Pernod Ricard se distille un savant cocktail de Big Data et d’analytique
Utilisatrices des solutions Qlik de longue date, les filiales françaises Pernod Ricard exploitent l’outil analytique connecté à la plateforme Big Data du groupe. Un mariage réussi dans lequel la brique Snowflake monte en puissance.
Lorsqu’il prend la présidence du groupe Pernod Ricard en 2012, Alexandre Ricard annonce son ambition de faire du digital un fer de lance pour le groupe, notamment pour accroître la connaissance client.
Les deux filiales françaises du groupe ont commencé à utiliser QlikView dès 2008, un choix qui a perduré lors de la fusion des systèmes décisionnels en 2015 avec Qlik Sense.
L’outil analytique et de DataViz d’origine suédoise s’est initialement imposé comme le principal logiciel de restitution des données pour des besoins classiques de pilotage de la performance. Le tout avec des KPI, des tableaux de bord et des applications analytiques afin de permettre aux experts métiers d’aller plus loin dans leurs analyses des performances et du reporting détaillé des transactions.
Depuis, cette stratégie a connu une accélération avec la mise en production ces six derniers mois des premiers cas d’usage mettant en œuvre des techniques de Data Science. D’outil analytique, Qlik Sense est en train de devenir chez Pernod Ricard un outil d’aide à la décision des utilisateurs métiers.
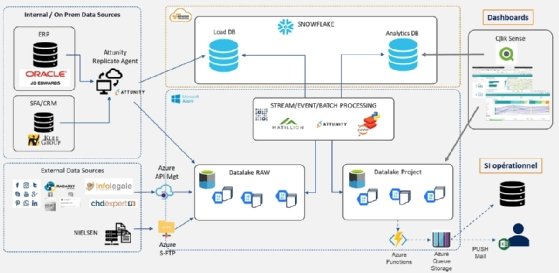
Un duo Azure Data Lake/Snowflake pour stocker les données
Romain Gauthier, BI & Data Solutions Manager chez Ricard SA et Pernod SA, est arrivé à la tête de l’équipe Data & Analytics en 2015 alors que les entités Ricard et Pernod France menaient un vaste projet de rapprochement des fonctions backoffice et de consolidation des ressources informatiques.
L’objectif était alors de constituer un seul système d’information pour les filiales françaises du groupe. « C’est dans ce cadre que j’ai enclenché une démarche de transformation sur tout l’écosystème de l’analyse de la donnée et du reporting. Il s’agissait d’être en capacité de répondre aux besoins d’évolution des métiers, notamment pouvoir accéder à des données plus variées, dont des données externes », explique-t-il au MagIT. « Enfin, nous devions obtenir plus de transversalité dans les informations, car notre SI décisionnel était trop siloté. »
De fait, l’infrastructure Big Data de Pernod Ricard a beaucoup évolué ces trois dernières années. Une première étude, menée en commun avec les équipes IT du groupe, amène Pernod Ricard à créer un premier Data Lake AWS avant de finalement migrer sur le cloud public Microsoft Azure.
« Nous avons aujourd’hui un Data Lake sur Azure sur lequel nous utilisons divers services managés, comme Databricks pour réaliser des traitements sur les données et intégrer des briques de Machine Learning et Deep Learning. Nous utilisons aussi certains services Azure Machine Learning de manière expérimentale. Ces usages pourraient être avalisés très rapidement. »
Une fois la donnée retravaillée, Pernod Ricard France a fait le choix du service DaaS (Data as a Service) de Snowflake. « Nous privilégions aujourd’hui Snowflake pour les données structurées amenées à être interrogées en SQL. Ce choix nous permet de conserver des capacités d’échanges avec notre écosystème de solutions qui exploitent SQL. »
L’architecture Data du groupe Pernod Ricard voit le rôle de la solution DaaS Snowflake couplée à Microsoft Azure monter en puissance au détriment des infrastructures on-premise Oracle Exadata qui se voient dédiées au transactionnel.
C’est le cas de Qlik qui sollicite Snowflake pour récupérer les données requêtées par l’utilisateur et dans le Data Lake lorsque celles-ci doivent être complétées. « La force de Qlik est d’être une solution relativement agnostique en termes de sources de données. Nous avons utilisé dans un premier temps un connecteur ODBC [Open DataBase Connectivity] pour accéder à Snowflake, puis le partenariat Qlik/Snowflake nous a permis de disposer d’un connecteur natif – aujourd’hui bien plus performant ».
Au niveau du temps de chargement des données, « la solution – qui est pourtant dans le cloud public – peut se montrer plus performante que pour des données stockées dans le Data Warehouse interne, des appliances Exadata d’Oracle », constate Romain Gauthier.
Pernod Ricard a ainsi décidé de basculer peu à peu ses données décisionnelles vers Snowflake afin de libérer de l’espace sur ses appliances Exadata, qui arrivaient à saturation. À terme, ces dernières vont être entièrement dédiées aux bases de données transactionnelles.
