Bases de données : le cloud a-t-il tué le stockage sur site ?
Le Data warehouse – qui rapatrie toutes les données pour les interroger avec des requêtes SQL – était le domaine des grandes appliances physiques. Mais le cloud met fin à leur règne.

Les appliances dédiées à l’entrepôt de données – ou Data warehouse, en anglais – constituaient jusqu’à récemment le meilleur type d’équipement pour résoudre les problèmes de performances des moteurs d’analyses qui reposent sur des bases de données locales. Cependant, l’offre de services en ligne a atteint un tel degré de maturité que le stockage d’un Data warehouse fait désormais partie des produits en cloud les plus communs.
Les jours des appliances de stockage pour l’entrepôt de données sont-ils dès lors comptés ? Il est légitime de se poser la question au regard des inconvénients de ces équipements. Il s’agit de matériels imposants, coûteux à acquérir, à exploiter et à entretenir. Il n’est pas possible, par exemple, d’étendre un petit peu la capacité des appliances physiques au fil des évolutions des besoins. Il faut nécessairement prévoir des extensions importantes, avec de grandes quantités de capacité susceptibles de rester inutilisées pendant un certain temps.
Et précisons qu’il ne s’agit pas juste d’une absence de variété dans les modules matériels du constructeur. Non, étendre une telle appliance implique des reconfigurations logicielles et réseaux si complexes qu’aucune entreprise n’irait s’y aventurer pour simplement ajouter de petites extensions de capacité.
Pendant ce temps, les géants du cloud – au moins Amazon AWS, Microsoft Azure et Google GCP – proposent des services en ligne qui remplissent la même fonction de stockage d’un entrepôt de données, voire intègrent dans un prix global des outils supplémentaires comme l’ETL ou la visualisation des données.
Au lieu de devoir réunir une grosse somme pour acheter une bonne fois pour toutes une appliance (le « Capex »), sans pouvoir toutefois se passer des frais de maintenance et d’exploitation au long court, le cloud a même l’avantage de facturer mensuellement une souscription globale. Elle comprend la ressource d’infrastructure et toute sa maintenance, effectuée par le fournisseur de cloud.
Enfin, il y a une raison supplémentaire qui pourrait inciter les entreprises à abandonner leurs infrastructures physiques de Data warehouse : celles-ci sont délaissées par les constructeurs eux-mêmes. Au profit de versions virtuelles disponibles en cloud.
Comment fonctionne un Data Warehouse
Pour nourrir la réflexion sur le bien-fondé d’une appliance physique ou d’un service en ligne, il faut comprendre comment fonctionnent les rouages d’un Data warehouse. L’entrepôt de données est alimenté par le lac de données. Le lac de données est le dépôt qui contient toutes les données de l’entreprise. Il peut s’agir de données structurées (bases de données), non structurées (fichiers), semi-structurées (des fichiers avec des métadonnées, comme en stockage objet). Le lac de données est le domaine du data scientist.
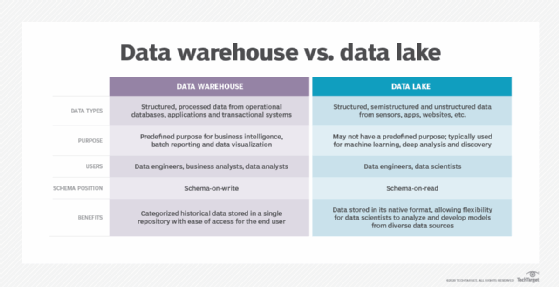
Le lac de données est anarchique, tandis que l’entrepôt de données est un environnement ordonné, qui ne comprend plus que des données structurées dans des bases de données.
Les lacs de données sont inaccessibles aux utilisateurs, ou même à la plupart des informaticiens. Les données peuvent y être cherchées et, dans une certaine mesure, interrogées via leurs métadonnées afin de déterminer d’où elles viennent, à quel usage elles correspondent. Mais les lacs de données ne sont pas l’endroit où l’analyse opérationnelle a lieu – c’est l’endroit où les données résident avant d’être présentées aux processus analytiques.
Les données peuvent se présenter sous une multitude de formes et leur récupération est souvent appuyée par des systèmes d’étiquetage comme Hadoop, Apache Spark, ou encore Amazon Athena (en cloud), lesquels facilitent le processus d’ingestion et d’analyse.
Lorsque les données arrivent dans l’entrepôt de données, elles ont été évaluées, triées et généralement soumises à un processus d’extraction, de chargement et de transformation des contenus (ETL, pour Extract, Load and Transform). Ensuite, elles sont entreposées dans une ou plusieurs bases de données présentes au sein de l’entrepôt de données.
De simples serveurs avec SSD QLC, mais beaucoup de paramétrages
Dans leur définition historique, les entrepôts de données sont presque toujours dédiés à la seule analyse a posteriori. Ils sont séparés du traitement des transactions pour des raisons de performance. En soi, un entrepôt de données n’a pas besoin d’avoir un accès aussi rapide que celui des bases de données transactionnelles. Pour autant, il faut que la bande passante de ses entrées/sorties (E/S) supporte nombre de trafics séquentiels, notamment lorsque des ensembles entiers de données sont consultés ou répliqués, à l’occasion des traitements analytiques.
Ces exigences ont souvent signifié que les disques durs sur lesquels repose l’entrepôt de données devaient être raisonnablement performants. Aujourd’hui, si l’on recommande de plutôt utiliser des SSD que des disques durs, les modèles de type QLC suffisent, car ils ont toutes les aptitudes pour servir les accès séquentiels.
