Le ministère des Armées accélère sa stratégie Big Data
Fin 2015, le ministère des Armées met en place un Labo BI & Big Data. Sa mission ? Transformer et numériser les métiers d’aide à la décision par l’apport de méthode et de technologies innovantes. Les premiers résultats sont probants mais les besoins sont nombreux dans le Ministère. Le projet est mis en œuvre sur Elastic Stack.
Il y a quatre ans, face au constat que les métiers d’aide à la décision peinaient à s’orienter vers des outils innovants, le ministère des Armées crée un tiers lieu pour tester, expérimenter et analyser leurs données, dénommé Labo BI & Big Data.
Cette structure légère composée de 4 cadres, de chercheurs et d’universitaires fait partie de la mission d’aide au pilotage (MAP) qui est incluse dans le périmètre du Secrétariat Général de l’Administration du Ministère. Le contrôleur général des armées David, chef de la mission d’aide au pilotage, explique cette initiative : « Notre espace d’opération naturel, ce sont les données de nature administrative, notre mission est d’aider la Ministre à piloter son Ministère. »
A ce titre, son équipe construit les tableaux de bord ministériels mensuels et trimestriels qui donnent à la Ministre une visibilité sur l’ensemble de son Ministère. Au-delà de ce volet reporting, la MAP aide les contrôleurs de gestion, les statisticiens, les contrôleurs internes, les auditeurs à mieux exercer leurs fonctions.
« Nous sommes les référents pour cette famille professionnelle et les aidons dans leur quotidien. C’est la raison d’être du Labo de les aiguiller vers les outils d’analyse des données massives, de visualisation, de construction de tableaux de bord et de Data Science. »
Un laboratoire d’innovation frugale pour internaliser la connaissance
Valérie Plier, manager du Labo BI et Big Data, explique la vocation initiale d’une structure montée avec des moyens particulièrement limités : « Nous voulions donner l’impulsion aux métiers de l’aide à la décision, leur faire oublier l’utilisation intensive des tableurs pour se tourner vers des outils plus agiles pour analyser les données. Nous sommes passés d’un mode “garage” à la mise en place d’un petit Labo, un tiers lieu où chacun pouvait venir tester les outils avec leurs propres données. Comme nous n’avions pas de budget spécifique et prouver que cela était réalisable à moindre frais, nous avons mis la main sur des serveurs et du mobilier qui n’étaient plus exploités et utilisé des solutions Open Source dans des versions communautaires. »
Toujours dans cette logique de frugalité, Guillaume Vimont, en charge de toute la partie Big Data et des Data Sciences a passé ses deux années de thèse dans le Labo BI en tant que simple stagiaire avant de devenir contractuel. « Nous souhaitons conserver cette approche frugale, sans intervention de cabinets de conseil afin d’internaliser les technologies et compétences mais aussi faire face à des délais très courts que l’on ne peut tenir avec des industriels. »
Le Data Scientist a commencé ses expérimentations par la réalisation d’un premier prototype, un PoC Twitter qui avait pour objectif de démocratiser et sensibiliser les personnels à l’exploitation de données massives. « Ce PoC avait pour but de pouvoir montrer un produit à l’ensemble des métiers du Ministère, leur montrer ce qu’était capable de réaliser le Labo sur ces sujets » explique Guillaume Vimont.
« Nous souhaitions collecter des besoins similaires autour de la donnée et transposer les technologies et approche que nous avions mis en œuvre pour ce démonstrateur. » Ce PoC avait aussi pour but de monter en compétence sur une plateforme Big Data qui allait devenir un des composants de l’architecture technique de la plateforme Big Data et Data Science du Labo.