Une première application Big Data qui trouve 10 000 prospects
Sur l’ensemble des personnes susceptibles de consommer, d’analyser ou d’enrichir des données chez Pernod Ricard France (soit entre 350 à 400), la quasi-totalité dispose de QlikSense. Outre le marketing et les ventes, les services financiers sont en train de migrer de SAP BI 4 vers Qlik, dans le cadre de la rénovation du socle EPM (Enterprise Performance Management) du groupe.
La première application Qlik développée avec les données du Data Lake est dédiée à la connaissance client. « Nous avons souhaité enrichir l’information qui était mise à la disposition des métiers. Ces clients sont principalement les enseignes de la grande distribution et les CHR (Café/Hôtel/Restaurant) », contextualise le responsable. « Notre premier challenge était d’en avoir une connaissance approfondie en enrichissant notre information de sources de données externes sur les clients Pernod, les clients Ricard, et les clients communs. »
Outre les données recueillies par les commerciaux sur le terrain, le système intègre des données d’autres sources : Open Data, INSEE, Infolegale (information légale des entreprises), CHD Expert (spécialiste dans le secteur CHR), ou encore Semsoft (un agrégateur d’informations sur les réseaux sociaux, capable de ramener toutes les informations disponibles publiquement sur un établissement à partir d’un Google ID).
« [Semsoft] nous permet de trouver tous les établissements similaires à proximité d’un établissement client. Avec ces sources, nous avons pu enrichir la base de nos clients connus, mais aussi identifier des clients qui n’existaient pas dans nos bases… et donc des prospects potentiels », se félicite Romain Gauthier.
La première version de cette base de données, générée au bout de 2 mois et demi de projet, contenait 70 000 établissements qualifiés et enrichis, dont plus de 10 000 prospects à potentiels intéressants.
L’algorithme de classification mis en œuvre par Pernod Ricard est capable de déterminer si un établissement est un restaurant, un bar, un caviste ou une discothèque. Un scoring permet aux commerciaux d’avoir une estimation du niveau d’image de l’établissement. Ceux-ci savent s’il s’agit d’un établissement premium à fort potentiel, d’un compte moyen ou s’il est plus modeste.
« Notre application Qlik permet aux responsables de visualiser l’ensemble de ces informations, notamment au moyen de cartes et d’affecter les comptes aux commerciaux via le CRM (Salesforce). »
Une autre application a été développée pour le volet grande distribution. Elle définit le meilleur assortiment à proposer à chaque établissement pour cibler les bons consommateurs. L’application s’appuie sur d’autres sources de données internes et externes.
Des réflexions pour la logistique et le rolling forecast
De nombreux autres projets qui mélangent analytique et Big Data sont à des stades de réflexion plus ou moins avancés dans le groupe.
Côté opérations, les filiales françaises de Pernod Ricard réfléchissent à des applications pour optimiser les flux logistiques internes : entre les sites de production et de stockage, et à destination des clients. Mais ce projet implique, en amont, l’analyse d’une très grosse volumétrie de données pour faire des propositions d’optimisations pertinentes.
Par ailleurs, le groupe travaille sur un modèle prévisionnel de vente pour mettre en place un rolling forecast (prévisions glissantes). Jusqu’à maintenant, les prévisions de ventes sont révisées trois fois par an. Avec cette application, elles seront réévaluées en permanence, avec des prévisions à 6 mois, 12 mois et 18 mois. Une telle prévision glissante permet de mieux anticiper les évolutions de marché.
« Nous étudierons la possibilité de reprendre ces modèles de prévision créés au niveau groupe pour les adapter au contexte français. »
Romain GauthierRicard SA et Pernod SA
« Nous étudierons la possibilité de reprendre ces modèles de prévision créés au niveau groupe pour les adapter au contexte français », explique Romain Gauthier, « nous pourrions par exemple ajouter des données locales – comme les sorties caisses de la grande distribution – et ainsi délivrer des prévisions de ventes plus précises sur la France. Cela fait partie des réflexions en cours. »
Une gestion des cycles de vie des applications à améliorer
Le responsable BI & Data juge que la création des applications – avec Qlik – a pu se faire sans problème en mode agile. « L’outil en lui-même permet de visualiser très rapidement les données, ce qui permet de bien supporter la démarche agile, pour avancer rapidement dans la construction de l’application et l’étendre avec des indicateurs de plus en plus sophistiqués », raconte-t-il au MagIT.
Mais il reste des points à améliorer. Romain Gauthier estime avoir aujourd’hui besoin d’une véritable gestion du cycle de vie des applications Qlik. Une gestion des versions qui permettrait de sécuriser les déploiements et de contrôler au plus près les versions déployées sur les postes clients.
Autre point, dans le contexte assez particulier de Pernod Ricard où les deux marques sont potentiellement concurrentes entre elles, une gestion des droits utilisateurs plus fine pourrait simplifier la tâche de son équipe.