
itestro - Fotolia
Einstein One : Salesforce fait la lumière sur l’architecture de Data Cloud
Le géant du CRM profite de sa grand-messe pour mettre en avant les évolutions de sa CDP devenue une plateforme de données cloud, pour l’instant consacrée à l’unification de profils clients. L’occasion pour ses porte-parole d’ouvrir le capot.

Il est parfois difficile de suivre la progression des produits Salesforce. C’est d’autant plus vrai que l’éditeur a l’habitude d’appliquer de nouvelles couches de peinture marketing à l’occasion de sa grand-messe Salesforce.
Ainsi naît Einstein One, une plateforme issue du croisement de Data Cloud (ex Genie, désormais une simple mascotte), des capacités de machine learning et d’IA placées sous la marque Einstein. Einstein 1 est présenté comme une solution « intégrée, intelligente, automatisée, low-code/no-code et ouverte ».
La vision qui sous-tend Einstein One
Einstein 1 a-t-il une existence en dehors de l’esprit d’un directeur marketing ? Est-il encore une fois un renommage ? « Les deux. Il s’agit d’un changement de marque et cette annonce inclut un grand nombre de nouveautés », affirme Rahul Auradkar Executive Vice-Président et directeur général, Unified Data Services and Einstein chez Salesforce auprès du MagIT.
Sur le papier, Salesforce prévoit la disponibilité d’une trentaine de fonctionnalités dans une dizaine de catégories (Sales, Commerce, Tableau, Mulesoft, etc.), d’ici à la fin de l’année 2024, rattachées à Einstein 1. Six d’entre elles sont d’ores et déjà disponibles, tandis que huit autres devraient être accessibles en pilote, en bêta ou en disponibilité générale d’ici à la fin de l’année.
Il faut distinguer des capacités constitutives de l’offre Einstein 1.
Premièrement, Data Cloud, qu’il faut désormais nommer Einstein 1 Data Cloud, bénéficie depuis peu de la capacité à traiter les données en quasi-temps réel. Deuxièmement, Salesforce a imaginé l’Einstein Trust Layer pour contrôler les faits et les contenus produits des grands modèles de langage.
Troisièmement, Salesforce a formalisé une couche de métadonnées partagée entre Data Cloud, Einstein et le CRM. « C’est la clé de l’intégration », avance Marc Benioff, PDG de Salesforce. Au milieu réside le CRM et ses applications : Sales, Service, Commerce, Marketing, Analytics, Platform et l’ensemble des déclinaisons par industrie.
Enstein 1 peut être connecté à des systèmes externes via Mulesoft et AppExchange, mais également aux services Google Workspace, Microsoft 365, Heroku, Tableau, Canvas et Slack.
C’est en tout cas la vision qui en est donnée par les porte-parole de l’éditeur lors du keynote d’ouverture du salon.
Einstein One Data Cloud ou l’unification des profils clients
« Einstein One inclut Data Cloud, la plateforme cœur et les applications », résume Rahul Auradkar. « Nous avons apporté tellement d’innovations avec le Data Cloud et avec l’IA, que nous devions les regrouper et fournir à nos clients une nouvelle manière d’expliquer à quoi elles ressemblent », justifie-t-il.
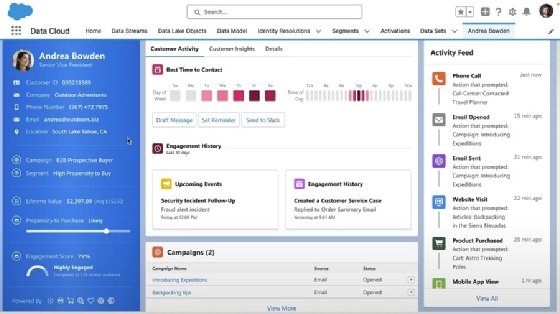
Le choix de la marque est clair, mais quelles sont ces innovations ? Selon Rahul Auradkar, la couche de métadonnées, d’abord associée, a grandi depuis la création de la société.
« Ce que la couche de métadonnées vous donne, c’est la possibilité pour vous, en tant que client de Sales Cloud, Services Cloud et de tous nos clouds, de déployer des objets disponibles sur étagère, de les modifier et d’ajouter vos propres objets personnalisés », explique-t-il. « Parce que l’abstraction passe par la couche de métadonnées, tout ce que vous faites avec les objets personnalisés peut être transféré avec les mises à jour, tout en restant compatible avec l’application ».
