
Votre stockage en cloud est-il compatible avec l’IA ?
La conception du stockage en cloud a une incidence directe sur les performances, l’évolutivité et le coût de l’IA. Cet article explique comment choisir les services de stockage les plus adaptés et optimiser les pipelines de données.

Étant donné que de nombreuses applications d’intelligence artificielle sont extrêmement gourmandes en données, la conception et la configuration des services de stockage en cloud jouent un rôle clé dans les performances de l’IA, son évolutivité et l’optimisation des coûts.
Selon une étude du cabinet de conseil Omdia, les dépenses des entreprises en matière de stockage en cloud devraient passer de 57 milliards de dollars en 2023 à 128 milliards de dollars d’ici à 2028, une croissance fortement tirée par la demande en IA.
L’une des raisons pour lesquelles la stratégie de stockage en cloud influe sur l’IA est que les fournisseurs de cloud proposent différents types de solutions de stockage. Les principales options sont les suivantes :
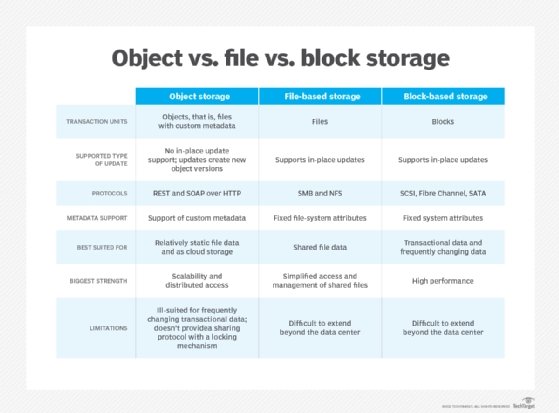
- Stockage objet. Les services de stockage objet, tels qu’Amazon S3 et Azure Blob Storage, permettent aux entreprises de stocker de grandes quantités de données de manière relativement non structurée.
- Stockage en mode bloc. Les solutions de stockage en mode bloc, telles qu’Azure Disk Storage et Amazon Elastic Block Store, sont principalement conçues pour héberger les systèmes de fichiers utilisés par les serveurs cloud.
- Stockage de fichiers. Les services de stockage de fichiers, tels qu’Amazon Elastic File System, peuvent également être utilisés pour fournir du stockage aux serveurs cloud, bien que leurs performances soient généralement un peu plus faibles.
- Bases de données. Le cloud moderne propose une variété de services de bases de données gérées, capables d’héberger à la fois des données structurées et non structurées.
L’impact du stockage en cloud sur les traitements liés à l’IA
Tous les types de systèmes de stockage décrits ci-dessus peuvent héberger les données qui alimentent les charges de travail liées à l’IA. Cependant, les performances, le coût et la sécurité de l’IA peuvent varier considérablement en fonction de l’option choisie par l’entreprise.
Prenons par exemple le cas d’utilisation courante de l’IA que constitue l’entraînement d’un modèle. Dans la plupart des cas, les données d’entraînement peuvent résider dans n’importe quel type de système de stockage cloud. Mais en fonction des considérations suivantes, un type de stockage peut s’avérer plus adapté que d’autres.
- Évolutivité. Pour héberger de très grandes quantités de données, le stockage objet est généralement idéal, car son évolutivité est pratiquement illimitée.
- Structure des données. Si vous entraînez un modèle à l’aide de divers types de données non structurées (comme des documents et des fichiers multimédias), le stockage objet est tout à fait adapté. Parce qu’il peut accueillir tout type d’informations. Cependant, lorsque vous utilisez des types de données plus structurés (par exemple, si vous entraînez un modèle à partir d’entrées issues de fichiers journaux), une base de données structurée est susceptible d’offrir de meilleures performances.
- Vitesse d’entraînement. Si vous devez entraîner un modèle particulièrement rapidement, un système de stockage offrant une vitesse d’entrées/sorties élevée peut s’avérer utile. Par exemple, les débits sur des services comme EBS peuvent être jusqu’à environ 20 fois plus rapides que ceux de S3. Les bases de données en mémoire (RAM) offrent également des performances d’entrées/sorties très élevées, mais elles ont tendance à être très coûteuses.
- Coût. Les systèmes de stockage en cloud présentent des coûts variables. Si l’on considère le coût par gigaoctet de données, le stockage objet est généralement la solution la moins chère pour stocker des données dans le cloud. Ce qui le rend intéressant, si vous disposez d’un très grand ensemble de données d’entraînement. Il existe toutefois des exceptions. Par exemple, une base de données peut s’avérer plus rentable si vous disposez de nombreux petits ensembles de données structurées, tandis que le stockage objet tend à être le plus abordable lorsque l’on travaille avec des fichiers de tailles très variables.
