
ninog - Fotolia
Microservices : comprendre les modèles de découverte de services
La découverte de services joue un rôle important dans la gestion d’applications basées sur des microservices. Dans cet article, nous examinons les modèles les plus pratiques pour les développeurs.

Les architectures basées sur les microservices sont plus adaptées pour les applications complexes, utiles à long terme. Elles nécessitent des ressources importantes et une gestion maîtrisée. Une telle application rassemble plusieurs services qui fonctionnent de concert pour une meilleure évolutivité, une maintenance facilitée et des déploiements sans heurts.
Pour fonctionner efficacement, les services doivent se situer les uns par rapport aux autres sur un réseau pour traiter les requêtes. C’est là que la découverte de services (service discovery) entre en jeu.
Pourquoi avez-vous besoin de la découverte de services ?
Quand vous travaillez sur des applications à base de microservices, vous pourriez avoir besoin de changer le nombre d’instances nécessaires au moment de l’exécution. Tout dépend de la charge de votre service : la distribution automatique, les pannes, les mises à jour peuvent en modifier le nombre. Vous devez vous assurer que les services dépendants sont au fait de ces instances.
Ces variations sont parfois difficiles à gérer. Si ces microservices sont hébergés sur des serveurs physiques auxquels vos équipes ont accès, vous pouvez utiliser un fichier de configuration afin de vous assurer que les autres services se reconnaissent. Mais dans le cloud, garder la trace du nombre de services s’avère plus complexe, dû à la nature dynamique de leur emplacement réseau.
La découverte de services aide ces instances à s’adapter et à répartir la charge entre les microservices en conséquence.
Voici les trois composants d’un service discovery :
- Le fournisseur de services : distribue des services à travers le réseau
- Le registre des services : cette base de données contient les emplacements des instances de services disponibles.
- Le consommateur de services : récupère les emplacements auprès du fournisseur depuis le registre et communique ensuite avec l’instance.
Les données présentes dans le registre de services doivent toujours être à jour afin que les clients, les autres microservices, puissent découvrir les instances au moment de l’exécution. Si le registre est HS, cela peut avoir des conséquences néfastes pour le fournisseur et le consommateur de services. Pour surmonter ce problème, les entreprises utilisent des outils de configuration distribués comme Apache Zookeeper.
Les modèles de découvertes de services
Il y a essentiellement deux modèles associés à la découverte de services : la découverte côté client et celle côté serveur. Voyons ce que chacune d’entre elles implique.
Le modèle de découverte côté client
Dans ce schéma, le consommateur de services – également appelé client de services ou client – consulte le registre pour localiser un fournisseur approprié et disponible à l’aide d’un algorithme d’équilibrage de charge. Ensuite, il effectue une requête. La localisation de l’instance est enregistrée dans le registre au moment du démarrage du service. Dès l’arrêt de l’instance, les informations correspondantes sont supprimées du registre.
Ce modèle est relativement facile à comprendre et il peut facilement prendre des décisions intelligentes en matière de répartition des charges, car le consommateur de services est averti des instances de services disponibles.
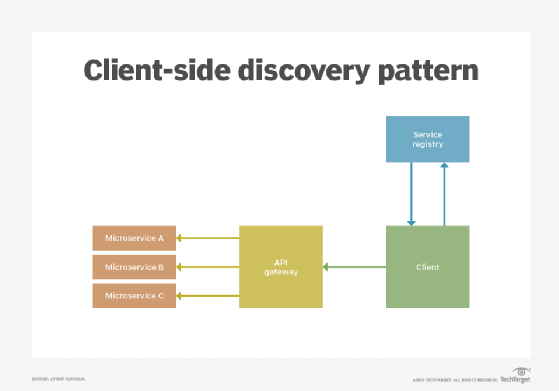
Notez qu’avec ce modèle, le service de découverte peut ou non être placé derrière une passerelle API. Si vous ne le faites pas, il vous incombe de redéployer l’équilibrage, l’authentification et d’autres aspects transversaux liés à la découverte de services.
Un inconvénient majeur de ce modèle est que le consommateur et le registre de services sont étroitement liés. Cela signifie que vous devez mettre en œuvre la logique requise pour la découverte de services du côté client pour chaque langage de programmation que vous pourriez utiliser. Comme l’architecture des microservices est un conglomérat de technologies, d’outils, de frameworks et de langages disparates, la gestion des applications devient de plus en plus complexe.
Le modèle de découverte côté serveur
Avec cette configuration, les consommateurs de services côté client n’ont pas directement accès au registre de services. Ils effectuent leurs requêtes via un routeur. Le routeur explore le fameux registre et, une fois qu’il a trouvé la bonne instance applicable, il transmet la demande. Le client n’a pas besoin de se soucier de la découverte de service et de l’équilibrage de charge. La passerelle API peut sélectionner le bon terminal pour une demande côté client.
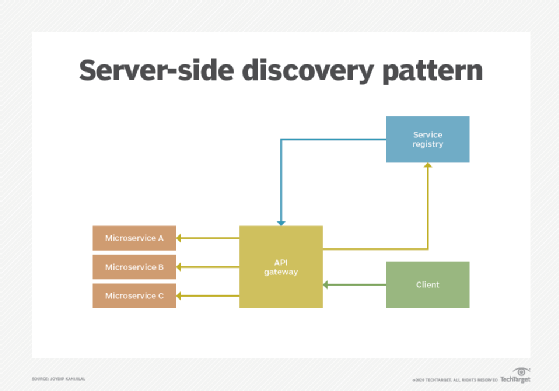
Le grand avantage du modèle de découverte de services côté serveur tient dans le fait que cette méthode est agnostique des langages et des frameworks de programmation. Cependant, l’environnement de déploiement doit fournir le répartiteur de charge tout en étant hautement disponible. Veillez à le gérer et à le reproduire proprement en termes de disponibilité et de capacité.
À lire également :
Maîtriser la découverte automatique de services de Kubernetes
Enregistrer les services dans le registre
Le modèle d’enregistrement des services repose sur deux schémas :
- Le schéma d’auto-enregistrement. L’instance de service accède au registre pour y indiquer son adresse et le service se désabonne une fois que l’instance est terminée.
- Le schéma d’enregistrement par des tiers. Ici, l’instance laisse ce rôle à un composant système appelé « service registrar ».
Gardez à l’esprit qu’une fois qu’un service se termine, il peut ne pas se désinscrire. Cela signifie que si un consommateur de service recherche une instance dans le registre, il recevra une erreur d’adresse non valide. Pour éviter cela, le fournisseur doit connecter ses services au registre à intervalles réguliers, et spécifiés, afin de prouver que le service est toujours opérationnel. Le registre peut alors radier un service si le prestataire n’a pas envoyé de réponse depuis un certain temps.
Pour approfondir sur Middleware et intégration de données
-
![]()
La feuille de route IA d’IBM et d’HashiCorp prend forme
Par: Beth Pariseau
-
![]()
Ransomware : sur la piste trouble de l’un des leaders de Black Basta
Par: Valéry Rieß-Marchive
-
![]()
AWS : comment bien dimensionner les instances EC2
Par: Chris Tozzi
-
![]()
Administration cloud : comment créer une VM EC2 en ligne de commande
Par: Ernesto Marquez