Ces derniers mois, la nouveauté tient dans le rapprochement des données structurées, semi-structurées voire non-structurées qui résident dans Data Cloud avec celles du CRM.
« Nous avons trouvé un moyen de prendre toutes les données enrichies qui résident dans Data Cloud et nous les avons intégrées étroitement dans la plateforme de métadonnées sous forme d’objets », insiste-t-il.
Le Data Cloud est, selon Rahul Auradkar, un « data lake commun qui inclut toutes les données » en provenance des bases de données relationnelles spécifiques à Sales Cloud, Service Cloud, etc., et des données d’engagement « pour unifier les profils clients dans le CRM ».
« Vous pouvez harmoniser, unifier et générer des informations à partir de ces données. Et nous pouvons réinjecter ces informations dans Sales Cloud et Data Cloud, par exemple ».
Reverse ETL et Apache Iceberg : Salesforce, un partisan de la « modern data stack »
Chez Salesforce, ce processus est nommé enrichissement des données. Il passe par l’utilisation d’un Reverse ETL, qui consiste à récupérer plus ou moins dynamiquement les données d’engagement et clients.
Ce Reverse ETL peut être utilisé pour copier les champs à réconcilier dans une nouvelle table d’une base de données relationnelles liée à une Org Salesforce (Sales Cloud, Service Cloud, Marketing Cloud, etc.). Comme les sites Web et les API, les data lake tiers ou les object store S3, GSE et Azure Blob Storage sont pour l’instant majoritairement des sources, mais sont voués à devenir des cibles de ce système bidirectionnel.
« Pour l’instant, les données copiées dans le data cloud et toutes les opérations sont effectuées là », indique Muralidhar « MK » Krishnaparsad, EVP Engineering, Next Gen Customer 360 Data services, chez Salesforce. « Mais ensuite, nous le recopions dans le système de transaction parce qu’il peut y avoir d’autres choses à faire sur cet objet transactionnel ».
Un autre moyen d’enrichissement n’implique pas la copie de données, mais la production « d’enregistrements reliés » [Related Record en VO]. « Les données d’engagement peuvent contenir des millions d’enregistrements que l’on ne souhaite pas tous traiter », explique Muralidhar Krishnaparsad.
« Nous créons une sorte de jointure de métadonnées entre les deux pour dire que ce contact X est lié aux engagements Y sur ce site Web », poursuit-il. « Ainsi, lorsque vous exécutez une requête SOQL [le DSL SQL de Salesforce N.D.L.R] qui dit “select web engagement from select this contact record”, nous allons chercher cet enregistrement de contact et nous verrons si vous avez la permission d’effectuer la requête. Si c’est le cas, nous effectuerons une jointure complète pour récupérer le sous-ensemble de données ».
La réconciliation des données sources avec les données d’engagement est nommée Data Model Object (DMO). Le tout peut aussi servir à effectuer des calculs comme la valeur à vie d’un client ou dresser l’historique de ses interactions auprès du service client et de ses achats.
Sous le capot, ce mécanisme de Reverse ETL est motorisé par Apache Spark. Salesforce exploite le format de table Parquet pour les stocker dans S3 et utilise le standard GDBC pour proposer des connecteurs vers différentes sources de données en entrée et en sortie de son Reverse ETL. « Nous utilisons également Apache Iceberg, ce qui permet de partager les tables, par exemple sur Snowflake », détaille Rahul Auradkar.
Selon Muralidhar Krishnaparsad, Apache Iceberg est beaucoup plus important que le laisse entendre son collègue. « Chez nous, tous s’appuient sur Apache Iceberg et Parquet », affirme-t-il.
Salesforce peut générer un token sécurisé pour ses clients qui voudraient requêter les données de Data Cloud avec Snowflake, BigQuery ou Amazon Redshift.

Salesforce a même contribué aux projets Iceberg. « Nous l’avons amélioré. Au départ le format ne permettait pas les mises à jour quasi-temps réel », affirme le responsable. « Et nous plaçons les métadonnées Salesforce dans les tables Iceberg ». Un format que les trois acteurs cités ci-dessus prennent désormais en charge. Le géant du CRM est également entré en partenariat avec Databricks, lui qui préfère son format open source Delta Table et le protocole de partage Delta Sharing.
Data Cloud est hébergé par défaut sur AWS. Les capacités de ce data lake reposent sur différents services dont RDS, EMR, EMR on EKS, S3, Elasticache, DynamoDB, SQS et Data Sync.