Toujours dans cette logique de frugalité, l’expert a évalué et testé diverses solutions Open Source dont SolR, Apache Zeppelin, Hadoop DFS, Hive, Kafka, Nifi, Flume, etc. « L’idée du labo était à l’origine de mettre à disposition des métiers des outils agiles, des outils qui allaient permettre aux métiers de créer eux-mêmes leurs indicateurs et être autonomes dans leurs analyses et l’exploration de leurs données sur des technologies innovantes et performantes. Nous avons donc itéré sur un certain nombre de solutions, sachant que l’autre contrainte du projet était d’être capables de faire du Big Data, de nous appuyer sur une architecture distribuée pour décomplexifier les requêtes d’analyse, et rapprocher le Big Data l’agilité. En 2016/2017, il y avait peu de solutions qui répondaient véritablement à ces deux besoins, et au fil des expérimentations, nous avons testé le projet Open Source ELK (Elasticsearch, Logstash et Kibana) de la société Elastic sur lequel nous avons fait une preuve de faisabilité. Autre avantage, nous souhaitions aller beaucoup plus loin en termes de Data Sciences que ce premier PoC Twitter. L’architecture choisie (qui inclut ELK) ne nous enfermait pas dans une technologie unique et nous permettait d’aller bien au-delà des simples agrégations et faire de l’enrichissement de données. »
L’architecture globale de la plateforme Data360° met principalement en œuvre Logstash et ElasticSearch. - Ministère des armées
Les solutions Open Source ont été clairement priorisées dans ce choix mais pour s’assurer de la sécurité des données et de l’ensemble du réseau ministériel, la solution devait s’inscrire dans le cadre de cohérence technique du Ministère qui définit quelles solutions et technologies peuvent être déployées sur les serveurs du Ministère.
D’autre part, des tests ont été menés afin de vérifier que la solution sélectionnée répondait aux contraintes de sécurité fixées par l’ANSSI. Le contrôleur général ajoute : « Outre ces aspects cybersécurité et cadre de cohérence technique, ce qui était important dans ce choix d’ELK, c’est la maîtrise fonctionnelle de l’accès aux données que cette suite logicielle intègre. Les métiers peuvent définir de manière extrêmement fine le “droit d’en connaître” de chaque donnée. C’est une garantie pour nos métiers de la bonne utilisation des données qu’ils devaient mettre à la disposition de leurs communautés d’utilisateurs, qu’il s’agisse des RH, de la finance, des achats et du suivi et de l’optimisation des consommations d’énergie et de leur contractualisation. De même le croisement entre données métier de différents domaines est parfaitement maîtrisé grâce à cette approche. Au-delà de la cybersécurité elle-même, cette maîtrise fonctionnelle des accès aux données fut un point essentiel dans notre choix. »
Un cluster Elastic par métier plutôt qu’un Data Lake unique
Alors qu’en règle générale, qui dit Big Data, dit énorme Data Lake où l’on déverse toutes les sources de données, la démarche de Guillaume Vimont fut de bien d’isoler les données de chaque métier. « Nous avions mis en place un projet comparable au sein de la MAP il y a quelques années afin de produire le tableau de bord de la Ministre. Cette expérience nous avait appris que ce n’était pas la meilleure option car les métiers ont besoin d’avoir un espace qui leur est propre afin de pouvoir gérer et sécuriser leurs données. »
Lors de la mise en place de la plateforme Big data dénommée Data360, l’expert a veillé à mettre en place un cluster distinct par domaine, chaque cluster est géré par le métier qui est celui qui dispose de la connaissance qui lui permet de gérer finement les droits d’accès, les “droits d’en connaître” de chaque utilisateur.
« Nous disposions d’une grande richesse de données. »
Guillaume VimontEn charge de toute la partie Big Data et des Data Sciences, Ministère des armées
DataFIN360 fut le premier cluster à avoir été mis en place. Celui-ci est dédié à la finance et exploite les flux de données issus de Chorus, l’ERP interministériel. Actuellement ce sont plus d’un milliard d’événements comptables qui sont stockés dans le cluster ELK où convergent toutes les données financières du Ministère jusqu’à la maille la plus fine, c’est-à-dire la facture, mais aussi des marchés, toutes les commandes d’achat, la programmation budgétaire, et très prochainement tous les matériels, qu’il s’agisse des véhicules, des pièces détachées, des munitions, etc.
