Les sept modèles de données les plus pertinents en entreprise
Trois types de modèles de données et sept techniques de modélisation sont à la disposition des équipes de gestion des données, pour convertir des montagnes d’informations en précieux indicateurs.

Un modèle de données bien conçu est la pierre angulaire des applications BI et analytiques génératrices de valeurs ajoutées aux entreprises. Il s’agit de transformer les données disponibles en informations utiles.
Les indicateurs sont des données contextualisées, et un modèle de données est le plan d’architecte de cette conjoncture. Les données ont souvent de nombreux contextes en fonction de leur usage dans différents processus d’une organisation. Par conséquent, une entreprise a besoin de plusieurs modèles de données, et non d’un seul. Diverses techniques de modélisation sont à la disposition des équipes responsables de la gestion des données.
Qu’est-ce qu’un modèle de données ?
Un modèle de données est une spécification de structures de données et de règles métier. Il permet de créer une représentation visuelle des données et d’illustrer comment différents éléments sont liés les uns aux autres. Il répond également aux questions « qui, quoi, où et pourquoi » relatives aux éléments. Dans le cadre d’un achat dans un magasin, par exemple, le modèle de données fournit des précisions sur la personne qui a effectué la transaction, ce qui a été acquis, et quand. Il peut aussi contenir des renseignements supplémentaires sur le client, le produit, le magasin, le vendeur, le fabricant, la chaîne d’approvisionnement et bien plus encore.
Il est préférable de construire un modèle de données selon une approche descendante, en partant des exigences commerciales de haut niveau pour arriver à une base de données ou à une structure de fichiers détaillée. Cette approche utilise les trois types de modèles de données suivants :
- Modèle conceptuel de données. Il détermine les données nécessaires aux processus métier ou aux applications d’analytique et de reporting, ainsi que les règles et concepts métier associés. Il ne définit pas le flux de traitement des données ni les caractéristiques physiques.
- Modèle logique de données. Il identifie les structures de données, telles que les tables et les colonnes, et les relations entre les structures, comme les clés étrangères. Des entités et des attributs spécifiques sont définis. Un modèle logique de données est indépendant d’une base de données ou d’une structure de fichier particulière. Il peut être mis en œuvre dans une variété de SGBD, y compris les systèmes relationnels, en colonnes, multidimensionnels et NoSQL – ou même dans un fichier XML ou JSON.
- Modèle physique de données. Un modèle physique définit les structures de base de données ou de fichiers spécifiques qui seront utilisées dans un système. Pour une base de données, cela inclut des éléments tels que les tables, les colonnes, les types de données, les clés primaires et étrangères, les contraintes, les index, les déclencheurs, les espaces de tables et les partitions.
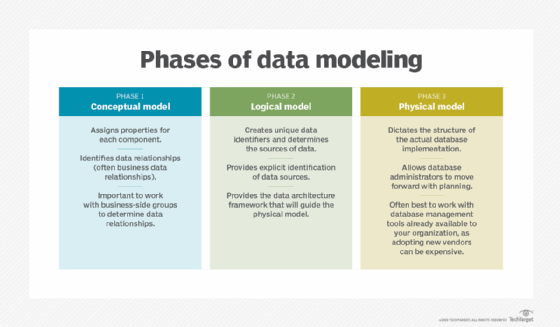
Techniques et concepts courants de modélisation des données
Pour mieux comprendre les techniques de modélisation des données les plus populaires, il est utile de prodiguer une brève leçon d’histoire sur leurs évolutions. Parmi les sept modèles de données décrits ici, les quatre premiers types étaient employés aux premiers jours de l’existence des bases de données et sont toujours des options, puis sont suivis des trois modèles les plus déployés actuellement.
1. Modèle de données hiérarchique
Les données sont stockées dans une structure arborescente avec des enregistrements parents et enfants qui comprennent une collection de champs de données. Un parent peut avoir un ou plusieurs enfants, mais un enregistrement enfant ne peut avoir qu’un seul parent. Le modèle hiérarchique est également composé de liens, qui sont les connexions entre les enregistrements, et de types qui spécifient la sorte de données contenues dans le champ. Il a vu le jour dans les bases de données associées aux mainframes dans les années 1960.
2. Modèle de données en réseau
Il étend le modèle hiérarchique en permettant à un enregistrement enfant d’avoir un ou plusieurs parents. Une spécification standard du modèle réseau a été adoptée en 1969 par la Conference on Data Systems Languages, un groupe aujourd’hui disparu, plus connu sous la désignation CODASYL. C’est pourquoi on le nomme aussi le modèle CODASYL. La technique du réseau est le précurseur d’une structure de données en graphe, avec un objet de données représenté à l’intérieur d’un nœud et où la relation entre deux nœuds est appelée une arête. Bien que populaire sur les mainframes, elle a été largement remplacée par les bases de données relationnelles après leur apparition à la fin des années 1970.
