Intelligence artificielle : comment Total est passé du « PoC » à la production
Depuis plusieurs années, les Data Scientists de Total développent des modèles d’IA avec des PoC réalisés pour le marketing ou la branche exploration / production. L’industriel explique comment il met aujourd'hui ces modèles en production qui est aujourd’hui industrialisée, grâce aux conteneurs et aux workflows Airflow.
Total s’est intéressé très tôt aux Data Sciences et à l’intelligence artificielle et développe des modèles d'IA depuis des années. L’entreprise numéro 1 au CAC40 manipule énormément de données et s’est forgée une réputation d’innovation en informatique, exploitant les supercalculateurs parmi les plus puissants en Europe.
Nous sommes aujourd’hui convaincus que les techniques de Data Science sont indispensables dans notre transformation numérique.
Arnaud de Almeida, service Data Valorization de Total
Néanmoins, Arnaud de Almeida, à la tête du service Data Valorization Total prévient : « Nous sommes des industriels : notre but, c’est produire et l’informatique ce n’est qu’un outil. L’IA n’est pas une fin en soi, ce n’est qu’un levier pour améliorer notre efficacité opérationnelle. Nous sommes aujourd’hui convaincus que les techniques de Data Science sont indispensables dans notre transformation numérique, c'est-à-dire utiliser de nouveaux outils, être en phase avec de nouveaux modes de travail. »
Arnaud de Almeida, service
Data Valorization Total
Total travaille avec Octo Technology depuis 3 ans
Octo Technology accompagne Total dans sa stratégie IA depuis 3 ans maintenant, notamment pour son activité exploration / production.
Sophânara De Lopez, Data Scientist chez Total évoque ainsi les modèles prédictifs développés dans le domaine de la maintenance d’équipements critiques dans l’extraction du pétrole, les pompes submersibles (ESP, système de pompage électrique submersible). « Le moindre arrêt d’un ESP et la production du puits est stoppée. » Si un ESP peut casser soudainement, il est possible de détecter les signes annonciateurs bien avant que la production s’arrête. « La maintenance prédictive peut d’une part nous aider au niveau local, pour les opérateurs sur les puits et les plateformes qui opèrent ces pompes. Des outils de monitoring en local pourront les aider dans leurs prises de décisions et réagir à un événement potentiel. Le deuxième niveau concerne les experts métiers qui travaillent dans nos Smart Rooms, au siège de Total. Leur rôle est d’aider les opérateurs locaux pour les assister dans la recherche de pannes, pour analyser des événements. »
Chaque pompe ESP est instrumentée de multiples capteurs de pression, de température, de vibrations et de vitesse du moteur, autant de données qui viennent alimenter les modèles prédictifs avec les données contextuelles et opérationnelles et ainsi caractériser le bon fonctionnement ou non de la pompe.
Que Total développe ses propres algorithmes de maintenance pour ses pompes peut sembler surprenant, car GE et les autres fabricants de pompes proposent déjà de tels services de maintenance, dont l'approche "boîte noire" déplaît à Arnaud de Almeida : « Total a fait le choix de comprendre le fonctionnement des équipements que nous mettons en oeuvre dans nos installations. Nous voulons éviter cet aspect boîte noire et ne pas nous mettre à la merci de nos fournisseurs. C’est pour cela que nous avons nos data Scientists et évitons que ces boîtes noires ne nous signalent que nous devons remplacer un équipement sans comprendre pourquoi. Les fournisseurs n’ont pas les mêmes intérêts que nous. »
Passer du PoC à 150 modèles en production
Pour mettre au point ce modèle prédictif, un premier PoC (proof of concept en anglais) est lancé sur un périmètre restreint, sur un seul pays et une dizaine de puits. Le Data Scientist explique : « Nous nous sommes focalisés sur les seules données remontées par les capteurs. Ce PoC a été réalisé rapidement avec un environnement de développement et des serveurs déjà disponibles et après plusieurs itérations nous sommes arrivés à des résultats intéressants. »
Dès lors, s’est posée la question de l’industrialisation de ce modèle et de son passage à l’échelle sur plusieurs pays et non plus sur une dizaine d’ESP mais sur une centaine. En outre, alors que le PoC utilisait un snapshot de données froides, c’est sur des données de mesures directes qu’allait être alimenté le modèle, sachant que chaque pompe est instrumentée de 30 à 100 capteurs. « Notre idée a été de modéliser le comportement de chaque capteur, de modéliser le comportement nominal d’un capteur de température. Ce qui va être intéressant, c’est lorsque le comportement du capteur réel commence à diverger de ce comportement nominal, ce que nous appelons les signaux faibles qui sont porteurs d’informations sur une casse potentielle à venir. »
Chaque capteur est suivi avec son propre modèle et tous les signaux faibles sont agrégés pour calculer un niveau de risque global compréhensible par un opérateur au moyen d’un modèle Random Forrest.
Pour cette seule application de maintenance prédictive des pompes ESP, ce sont ainsi environ 150 modèles de Machine Learning qui doivent être exécutés dans l'environnement de production pour chaque pompe suivie. « Opérer et enchainer toutes les opérations de chacun de ces modèles constitue la complexité de ce workflow » explique Sophânara De Lopez. « Il faut notamment être sûrs que ce que développe un Data Scientist sur son laptop, va pouvoir tourner dans l’environnement de production. Pour garantir cela, la conteneurisation de l’architecture est une solution qui permet d’adresser les problématiques de réplicabilité et de scalabilité entre les environnements de développement et de production. »
Une architecture IA portée par le Cloud Microsoft Azure
L’architecture cible est hébergée dans le Cloud Microsoft Azure avec un datalake dans le cloud. Un gros travail d'architecture a été mené afin de découpler le volet Data Engineering / Data Preparation de la partie traitements qui s'appuie sur des conteneurs Docker, orchestrés par Kubernetes. Total a fait le choix de déployer Data Driver d’Octo Technology, une plateforme de Data Science qui inclut notamment une brique clé dans l'infrastructure de production IA de Total, Airflow.