« Nous disposions d’une grande richesse de données » explique Guillaume Vimont. « La première phase fut de faire parler cette donnée, la mettre à disposition des métiers. Cette phase est franchie pour ce cluster et nous sommes aujourd’hui sur une phase Data Science où nous constituons des modèles avec les métiers pour répondre à leurs problématiques. Détections d’anomalie, prédiction des dépenses futures pour réallouer des budgets, ce sont des modèles sur lesquels nous travaillons aujourd’hui. La détection d’anomalie a obtenu de bons résultats et c’est un modèle que nous allons pouvoir généraliser à l’ensemble du Ministère. »
DataFIN360 a bénéficié de la qualité des données de Chorus
Pour DataFIN360, les données issues de Chorus n’ont pas nécessité un gros travail de nettoyage. De plus, cette source a permis de disposer de 10 années d’historique des données dès la mise en place du cluster. Une richesse d’information qui permet de faire face très rapidement à des demandes imprévues.
Ainsi, lors d’une réunion avec la secrétaire générale du ministère des Finances à qui l’expert présentait les travaux du Labo, une question fut posée quant aux dépenses du ministère des Armées liées à l’amiante, un résultat complexe à obtenir car cette information est noyée dans les codifications et les champs texte des factures. Néanmoins, DataFIN360 a pu répondre immédiatement à cette requête grâce à une recherche sur le mot-clé « amiante ». Le tableau de bord de dépenses offrait alors de multiples axes d’agrégations alors qu’auparavant plusieurs mois de travail auraient été nécessaires pour collecter cette donnée, l’agréger et présenter un résultat au Ministre.
« Le retour sur investissement est évident en facilitant la vie des agents et en obtenant un gain de temps spectaculaire dans l’accès à l’information. »
Guillaume VimontMinistère des armées
Autre exemple, celui de la réalisation du tableau de bord du suivi des dépenses SIC (Systèmes d’Information et Communication) du Ministère. Cette tâche demandait 2 semaines de travail chaque mois à la personne chargée de délivrer la restitution. Avec DataFIN360, il lui suffit d’une à deux heures de travail pour délivrer les bons chiffres. « Le retour sur investissement est évident en facilitant la vie des agents et en obtenant un gain de temps spectaculaire dans l’accès à l’information. » ajoute Guillaume Vimont.
Le contrôleur général David modère toutefois l’enthousiasme des membres du Labo quant au succès de DataFIN360 : « Si l’outil a effectivement démontré toute sa puissance et sa pertinence, son taux de pénétration au sein du personnel est encore inférieur aux possibilités qu’offre la plateforme. Un an après son déploiement, il reste encore à mener une conduite de changement au sein de la direction financière, où nous observons encore une grande hétérogénéité des usages et des pans entiers du Ministère restent encore à convaincre. Malgré un ROI incontestable et une grande facilité d’utilisation, une telle rupture technologique ne s’appose pas d’elle-même sans effort d’acculturation du personnel. »
De même, DataFIN360 et son outil de restitution Kibana sont réservés aux services centraux. Les contrôleurs de gestion dans les bases militaires, dont les besoins sont plus limités, utilisent plutôt Qliksense. Ils pourraient toutefois bénéficier de DataFIN360 à l’avenir.
Après avoir communiqué sur ce premier déploiement et organisé des ateliers de formations, de multiples métiers se sont tournés vers le Labo BI afin de bénéficier à leur tour d’une telle solution. « C’est ce que j’ai appelé l’effet Big Bang : tout le monde voulait “son” DataFIN360 » se rappelle Guilllaume Vimont. « Nous avons initié un certain nombre de projets, dont DataNRJ360 qui fut l’un des tous premiers à émerger. Il s’agissait de collecter et analyser toutes les données de capteurs électriques installés dans nos bases militaires. Ces données IoT sont disponibles en grandes quantités mais sont assez pauvres. Il faut les enrichir avec d’autres données issues de notre système d’information et des données Open Data, par exemple météo, afin de leur donner du sens. »
Prix Innovation Défense 2018 - Aude Delrue, Guillaume Vimont et Mme la Ministre Darrieussecq -
Crédit : Ministère des armées
Le projet DataNRJ a décroché le prix Innovation Défense 2018, un prix qui a été remis par Mme Darrieussecq, secrétaire d’état auprès de la ministre des Armées à Aude Delrue, représentante de la mission Achat du Ministère des Armées et Guillaume Vimont.