3. Modèle de données relationnel
Dans ce modèle, les données sont stockées dans des tables et des colonnes et les relations entre les éléments de données qu’elles contiennent sont identifiées. Il intègre aussi des fonctionnalités de gestion de base de données telles que les contraintes et les déclencheurs. L’approche relationnelle est devenue la technique dominante de modélisation des données au cours des années 1980. Les modèles de données entité-relation et dimensionnels, qui sont actuellement les méthodes les plus répandues, sont des variantes du modèle relationnel, mais peuvent également être utilisés avec des bases de données non relationnelles.
4. Modèle de données orienté objet
Il combine des aspects de la programmation orientée objet et du modèle de données relationnel. Un objet représente les données et leurs relations dans une structure unique, avec des attributs qui spécifient les propriétés de l’objet et des méthodes qui définissent son comportement. Les objets peuvent avoir de multiples relations entre eux. Le modèle orienté objet est également composé des éléments suivants :
- les classes, qui sont des collections d’objets similaires ayant des attributs et des comportements partagés ; et
- l’héritage, qui permet à une nouvelle classe d’hériter des attributs et des comportements d’un objet existant.
Il a été créé pour être utilisé avec les bases de données objet, qui sont apparues à la fin des années 1980 et au début des années 1990 comme une alternative aux technologies relationnelles, sans pour autant ébranler leur suprématie.
5. Modèle de données entité-relation
Il a été largement adopté avec les SGBDR dans les applications des entreprises, notamment pour le traitement des transactions. Grâce à une redondance minimale et des relations bien définies, il est très efficace pour les processus de saisie et de mise à jour des données. Le modèle entité-relation se compose des éléments suivants :
- des entités qui représentent des personnes, des lieux, des choses, des événements ou des concepts sur lesquels les données sont traitées et stockées sous forme de tables ;
- des attributs, qui sont des caractéristiques ou des propriétés distinctes d’une entité, gérées et stockées sous forme de données dans des colonnes ; et
- des relations, qui définissent des liens logiques entre deux entités et correspondent à des règles ou à des contraintes commerciales.
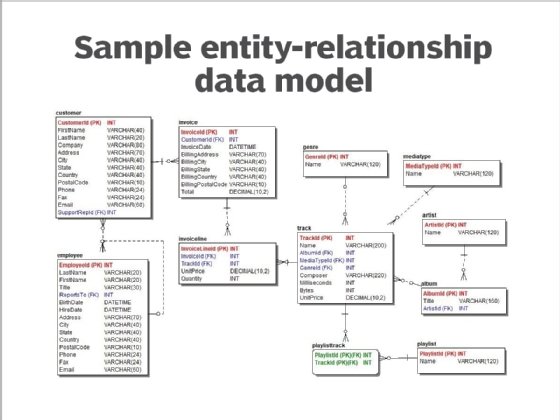
La conception du modèle est caractérisée par le degré de normalisation – le niveau de redondance mis en œuvre, tel qu’identifié par Edgar F. Codd, le créateur du modèle relationnel. Les aspects les plus courants sont la troisième forme normale (3 NF) et la forme normale de Boyce-Codd, une version légèrement plus forte également connue sous le nom de 3,5 NF.
6. Modèle de données dimensionnel
Comme le modèle entité-relation, son cousin dimensionnel comprend des attributs et des relations. Mais il se caractérise par deux composants essentiels.
- Les faits, qui sont les mesures d’une activité telles qu’une transaction mercantile ou un événement impliquant une personne ou des dispositifs. Les faits sont traditionnellement des données chiffrées, et les tables de faits sont normalisées et comportent peu de redondance.
- Les dimensions, qui sont des tables contenant le contexte commercial des faits, pour définir leurs attributs « qui, quoi, où et pourquoi ». Les dimensions sont généralement descriptives plutôt que des valeurs numériques.
Le modèle dimensionnel a été largement adopté pour les applications BI et d’analytique. Il est souvent appelé schéma en étoile, soit un fait entouré et relié à plusieurs autres faits, bien que cela simplifie excessivement la structure du modèle. La plupart des modèles dimensionnels comportent de nombreuses tables de faits liées à de multiples dimensions, qui sont dites conformes lorsqu’elles sont partagées par plus d’une table de faits.
7. Modèle de données graphe
Le modèle de données orienté graphe trouve ses racines dans la technique de modélisation des réseaux. Elle est principalement utilisée pour modéliser des relations complexes dans les bases de données orientées graphes, mais elle peut aussi être manipulée dans d’autres SGBD NoSQL tels que les types clé-valeur et document.
Il existe deux éléments fondamentaux dans un modèle de données de graphe.
- Les nœuds, qui représentent des entités dotées d’une identité unique. Chaque instance d’une entité est un nœud différent qui s’apparente à une ligne dans une table dans le modèle relationnel.
- Les arêtes, également appelées liens ou relations. Elles relient les nœuds et définissent comment les nœuds sont liés. Tous les nœuds doivent avoir au moins une arête, et toutes les arêtes doivent connecter les nœuds. Les arêtes peuvent être non dirigées, avec une relation bidirectionnelle entre les nœuds, ou dirigées, avec lesquelles une relation dépend d’une direction spécifique.
