
Passerelle API
La passerelle API constitue un autre composant important d’une architecture par microservices.
Dans une architecture distribuée, les passerelles API sont essentielles à la communication, car elles constituent la couche principale d’abstraction entre les microservices et les clients extérieurs. La passerelle API gère une grande quantité de rôles de communication et d’administration, qui interviennent typiquement au sein d’une application monolithique ; ce qui permet aux microservices de conserver leur légèreté. Ces passerelles peuvent en outre authentifier, mettre en cache et gérer des requêtes, ainsi que surveiller les messages et procéder à un équilibrage de charge le cas échéant.
En outre, une passerelle API contribue à accélérer la communication entre microservices et clients, en normalisant les protocoles de messagerie et en libérant tant le client que le service du travail de traduction de requêtes rédigées dans des formats inhabituels. La plupart des passerelles API intégreront également des fonctions de sécurité. En d’autres termes, elles seront en mesure de gérer l’autorisation et l’authentification des microservices, ainsi que le suivi de requêtes entrantes et sortantes en vue d’identifier toute intrusion potentielle.
Le marché propose une gamme étendue d’options de gateways API parmi lesquelles choisir, tant auprès de fournisseurs de plateformes en cloud propriétaires, tels qu’Amazon et Microsoft, que d’éditeurs open source, tels que Kong et Tyk.
Pour approfondir sur Architectures logicielles et SOA
-
![]()
Administration : les clés de la mise en réseau des containers
Par: Wisdom Ekpotu
-
![]()
Pourquoi et comment gérer les microservices sans passerelles API
Par: Chris Tozzi
-
![]()
Une passerelle pour renforcer la sécurité des API
Par: Michael Cobb
-
![]()
Service mesh : la libération d’Istio donne des ailes à Solo.io
Par: Gaétan Raoul