L’économie a représenté de l’ordre de 7 millions d’euros pour la seule première année de production du cluster DataNRJ360.
L’objectif initial de DataNRJ360 était d’optimiser la consommation énergétique des installations militaires et de travailler sur le ré-allotissement des marchés en fonction de l’analyse des consommations des capteurs. Guillaume Vimont a créé des modèles d’analyse des séries temporelles et a pu aller assez loin dans la prédiction puisque Data NRJ360 peut prédire des valeurs de consommation pour chaque base de défense toutes les 10 minutes sur une année entière. Une information précieuse pour optimiser les coûts d’utilisation des réseaux d’énergie grâce à l’optimisation des contrats avec les énergéticiens, et ne pas devoir investir dans un logiciel spécialisé. L’économie a représenté de l’ordre de 7 millions d’euros pour la seule première année de production du cluster DataNRJ360.
Les nouveaux projets s’enchaînent pour le Labo BI
Après DataFIN360 et DataNRJ360, sont lancés les projets DataRH360, DataHA360 et DataGATE360, le tout regroupé sous l’étendard du projet Data360. Le Labo est aujourd’hui en capacité de mener 4 à 5 projets par an. « Nous sommes en juin et nous en sommes au 3ième déploiement de cluster depuis le début de l’année sur un mode opératoire assez proche d’un cluster à un autre : le métier exprime son besoin, nous récupérons leurs données puis travaillons sur les algorithmes qui peuvent répondre à leurs attentes. Nous déployons ensuite l’instance avec leurs données et essayons de les rendre autonomes sur l’outil. Lorsque ces projets arrivent en phase 2, c’est-à-dire le volet véritablement Data Science, il nous faut de 2 à 3 mois pour créer le modèle dans une co-construction avec les experts métiers. »
En termes d’infrastructures techniques, le Ministère assure l’hébergement de chacun de ces clusters sur des nœuds Elastic, mais la multiplication du nombre de projet a poussé le Ministère à faire évoluer son modèle de licencing et aller vers la notion de lames proposée par l’éditeur.
« Pour passer à l’échelle, Elastic propose ECE (Elastic Cloud Entreprise) qui est une solution qui permet de déployer les clusters à la volée sur notre infrastructure, l’idée étant de reproduire ce qu’il est possible de faire dans le cloud public. La tarification est fonction du nombre de lames, donc du nombre de serveurs, chaque serveur pouvant héberger un certain nombre de nœuds et plusieurs projets. » Le Ministère exploite aujourd’hui une dizaine de nœuds Elastic qui lui sont suffisants pour réaliser les projets en cours, sachant que l’infrastructure devrait atteindre une centaine de nœuds pour porter les projets en cours et ceux planifiés sur 2020.