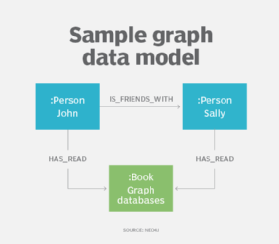
L’un des formats de graphe les plus populaires est le modèle de graphe de propriétés. Avec cette approche, les propriétés des nœuds ou des arêtes sont représentées par des paires nom-valeur. Les étiquettes peuvent également être utilisées pour regrouper les nœuds afin de faciliter les requêtes. Chaque nœud ayant le même label devient un membre de l’ensemble, et les nœuds peuvent se voir attribuer autant d’étiquettes que nécessaire.
Les meilleures pratiques de modélisation des données
Nous pouvons résumer les meilleures pratiques de modélisation des données en huit étapes qui peuvent aider une entreprise à tirer la valeur métier souhaitée de ses données.
Traitez le modèle de données comme un plan d’architecte et une spécification. Les modèles de données doivent être un guide utile pour les personnes qui conçoivent le schéma de la base de données et celles qui produisent, mettent à jour, gèrent, gouvernent et analysent les données. Suivez la progression des modèles conceptuels, logiques et physiques si un nouveau modèle de données est créé lors d’un déploiement greenfield, sans modèles ou schémas physiques existants.
Recueillez dès le départ l’ensemble des besoins. Demandez l’avis des parties prenantes des organisations pour bâtir des modèles de données conceptuels et logiques basés sur les besoins de l’entreprise. Consignez également les exigences en matière de données auprès des analystes métier et d’autres experts en la matière, afin de dériver des modèles logiques et physiques plus détaillés à partir ces dernières. Les modèles de données doivent évoluer avec l’activité et la technologie.
Développez les modèles de manière itérative et incrémentielle. Un modèle de données peut comprendre des centaines ou des milliers d’entités et de relations. Il serait extrêmement difficile de le concevoir en une seule fois. N’essayez pas de faire bouillir l’océan. La meilleure approche consiste à segmenter le modèle en domaines identifiés dans un modèle conceptuel, et à bâtir ces domaines un par un. Ensuite, il s’agit d’établir les interconnexions entre eux.
Utilisez un outil de modélisation des données pour concevoir et maintenir les modèles de données. Les outils de modélisation des données fournissent des représentations visuelles, une documentation sur la structure des données, un dictionnaire des données et le code du langage de définition des données nécessaire pour créer des modèles de données physiques. Ils peuvent aussi souvent échanger des métadata avec des outils de SGBD, d’intégration, de BI, de catalogue de données et de data gouvernance. Et s’il n’existe pas de « data models » dans les bases de données installées, exploitez les fonctions de rétro-ingénierie d’un outil pour lancer le processus.
Déterminez le niveau de granularité nécessaire. En général, maintenez l’échelon le plus bas de granularités possibles – en d’autres termes, les données les plus détaillées qui sont collectées. N’agrégez les données que lorsque cela est indispensable et uniquement en tant que data model dérivé, tout en conservant les données de plus faible granularité dans le modèle principal.
Évitez la dénormalisation extensive des bases de données. La dénormalisation d’une base de données génère de la redondance pour optimiser les performances des requêtes. Mais elle suppose une relation spécifique entre les entités qui peut limiter son utilité pour différentes applications analytiques. Comme pour l’agrégation, lorsque la dénormalisation est employée, il est préférable de l’exécuter au sein d’un data model dérivé – par exemple, dans un schéma pour un programme BI plutôt que dans un data warehouse.
Utilisez les modèles de données comme outil de communication avec les utilisateurs métier. Un modèle entité-relation de 10 000 tables peut faire tourner la tête de n’importe qui. Mais un modèle de données, ou une partie de celui-ci, axé sur un processus métier ou un traitement particulier, offre l’occasion parfaite de discuter et de vérifier le schéma avec les collaborateurs métiers. L’hypothèse selon laquelle cette population ne peut pas comprendre un modèle de données s’avère profondément erronée.
Gérez les modèles de données comme n’importe quel autre code d’application. Les applications métiers, les processus d’intégration de données et les applications analytiques utilisent tous des structures de données, qu’elles soient conçues et documentées ou non. Plutôt que de laisser une « architecture accidentelle » peu gouvernée se développer et anéantir toute chance d’obtenir un retour sur investissement solide à partir de leurs données, les organisations doivent prendre au sérieux ce processus de modélisation.
Pour approfondir sur Base de données
-
![]()
PuppyGraph simplifie l’analyse de graphes en retirant le pipeline
Par: Stéphane Larcher
-
![]()
DBaaS : Google Cloud façonne Spanner pour l’IA générative
Par: Gaétan Raoul
-
![]()
La R&D de Servier accélérée par les bases orientées graphes
Par: Pierre Berlemont
-
![]()
Knowledge Graph et IA générative : Neo4j se met à la recherche vectorielle
Par: Eric Avidon


