Hyperconvergence 2.0 : que vaut la « norme » d’Axellio ?
L’ancienne division SAN/NAS de Seagate milite pour équiper les nœuds serveurs de 72 disques en NVMe, afin de résoudre les problèmes de flexibilité. Mais un travail sur le logiciel reste à faire.

Axellio, spécialiste des designs serveurs très intégrés, autoproclame depuis le début l’année 2019 un standard Hyperconverged Infrastructure 2.0 (HCI 2.0). Les machines qu’il espère voir vendues sous cette dénomination devraient être des clusters où la capacité de stockage de chaque nœud aura sa propre extensibilité.
Le constructeur évoque un nombre de disques qui pourrait aller de 12 à 72 par serveur, de préférence en NVMe. L’enjeu serait de rendre les infrastructures hyperconvergées plus flexibles pour mélanger dans un même cluster l’exécution d’applications très différentes et, surtout se servir enfin de ce type de machines pour lancer des bases de données d’envergure.
« Le problème de la génération actuelle d’infrastructures hyperconvergées est que les fournisseurs proposent des nœuds de calcul avec une capacité de stockage maximale pour éviter de les mettre matériellement à jour », explique, dans un billet de blog, George Crump, analyste chez Storage Switzerland et manifestement convaincu par l’intérêt de HCI 2.0.
« Cela fait qu’une entreprise se retrouve rapidement soit avec trop de capacité disque parce qu’elle ajoute des nœuds pour répondre à son besoin de puissance de calcul, soit avec trop de processeurs parce qu’elle ajoute des nœuds pour résoudre un problème de capacité. Et au final, elle se retrouve avec une configuration qui coûte plus cher que le cluster – non hyperconvergé – dont elle aurait eu besoin », ajoute-t-il.
Selon lui, cette situation aurait conduit les entreprises à finalement restreindre l’usage des infrastructures hyperconvergées soit à l’exécution de postes de travail virtuels, soit à celle d’applications qui n’ont pas besoin de performances : « ajouter des disques Flash aux nœuds hyperconvergés pour les rendre plus rapides n’a pas empêché les entreprises de toujours préférer des serveurs non virtuels pour exécuter leurs applications dites de tier-1 », dit-il, en référence aux bases de données.
Et d’accuser le manque de flexibilité des configurations actuelles de restreindre les possibilités : « les utilisateurs se retrouvent la plupart du temps à dédier un cluster de nœuds hyperconvergés à un seul type de traitements, pour lequel les nœuds uniformes ont été conçus. Cela revient donc à multiplier les infrastructures hyperconvergées dans le datacenter, ce qui augmente mécaniquement la complexité de l’administration système. »
Autoriser jusqu’à 72 disques NVMe par nœud
Physiquement, il s’agit dans HCI 2.0 d’utiliser des nœuds avec beaucoup plus de capacité de stockage – voire du stockage bien plus performant – par processeur. Les usuels nœuds 1U avec 12 disques SATA seraient remplacés par des nœuds de taille plus importante avec 72 disques, de préférence NVMe. On pourrait exécuter plus d’une centaine de machines virtuelles par nœud, là où la première génération n’exécute généralement qu’une trentaine de VMs par nœud.
« D’une certaine manière, alors que la première génération favorisait le scale-out [l’extensibilité à volonté par ajout de nœuds uniformes, N.D.R.], HCI 2.0 a plutôt vocation à faire du scale-in, c’est-à-dire à augmenter la performance au sein d’un nœud en particulier », indique George Crump dans un autre billet de blog.
Ainsi, si le modèle économique de la première génération tenait à l’assemblage au fil du temps de nœuds complets individuellement peu chers, celui de HCI 2.0 relève plutôt de l’enrichissement des nœuds en disques au fur et à mesure que la charge applicative augmente. Chaque nœud coûterait donc plus cher en HCI 2.0, mais il n’en faudrait que trois pour exécuter le nombre de machines virtuelles qui fonctionnent actuellement sur dix nœuds.
Sur le plan logiciel, les machines HCI 2.0 seraient équipées d’une nouvelle génération d’hyperviseurs et de SDS qui garantissent que le stockage d’une VM se trouve toujours sur les disques du nœud qui exécute cette VM. Cela permettrait de garantir des performances bien meilleures aux applications que dans les infrastructures hyperconvergées classiques, où les VMs communiquent avec leurs disques via le goulet d’étranglement du réseau, lequel doit d’ailleurs généralement être gonflé.
George Crump en arrive à la conclusion qu’une infrastructure hyperconvergée de seconde génération coûterait donc moins cher, puisque déployer moins de nœuds signifierait aussi acheter moins de licences logicielles et investir au minimum dans la connectique réseau.