Réaliser des analyses « cross-cluster », une piste pour l’avenir
Guillaume Vimont, en charge de la partie Big Data et des Data Sciences du Labo BI & Big Data a présenté le projet Data360° au salon VivaTechnology 2019. - Ministère des Armées
Guillaume Vimont s’intéresse désormais à la capacité qu’offre la plateforme Elastic de réaliser des requêtes portant sur plusieurs clusters. « Nous avons aujourd’hui plusieurs clusters hébergés sur nos infrastructures, et pour passer à une vraie vision 360° de l’activité, il faut mettre en place le cross-cluster. Nous allons mettre en place des ponts entre clusters afin d’offrir à certains utilisateurs la possibilité de réaliser des analyses croisées, placer dans un même tableau de bord des données issues de clusters différents. Nous pourrons aller beaucoup plus loin dans nos analyses en croisant données finance et énergie ou encore RH et finance. »
« Notre problématique aujourd’hui est d’assurer la montée en compétence de nos utilisateurs. »
Valérie PlierManager du Labo BI et Big Data, Ministère des armées
Si la plateforme technique monte en puissance, Le Labo BI doit aussi s’occuper de l’adoption de ces technologies de rupture auprès des utilisateurs. « Notre problématique aujourd’hui est d’assurer la montée en compétence de nos utilisateurs » estime Valérie Plier. « Nous allons expérimenter un cycle de formation en présentiel et surtout des formations en ligne à partir du mois d’octobre. Les nouveaux recrutés sont très sensibles aux formations en ligne et nous sommes sensibles à ce besoin en compléments aux formations en présentiel qui doivent les acculturer. »
Mais outre la formation aux outils, c’est bien une révolution des usages IT qui se diffuse au sein du Ministère, avec un Labo qui fonctionne sur des méthodes agiles depuis 2015 et qui se pose comme une startup interne, une startup qui doit désormais générer des centres de compétences disséminés au plus près des métiers comme le souligne le contrôleur général David.
Il explique : « Nous devons nous placer en capacité de diffuser ces connaissances au sein des métiers sur les ressources internes, en faisant monter en compétence nos développeurs et en répliquant ces initiatives dans 10 à 20 pôles dans le Ministère. Le cross-cluster est un autre élément sur lequel nous percevons un gros potentiel mais sur lequel nous n’avons pas de réalisations et pour l’instant, nous sommes un peu dans l’inconnu sur ce plan. Enfin, le troisième thème qui nous pousse à faire ces centres de compétences, c’est libérer des ressources internes du labo BI afin de pouvoir continuer à monter en compétence sur des algorithmes évolués. Nous devons poursuivre sur les cas d’usage pour aller vers l’IA pour trouver des informations cachées dans les données et qui échappent encore aux analyses humaines. » Ce sont les trois priorités fixées par le contrôleur général au Labo BI pour les 6 à 12 prochains mois.

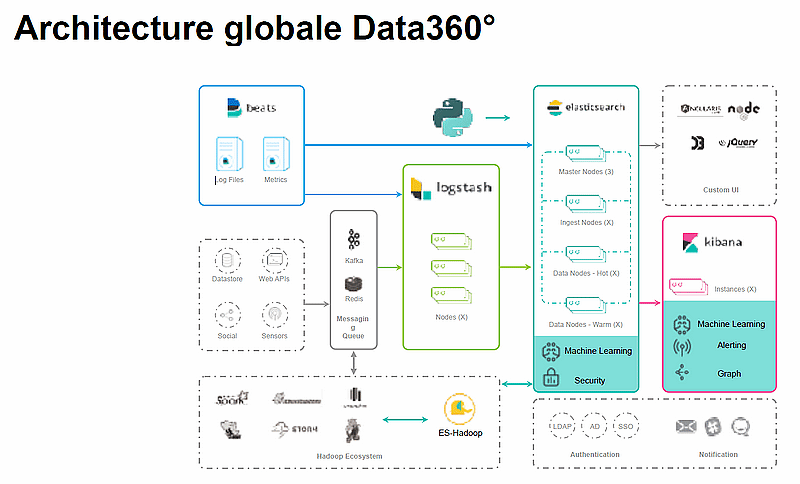 L’architecture globale de la plateforme Data360° met principalement en œuvre Logstash et ElasticSearch. - Ministère des armées
L’architecture globale de la plateforme Data360° met principalement en œuvre Logstash et ElasticSearch. - Ministère des armées

 Guillaume Vimont, en charge de la partie Big Data et des Data Sciences du Labo BI & Big Data a présenté le projet Data360° au salon VivaTechnology 2019. - Ministère des Armées
Guillaume Vimont, en charge de la partie Big Data et des Data Sciences du Labo BI & Big Data a présenté le projet Data360° au salon VivaTechnology 2019. - Ministère des Armées






