Einstein Copilot Studio : Salesforce veut aider ses clients à dompter l’IA générative
À la fois un outil de prompt engineering et une couche d’orchestration d’actions, Einstein Copilot Studio doit aider les clients de Salesforce à encadrer les modèles d’IA générative dans le contexte de la relation client. Pour le prouver, les porte-parole du groupe n’hésitent plus à dévoiler les rouages sous-jacents de leur solution.
La thématique phare de la conférence Dreamforce 2023 n’était autre que l’IA générative. Salesforce en a profité pour préciser sa feuille de route en la matière.
Le géant du CRM a présenté Einstein Copilot, un assistant « sur étagère » disponible en phase de pilote. Il a pour vocation à devenir la « nouvelle interface conversationnelle » pour les métiers qui utilisent les différents « Cloud » et les applications Salesforce. Einstein Copilot permettra d’obtenir des recommandations ou d’effectuer des recherches documentaires dans une Org Salesforce. Il ne faut pas le confondre avec les offres GPT, qui servent aux métiers à générer certains types de contenus dans Commerce, Sales, Services Cloud et autres.
L’éditeur spécialiste du CRM a surtout mis l’accent sur Einstein 1 Copilot Studio, connu aussi sous le nom d’Einstein Copilot Studio ou d’Einstein Studio. Il entrera en phase pilote au cours de l’automne 2023.
Peu importe le nom, ce studio incorpore trois produits : Prompt Builder, Skills Builder et Model Builder.
Pour Salesforce, Prompt et Skill Builders sont des cadres délimités pour développer des agents conversationnels capables de déclencher des flux dans différents « Cloud » Salesforce. Il s’agit de simplifier la conception de chatbots.
« Si vous venez du monde des interfaces conversationnelles traditionnelles, il faut définir de manière totalement déterministe les dialogues dans lesquels je veux que mes clients atterrissent », explique Carlos Iván Lozano, Directeur de la gestion produit, Salesforce AI – Conversational Assistance chez Salesforce.
Cela consiste à élaborer une liste des possibilités que l’utilisateur pourra rencontrer lors de ses interactions avec un agent conversationnel. Si l’une d’entre elles n’est pas envisagée, le bot ne pourra pas satisfaire la demande d’un métier ou d’un client. « Et il faudra le faire dans plusieurs langues, si l’on souhaite couvrir l’ensemble des localités d’une entreprise. Nous voulons éliminer cette complexité », affirme Carlos Iván Lozano.
Au lieu d’établir un schéma qui cartographie ces possibilités, il suffit, avec Prompt Builder et Skills Builder, de toutes les enregistrer au préalable dans un prompt exploité en back-office avant de pouvoir répondre.
Prompt builder : un « Playground » simplifié
« Nous utilisons un LLM pour faire deux choses. Premièrement, et de manière classique, il génère des réponses (écriture d’e-mails, résumé des requêtes de support client, etc.) », raconte le directeur de la gestion produit.
Le prompt builder reprend les éléments constitutifs du Playground d’OpenAI tout en simplifiant les fonctionnalités disponibles. Il permet d’établir des templates de prompts, autorisés par l’organisation pour effectuer ces actions.
« Par exemple, un spécialiste du marketing peut demander à Prompt Builder de générer un message personnalisé et une remise pour un nouveau produit en fonction de l’historique d’achat du client et de sa localisation », illustre Salesforce, dans un communiqué.
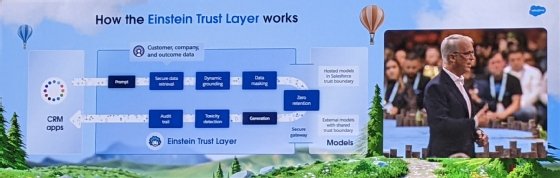
Pour ce faire, l’éditeur met en avant sa « Trust Layer » en la présentant comme un cycle pour maîtriser les générations des modèles d’IA générative. Techniquement, elle est plus diffuse qu’il n’y paraît. L’un des éléments, souvent mis en bout de chaîne dans son infographie, est, en réalité, activé dès la préparation de ces prompts réutilisables. En l’occurrence, il s’agit de l’outil de mesure de toxicité. Pour ce faire, Salesforce a développé en interne un autre LLM chargé d’évaluer la toxicité d’une requête et de sa réponse.