Des variables comme celles-ci illustrent l’importance de peser le pour et le contre lors du choix d’un système de stockage cloud pour l’IA. Ainsi, si l’optimisation des coûts est une priorité lors de l’entraînement d’un modèle, il est plus judicieux d’utiliser le stockage objet. À l’inverse, le stockage en blocs ou une base de données en mémoire constituent un meilleur choix si l’objectif principal est de réduire la durée globale de l’entraînement.
Bonnes pratiques en matière de stockage cloud pour les traitements d’IA
Outre le choix du type de stockage cloud idéal pour une charge de travail ou un cas d’utilisation d’IA donné, les entreprises doivent également tenir compte des bonnes pratiques ci-dessous. Elles contribuent à optimiser les performances et le coût du stockage cloud dans le cadre de tout déploiement d’IA.
Le nettoyage des données. Le nettoyage des données consiste à supprimer d’un ensemble de données les informations inexactes, redondantes ou de mauvaise qualité. Le nettoyage des données d’IA est essentiel pour améliorer les performances des modèles d’IA. Il permet également de réduire les coûts de stockage et d’améliorer l’évolutivité du stockage, en diminuant le volume global de données que les systèmes de stockage en cloud doivent héberger.
Une observabilité des pipelines de données. Pour vous assurer que le stockage cloud que vous utilisez fonctionne comme prévu, surveillez et observez les pipelines de données, c’est-à-dire les chemins empruntés par les données lorsqu’elles circulent entre les systèmes de stockage et les charges de travail d’IA.
L’observabilité permet d’identifier les goulets d’étranglement, tels qu’un type de fichier spécifique qui met plus de temps que prévu à atteindre une application d’IA. Elle peut également faciliter le suivi des coûts en permettant de suivre la quantité de données que vous stockez et transférez. Gardez à l’esprit que de nombreux services de stockage cloud facturent non seulement en fonction du volume global de stockage, mais aussi en fonction de la fréquence à laquelle les clients transfèrent les données ou accèdent à celles-ci.
La prise en compte des tiers de stockage. Certains types de systèmes de stockage en cloud, en particulier le stockage objet, proposent plusieurs niveaux de stockage. Ceux-ci se répartissent généralement en trois catégories principales : « hot », « warm » et « cold ». Plus le niveau de stockage est « hot », plus l’accès aux données est rapide pour les charges de travail, mais plus le coût pour le client est élevé.
Pour optimiser l’équilibre entre le coût du stockage et les performances, sélectionnez le niveau de stockage adapté en fonction du type de charge de travail. Par exemple, pendant l’entraînement des modèles, il est plus judicieux de conserver les données dans un stockage « hot », où les modèles peuvent les ingérer plus rapidement. Après l’entraînement, si l’entreprise souhaite conserver les données d’entraînement à portée de main, au cas où elle déciderait de réentraîner un modèle ultérieurement, les données peuvent être migrées vers un stockage « cold ».
La protection des données. Comme pour tout type de charge de travail, vous devez protéger les données utilisées et générées par les modèles d’IA en les sauvegardant. Bien que les services de stockage en cloud connaissent rarement des temps d’arrêt, ils peuvent tout de même tomber en panne. De plus, les utilisateurs ou les applications d’IA elles-mêmes peuvent supprimer accidentellement des données, d’où l’importance cruciale de disposer de sauvegardes.
Pour ces raisons, les entreprises devraient investir dans des solutions de protection des données pour leurs systèmes de stockage en cloud. La meilleure façon de procéder dépend du type de système de stockage et des données concernées. Dans certains cas, il peut suffire de simplement faire des copies des données et de les stocker dans le même cloud que les données principales.
Mais pour plus de fiabilité, envisagez de copier les données vers un autre cloud ou vers un stockage sur site, ce qui permettra de garantir leur disponibilité en cas de défaillance du cloud principal. Configurer le stockage de sauvegarde pour qu’il soit immuable – ce qui rend impossible la suppression ou la modification des données – peut également renforcer la protection en empêchant l’effacement malveillant ou accidentel des sauvegardes.
Cet article est initialement paru en anglais sur SearchCloudComputing.
Pour approfondir sur Stockage en Cloud
-
![]()
Administration IT : comment simuler des réseaux à l’ère de l’IA
Par: Verlaine Muhungu
-
![]()
Nutanix lance son « meilleur Kubernetes pour exécuter les IA »
Par: Yann Serra
-
![]()
Sauvegarde : comment l’IA peut aider à mieux restaurer les données
Par: Kathleen Richards
-
![]()
« Dans l’IA, la priorité, c’est l’optimisation des data. Pas leur vitesse » (George Kurian, NetApp)
Par: Yann Serra