Il est possible de construire son propre entrepôt de données à partir d’éléments d’infrastructures sur étagère. La mise au point du stockage est d’ailleurs une partie relativement facile du processus. Mais le choix du matériel est secondaire au regard des efforts de conception qui garantiront la pérennité de la solution. Il faut choisir des matériels adaptés aux charges de travail visées, un système d’exploitation, un moteur de bases de données (SGBD), une certaine connectivité et, bien entendu, un certain type de stockage. Tous ces paramètres sont préconfigurés sur les appliances.
L’offre traditionnelle des appliances
La première appliance de stockage pour entrepôt de données fut lancée en 2001 par Netezza, un fournisseur racheté par IBM en 2010. Le produit a été relooké, a disparu au milieu de la décennie, puis a ressuscité vers 2019, lorsque IBM a racheté Red Hat.
Le mérite de l’appliance proposée sous la marque Netezza est qu’elle repose aujourd’hui sur du stockage 100 % flash et que ses traitements sont exécutés par un FPGA spécialement adapté. Elle permet aussi un fonctionnement en cloud hybride, avec des versions virtuelles exécutées en ligne.
Teradata est un autre acteur majeur du domaine. Il propose toujours aux entreprises des appliances matérielles IntelliFlex, mais les seconde à présent avec des appliances virtuelles intelliCloud en cloud. Le fournisseur a mis en place un service en ligne, Teradata Everywhere, qui permet aux utilisateurs d’envoyer des requêtes vers plusieurs bases de données, publiques et privées, simultanément. Il fonctionne en l’occurrence en mode MPP (Massive Parallel Processing), ce qui signifie que les charges de travail sont autonomes, que leur fonctionnement individuel ne s’approprie pas de la puissance de calcul au détriment des autres.
EMC commercialisait autrefois l’équipement Greenplum. Celui-ci n’existe plus aujourd’hui que sous forme logicielle. Greenplum repose sur un moteur de base de données PostgreSQL hautement parallélisé. Il est utilisable en cloud, comme depuis des serveurs sur site.
Oracle, enfin, a été l’un des grands fournisseurs d’appliances pour le Data warehouse, avec ses machines Exadata. Son offre vedette est à présent Autonomous Data Warehouse. Il s’agit d’un service disponible sur le cloud d’Oracle et éventuellement transposable sur site au sein d’une appliance baptisée Cloud@Customer. Il repose sur la base de données Oracle.
Les services en ligne
Amazon Redshift
Amazon Redshift est le service d’entrepôt de données managé que propose AWS. Il permet de commencer des projets avec quelques centaines de gigaoctets (Go) de données, puis d’évoluer jusqu’à des pétaoctets (Po). Pour créer un entrepôt de données, il suffit de lancer un ensemble de nœuds appelé un cluster Redshift.
Ingérer des données dans Redshift et les analyser se fait à l’aide d’outils SQL, mais aussi via des applications prêtes à l’emploi pour l’intelligence économique. Redshift se pilote depuis une console graphique dédiée, depuis une interface en ligne de commande (CLI), et depuis des API. AWS cible avec cette offre les entreprises qui souhaitent migrer leurs bases de données Oracle en cloud.
Il existe des bundles commerciaux comprenant l’ETL Matillion et Tableau, pour la visualisation des données. Une déclinaison appelée Redshift Spectrum permet quant à elle d’analyser des données stockées dans S3.
Azure SQL Data warehouse
Azure SQL Data Warehouse est le service managé proposé dans le cloud de Microsoft. Il supporte le stockage de plusieurs Po de données. Il fonctionne soit en mode MPP, soit en mode SMP, lequel consomme moins de ressources en répartissant la puissance de calcul totale entre toutes les charges de travail. Les unités de calcul sont représentées sous la forme d’appliances virtuelles : il est trivial d’ajouter des ressources en cas de charge trop importante.
Dans l’offre de Microsoft, le calcul et le stockage sont deux services différents. Microsoft explique que cela contribue à réduire les coûts, puisqu’il est possible d’éteindre les ressources de calcul quand on ne s’en sert pas, tout en conservant les données dans un état opérationnel (il ne sera pas besoin de les charger à nouveau dans le Data warehouse lors du lancement des prochaines analyses).
Ce service utilise le moteur de base de données Azure SQL et l’ETL Azure Data Factory.
Google BigQuery
BigQuery, enfin, est le service d’appliance de Data warehouse de GCP. Comme les autres, il permet de stocker plusieurs Po et les requêtes se font par SQL.
BigQuery s’accompagne de modules logiciels prêts à l’emploi, notamment pour lancer des travaux de Machine Learning, mais aussi de SIG (Système d’Information Géographique), ou encore de BI (Business Intelligence). Il présente la particularité de pouvoir être alimenté en données depuis Google Sheets, le tableur de la suite bureautique en ligne de Google.
BigQuery est pilotable depuis une console graphique, une interface en ligne de commande ou encore depuis des API. Google présente ce service comme une solution pour migrer des appliances Teradata en cloud. Le service offre aussi certaines facilités pour importer des données traitées jusque-là par le service Redshift du concurrent AWS.
Pour approfondir sur Datawarehouse
-
![]()
Les efforts d’Oracle pour redorer le blason d’Autonomous Data Warehouse
Par: Gaétan Raoul
-
![]()
Pour Qlik, tous les chemins d’intégration mènent au data warehouse (ou presque)
Par: Gaétan Raoul
-
![]()
Quelles perspectives au-delà du data warehouse ?
-
![]()
Datawarehouse : face à AWS et Snowflake, Oracle oppose la simplicité
Par: Gaétan Raoul