Parker Harris, CTO de Salesforce, présentant l'Einstein Trust Layer lors de Dreamforce 2023.
Celui-ci a été entraîné à partir d’un corpus de données « extrêmement toxiques » pour identifier les entrées et les sorties les plus nuisibles d’un autre modèle. Depuis l’interface de Prompt Builder, si une requête et sa réponse sont jugées néfastes (« harmful », en VO), une pastille rouge s’affichera. Il ne sera pas possible d’enregistrer le template. En outre, il est possible de configurer des paramètres pour ajuster la tonalité du bot, son style, l’audio, la longueur des réponses, ou encore sa capacité à suivre plus ou moins précisément une instruction. « Les seuils de toxicité sont pour l’instant définis par Salesforce », prévient Carlos Iván Lozano.
Lors de cette phase, il est possible d’enrichir un prompt avec des données clients. Ces données proviennent alors de Data Cloud. Les données réconciliées peuvent être un outil de représentation graphe des données, nommé Data Model Graph View. Celui-ci permet d’exposer les relations entre les objets et les données configurés dans la plateforme Salesforce. L’outil produit automatiquement un fichier JSON qui retranscrit ces relations pour un profil client. Les données personnelles ou sensibles peuvent être masquées dans l’interface de Prompt Builder ou avant, dans Data Cloud.
Ce fichier JSON peut être utilisé pour guider la réponse d’un agent conversationnel propulsé à l’IA générative. Plus particulièrement, il est possible de pointer ce fichier dans un prompt édité dans Einstein Copilot Studio.
Skills Builder : une couche d’orchestration d’actions propulsée par un LLM
« Deuxièmement, nous exploitons le LLM pour planifier, comprendre et exécuter une action », poursuit Carlos Iván Lozano. « Le modèle doit comprendre la question, la décortiquer en petites intentions, générer un plan et l’exécuter ».
Ce plan exécute les actions en séquence. « À chaque question que l’utilisateur pose, nous régénérons un nouveau plan ».
Une Org Salesforce dispose d’actions pour traiter des données : des flux en provenance de Flow, des données issues des Org ou encore un catalogue d’API. Un Skill représente une collection d’actions pour activer des tâches. « Les actions de l’Org Salesforce sont regroupées, puis fournies dans un format lisible par une couche d’orchestration ». Sous le capot, cette couche d’orchestration n’est autre qu’un LLM à qui l’on confie une liste de tâches. Il peut exécuter ces actions parce qu’elles ont été définies sémantiquement. « Chaque action doit avoir un nom et une description précise », signale Carlos Iván Lozano.
Ainsi, la couche d’orchestration n’est pas dépendante d’une logique « If Then, Then That » (IFTTT) prédéfinie. « Chaque action a des entrées et des sorties. Elles doivent être très bien décrites sémantiquement ». En clair, cette couche contient des conditions obligatoires, mais le LLM n’a pas appris des branches de dialogue spécifiques.
« Le LLM va effectuer une levée d’ambiguïté : si une condition n’est pas remplie dans la requête d’un utilisateur, alors il va lui répondre en réclamant de manière autonome la donnée manquante. Il suffit de fournir les actions dont il a besoin ».
« Le LLM va effectuer une levée d’ambiguïté : si une condition n’est pas remplie dans la requête d’un utilisateur, alors il va lui répondre en réclamant de manière autonome la donnée manquante. »
Carlos Iván LozanoDirecteur de la gestion produit, Salesforce AI – Conversational Assistance, Salesforce
La demande peut ne pas correspondre aux informations auxquels le LLM a accès dans le prompt et plus largement dans ses données d’entraînement. Dans ce cas, Salesforce a mis en place un système de recherche sémantique de similarité pour retrouver dans les templates de prompts et les actions la réponse correspondante. « Dans ce cas, c’est beaucoup plus facile, c’est presque déterministe », indique le directeur de la gestion produit, Salesforce AI – Conversational Assistance.
Selon Rahul Auradkar, Executive Vice-Président et directeur général, Unified Data Services and Einstein chez Salesforce, l’éditeur développe ses propres algorithmes de correspondance exacte pour retrouver les données d’un client, comme son numéro de téléphone ou son adresse. Ceux-là peuvent être utilisés dans différents contextes liés à la CDP Einstein One Data Cloud et à Einstein Copilot Studio.