L'architecture IA de Total est portée par le "Total Azure Cloud" et s'appuie sur la plateforme IA assemblée
par Octo Technologys, une infrastructure baptisée Data Driver.
« Ce moteur de scheduling a notamment été adopté par Google afin d’orchestrer toutes leurs tâches Data Science » explique le Data Scientist. « C’est un outil qui nous permet d’orchestrer nos tâches et workflow de manière industrialisée avec l’aspect très important d’allocation des ressources CPU/GPU de manière dynamique, en fonction des besoins. »
Autre problème résolu par ce logiciel, la reprise sur erreur. Certains workflows d'IA de Total peuvent tourner pendant des heures, voire plus d’une dizaine d’heures pour certains. Il est donc particulièrement important de pouvoir reprendre un workflow au point où celui-ci s'est interrompu. Tous les résultats intermédiaires sont sauvegardés à des fins de troubleshooting dans des fichiers de format Arrow/Parquet.
L'autre point-clé de cette architecture de production, c'est le recours généralisé aux conteneurs Docker afin d’isoler les ressources. Sophânara De Lopez souligne : « Chaque ESP dispose de son propre conteneur, de son propre scheduler Airflow et ses propres sources au niveau serveur de dashboarding. En outre, chaque conteneur intègre ses propres packages. Cela permet de résoudre tous les problèmes de dépendances entre packages auxquels le Data Scientist fait fréquemment face lorsqu’il met plusieurs workflows en production. En outre, cette approche conteneur permet de versionner simplement l’infrastructure IT et le workflow Data Science. »
Le workflow d’entrainement des modèles tourne de manière hebdomadaire ou mensuelle tandis que la partie prédictive est lancée de manière quotidienne ou même toutes les 15 minutes dans certains cas.
Faire converger les KPI Data Science avec les KPI métier
Si Total a peaufiné son infrastructure d'exploitation IA, reste désormais à l'énergéticien de générer un retour sur investissement sur ses algorithmes. En effet, ces pompes ESP fonctionnent parfois à une profondeur de 2000 à 2500 m sous les océans et effectuer un remplacement est une opération extrêmement coûteuse. Car il faut mobiliser une équipe et amener sur site un navire hautement spécialisé, capable d'aller chercher la pompe dans le puits et la remplacer par une pompe neuve qu'il faut parfois faire venir de l'autre bout du monde. L'opération coute des millions d'euros et peut demander un délai de plusieurs mois. « La convergence des KPI Data Science et KPI Métier est un aspect important » estime Sophânara De Lopez. « Détecter une panne une semaine seulement avant qu’elle survienne n’a que peu d’intérêt si la planification des opérations de remplacement demande 3 à 4 mois. Nous travaillons avec les métiers pour mettre en place des KPI opérationnelles, pour que les opérateurs puissent agir. »
Autre élément à négocier avec les métiers, la précision demandée à l'algorithme. Basé sur l'algorithme Random-Forest, celui-ci n'est pas à l'abri de générer un faux positif, c'est à dire signaler une panne potentielle sur une pompe qui fonctionne toujours et qui pourrait très bien fonctionner encore correctement jusqu'à sa fin de vie normale.
Sachant que son remplacement est extrêmement couteux et entraine une interruption de la production du puits, faut-il prend le risque d'arrêter la production ? A cette question, Arnaud de Almeida répond : « La question c’est quelle est la précision acceptable par le métier ? Est-ce 50 %, 60 %, 80 % ? Nous n’arriverons jamais à 90 %, mais c’est à l’intelligence humaine d’entrer en jeu : je sais que la pompe a tel pourcentage de risque de céder, je connais sa durée de vie et les contraintes opérationnelles de l'opération de remplacement. Je le fais ou pas ? On remplacera probablement des équipements alors qu’il s’agissait de faux positifs. Ce taux de faux positif doit entrer dans le calcul de ROI du projet. »
L'heure des PoC IA s'achève enfin et avec la solution Data Drive portée par Azure, Total s'est doté d'une plateforme capable de porter des centaines de modèles en production. La balle est désormais dans le camp des métiers et des Data Scientists pour créer les applications qui génèreront le plus de valeur ajoutée pour l'industriel.


 Arnaud de Almeida, service
Arnaud de Almeida, service
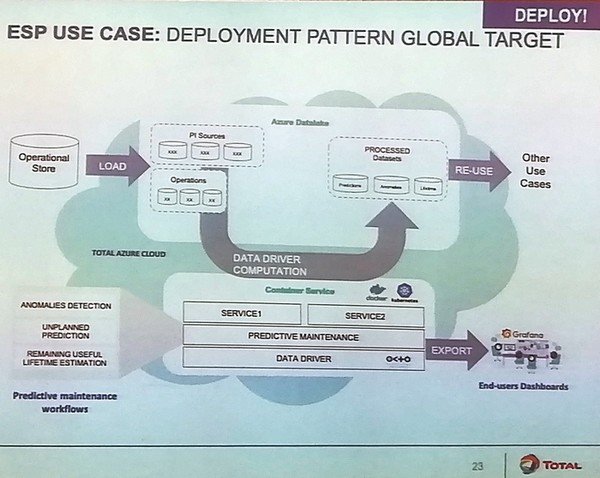 L'architecture IA de Total est portée par le "Total Azure Cloud" et s'appuie sur la plateforme IA assemblée
L'architecture IA de Total est portée par le "Total Azure Cloud" et s'appuie sur la plateforme IA assemblée