Ingérer les données au « bon moment », pas forcément en temps réel
L’un des arguments majeurs mis en avant par le géant du CRM est que cette phase d’enrichissement peut être effectuée en temps réel.
Cette notion de temps réel, somme toute abstraite, entraîne des confusions. « C’est moins le temps réel que le bon moment qui compte », défend Rahul Auradkar [« We should think about real time as right time » en VO, N.D.L.R].
« Le contexte est important. Dans certains cas, vous voulez que l’ensemble d’un corpus de données soit utilisé et vous êtes à l’aise avec un temps de latence de 5 à 10 minutes », poursuit-il. « Dans d’autres, vous voulez agir sur un petit jeu de données pour répondre en quelques secondes », assure l’EVP & GM Data & Einstein chez Salesforce.
« Parfois, vous sondez un site Web en quelques millisecondes afin de personnaliser la page suivante. Nous répondons à ces trois cas d’usage ».
De fait, Einstein 1 Data Cloud prend en charge les ingestions de données en batch, en streaming et event-driven.
À l’interface pour choisir la source et la cible du processus ETL, s’ajoute une autre UI établie à partir de Salesforce Flow pour déclencher des événements en temps réel. « Vous pouvez créer un flux à partir de n’importe quel objet dans le système », avance Muralidhar Krishnaparsad. « Il peut s’agir d’un engagement sur un site Web, quelqu’un qui navigue sur votre site. Comment se fait-il qu’il y ait trop d’erreurs sur votre page ? Ou peut-être avez-vous calculé un nouvel indicateur et avez-vous besoin d’un score de conversion ? », illustre-t-il.
Ce reverse ETL, couplé à la couche de métadonnées, est au cœur d’un outil de représentation graphe des données nommé Data Model Graph View. Celui-ci permet d’exposer les relations entre les objets et les données configurés dans la plateforme Salesforce. Il est possible de générer un fichier JSON qui retranscrit ces relations pour un profil client.
« À partir de ce graphe, vous pouvez faire beaucoup de choses : de la réconciliation d’identités, créer des visualisations radiales via Tableau, effectuer des calculs de segmentation pour des données tierces ou Salesforce à l’aide de modèles de machine learning entraînés sur Databricks ou bien SageMaker », illustre Muralidhar Krishnaparsad.
Data Cloud rend curieux, même en dehors du secteur BtoC
Techniquement, Salesforce entend « briser un plafond de verre » pour ses gros clients qui souhaitent intégrer davantage de données dans Salesforce et qui étaient limités par les capacités de la plateforme.
« Nous sommes passés d’une CDP, à savoir l’acte de segmentation dans un but marketing, au Data Cloud, c’est-à-dire à l’exploitation de multiples sources de données – pouvant venir des réseaux sociaux, de points de vente physique, d’un site e-commerce – exploitées pour mesurer l’usage et les tendances marché », résume Emilie Sidiqian, vice-présidente exécutive et directrice générale de Salesforce France.
Une plateforme qui pourrait dépasser le monde du marketing et du e-commerce BtoC si Salesforce arrive à répondre aux interrogations de ses clients. « Ça m’a l’air intéressant », estime Christine McDonald, directrice de la transformation numérique chez EcoVadis, un spécialiste international de la mesure RSE siégeant à Paris et client de Salesforce. « Pour l’heure, nous avons une architecture complexe qui repose sur Databricks et qui nous sert pour effectuer des backups et des synchronisations », précise-t-elle. « Mais Data Cloud doit être approuvé par nos architectes. De ce que nous avons pu voir pendant Dreamforce, je me demande s’il y a les règles métiers suffisantes pour nous ».
Ses clients devraient pouvoir se faire une idée de capacités de Data Cloud. Salesforce annonce que le produit est désormais intégré « dans toutes les éditions entreprises ou plus » de Salesforce sans coût supplémentaire. Les clients peuvent unifier les profils de 10 000 clients et effectuer des analyses à l’aide de deux licences Tableau.
Pour approfondir sur Big Data et Data lake
-
![]()
MDM et IA agentique : Informatica consolide ses ponts avec Salesforce
Par: Gaétan Raoul
-
![]()
Salesforce et Informatica tracent les grandes lignes de leur feuille de route commune
Par: Gaétan Raoul
-
![]()
Service client : Salesforce prépare des agents (semi) autonomes
Par: Don Fluckinger
-
![]()
Salesforce pousse Data Cloud et Einstein Copilot aux clients français
Par: Gaétan Raoul