À l’avenir, les Skills contiendront des templates pour réunir les informations d’une base de connaissances, puis les vectoriser. Dans ce cas-là, Salesforce associera sa couche d’orchestration à un moteur de type Apache Lucene et son algorithme de recherche des plus proches voisins (KNN) afin de faciliter la recherche et le résumé de documents.
« Nous aurons nos propres embeddings pour représenter les données non structurées présentes dans la plateforme », anticipe Rahul Auradkar. « [Les entreprises] pourront également effectuer des recherches sur des embeddings en provenance d’un autre système et combiner les deux sources, puis envoyer le tout à un LLM. De nombreuses possibilités s’offrent à nous pour répondre à la plupart des cas d’usage ».
Du côté de Skills Builder, il est prévu que les partenaires et les clients de Salesforce puissent développer et partager des packages de Skills, les fameux regroupements d’actions. Pour l’instant, les actions sont restreintes à certains objets et flux Salesforce.
Einstein Copilot Studio et les trois LLMs
Cette liste d’actions organisée par la couche d’orchestration semble limitée par la fenêtre de contexte du grand modèle de langage, c’est-à-dire sa capacité à traiter un prompt en entrée. Or, tous les LLM ne sont pas sur un même pied d’égalité en la matière. « C’est pour cela que nous utilisons Ferrari 1 et Ferrari 2, à savoir GPT-4 et Claude 2, pour la planification et l’orchestration des actions », répond Carlos Iván Lozano. En clair, la couche d’orchestration est un prompt confié à un LLM capable d’emmagasiner jusqu’à 32 000 tokens. « Ensuite, les résultats peuvent être transmis à un autre LLM afin de générer le contenu souhaité », détaille-t-il.
« Nous attendons que quelqu’un dans l’industrie publie des critères de référence que nous pourrions utiliser pour faire des comparaisons. »
Rahul AuradkarExecutive Vice-Président et directeur général, Unified Data Services and Einstein, Salesforce
Au total, Einstein Copilot Studio et la Trust Layer sont propulsés par trois grands modèles de langage différents.
« Les résultats les plus pertinents, pour l’instant, nous les avons obtenus avec les modèles d’OpenAI et d’Anthropic », constate Carlos Iván Lozano. Salesforce a également testé les technologies de Google, de Cohere, et les modèles disponibles sur HuggingFace.
« Nous attendons que quelqu’un dans l’industrie publie des critères de référence que nous pourrions utiliser pour faire des comparaisons », tempère Rahul Auradkar. « Nous avons nos propres benchmarks, mais nous avons besoin d’un organisme indépendant qui prenne ce sujet à bras-le-corps ».
Des partenariats clés qui n’empêchent pas les développements en interne
C’est là qu’intervient Model Builder. Cet outil permettra d’utiliser des modèles LLM importés par des administrateurs Salesforce pour la génération de contenu. Cette approche « bring your own model » est déjà disponible dans Data Cloud pour les algorithmes d’analyse prédictive. Salesforce prévoit des intégrations avec Amazon Bedrock, Google Vertex AI, Databricks d’un côté, et Cohere, Anthropic et OpenAI de l’autre.
Peu importe le cas, une fois que l’application finale est terminée, Salesforce proposera de mettre en place Anypoint Flex Gateway, une passerelle API développée par MuleSoft. Celle-ci sera chargée d’identifier les utilisateurs, les données personnelles dans un prompt, de filtrer les données suivant les autorisations, de limiter la taille des prompts (pour des raisons de coûts, entre autres), de valider les réponses ou de les refuser quand elles sont nocives. Cette passerelle API sera également disponible en dehors du monde Salesforce.
Le géant du CRM n’écarte pas la possibilité de proposer ses propres modèles. Salesforce AI Research a développé les modèles LLM Xgen et Xgen Mobile. Fortement inspiré de Llama 1, Xgen est un modèle de sept milliards de paramètres doté d’une fenêtre de contexte de 8 000 tokens. Il a été entraîné sur 1,5 billion de tokens (dont du code APEX) de données à l’aide d’instances Google Cloud équipées de TPUv4. Xgen Mobile est, comme son nom l’indique, une version compressée de ce modèle afin qu’il puisse s’exécuter sur un smartphone sans besoin d’accéder à Internet.
Pour approfondir sur Intelligence Artificielle et Data Science