L’argument du réseau est néanmoins à pondérer. Que ce soit au titre de redondance ou lors des migrations, l’hyperviseur en HCI 2.0 devrait idéalement répliquer une VM sur un autre nœud avec toutes ses données, ce qui alourdirait singulièrement la charge du réseau lors du transfert.
Une promesse qui n’a toujours pas été tenue
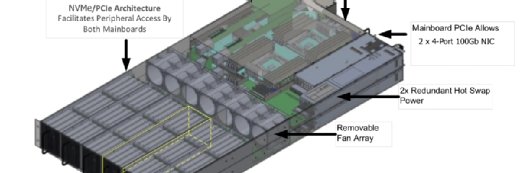
Problème, Axellio n’a toujours pas concrétisé lui-même sa norme HCI 2.0. Certes, le fabricant parvient bien à installer 72 disques NVMe dans l’appliance 2U FX-1000 qu’il commercialise depuis le premier semestre 2019. Sauf qu’il s’agit ici de deux nœuds bi-sockets superposés – donc deux jeux de licences bi-processeurs – qui accèdent chacun à trois tiroirs internes « FlashPac » de 12 disques, ces derniers étant insérés en enfilade sur des rallonges de bus PCIe.
Cette appliance FX-1000 ne fonctionne pas encore avec un système d’hyperconvergence inédit, mais avec le système Windows Server Software-Defined (WSSD) de Microsoft. Celui-ci comprend l’hyperviseur Hyper-V et le SDS Storage Spaces Direct, tous deux s’exécutant sur chaque nœud. Storage Spaces Direct, comme tous les autres SDS, ne fixe pas encore l’emplacement de certains volumes virtuels sur le même nœud que la VM qui y accède. C’est-à-dire que la promesse HCI 2.0 d’Axellio n’est toujours pas totalement concrétisée.
Le seul mérite technique de l’appliance d’Axellio est que les deux nœuds qu’elle intègre ne sont pas interconnectés par Ethernet mais par un bus propriétaire, FabricXpress, dont la bande passante est censée réduire le risque de goulet d’étranglement. Axellio ne précise néanmoins jamais la vitesse de cette bande passante. On sait juste que chaque nœud accède à ses 36 disques avec un débit de 60 Go/s et plus de 12 millions d’IOPS.
Surtout, les détails de ce bus FabricXpress ne sont absolument pas ouverts. Il s’agit d’une technologie qui ne peut pas, en l’état, servir de standard. La « norme » que souhaite Axellio n’est pas complète.
Pour le reste, la solution supporte l’assemblage maximum de 16 nœuds, soit 8 appliances 2U, mais l’interconnexion entre les appliances se fait exactement comme dans toutes les autres infrastructures hyperconvergées : via un réseau Ethernet. C’est-à-dire que les bases de données ne peuvent toujours pas accéder avec une vitesse suffisante à leurs disques situés à l’autre bout d’un lien 10 Gbit/s et que, pour y parvenir, il faudrait, comme partout ailleurs, dépenser une fortune dans un réseau 100 Gbit/s. En clair, les entreprises ont toujours plutôt intérêt à exécuter de telles bases sur des serveurs physiques avec un SAN Fiber Channel.
Datrium et DataCore : des alternatives plus concrètes
Axellio n’est pas le seul à s’intéresser au problème de manque de flexibilité que posent les infrastructures hyperconvergées actuelles. Datrium, avec ses machines OCI (Open Converged Infrastructure) et son « hyperdriver » DVX, ainsi que DataCore, avec ses appliances HCI-Flex (HCI signifiant ici « Hybrid Converged Infrastructure ») et le système HvSAN, revendiquent aussi plancher sur une norme HCI 2.0. Ils proposent en l’occurrence tous deux de réunir en un seul pool de stockage les disques présents dans les nœuds et ceux situés dans des baies de disques externes, lesquelles sont indépendamment extensibles.
Au contraire d’Axellio, Datrium et DataCore ne font pas l’impasse sur la connectique réseau en prétendant qu’il suffit de mettre plus de disques dans les nœuds. Ils proposent en revanche de mettre en cache les données les plus chaudes des VMs dans les nœuds qui les exécutent, afin de minimiser les entrées-sorties. Ils simulent ainsi des IOPS très élevés, malgré des données potentiellement situées à l’autre bout d’un lien Ethernet.
Reste à savoir laquelle des deux approches sera la plus efficace. Le fait est que les solutions de Datrium et DataCore existent, alors que l’offre FabricXpress d’Axellio n’implémente pas encore l’hébergement d’une VM et de son stockage dans le même nœud. A date, aucun fournisseur n’a annoncé qu’il suivra la voie indiquée par Axellio.
Axellio est le nouveau nom de X-IO Technologies, l’ex-division baies de stockage de Seagate, devenue autonome en 2008, et qui s’est rebaptisée après avoir vendu son activité SAN à Violin, il y a un an.





