Cegid – Talentsoft : dans les coulisses IT d’une fusion de deux SIRH
Cegid a racheté le champion du Talent Management, Talentsoft. Avec cette nouvelle gamme, l’historique de l’ERP renforce son offensive dans le SIRH. Mais cette opportunité s’accompagne d’un ensemble de chantiers IT. André Brunetière, le Monsieur R&D de Cegid dévoile les coulisses techniques de ce rapprochement.
L’éditeur d’ERP Cegid est entré dans une nouvelle ère avec l’arrivée à son capital en 2016 de fonds anglo-saxons. Mi 2021, une prise de participation minoritaire de KKR valorisait l’éditeur 5,5 milliards d’euros.
Dans ce laps de temps, l’objectif fixé par le « nouveau Cegid » était d’atteindre les 600 millions de CA à l’aube de 2022 (contre 280 millions en 2015). Avec l’ajout mathématique des revenus de Talentsoft racheté en 2021, c’était chose faite.
Mais un nouveau cycle s’annonce déjà avec un horizon tout aussi ambitieux : 1,3 milliard d’euros de CA d’ici 4 ans. Là encore, Talentsoft sera, commercialement, un bon relais de croissance dans cette stratégie de développement. Cegid pourra en effet pousser Talentsoft à ses clients actuels dans la finance et les RH (ce qu’il a d’ailleurs déjà commencé à faire en novembre, lors de son évènement 2021 à la Mutualité).
André Brunetière, directeur
des produits et de la R&D, Cegid
Mais Talentsoft représente aussi un ensemble de chantiers IT d’envergure pour Cegid : intégration des données, un Datalake RH commun entre les produits, infusion de l’IA (dans des cas d’usages pertinents) ou encore refonte des écrans pour unifier l’expérience utilisateur. Sans oublier le cloud – voire le cloud souverain.
André Brunetière, le Directeur des Produits et de la R&D de Cegid, s’est entretenu avec Applications et données sur tous ces défis technologiques, vous ouvrant au passage en grand les portes des coulisses de cette alliance majeure pour l’écosystème français des applications B2B.
« Agnostic cloud »
LeMagIT : Talentsoft a une approche extrêmement agnostique des clouds. Il repose sur Terraform pour pouvoir passer d’un cloud à un autre au cas où, par exemple, il y aurait une augmentation de prix sur telle ou telle plateforme. Talentsoft met un point d’honneur également, à ne pas utiliser de service PaaS, là aussi pour ne pas être dépendant d’une plateforme.
Cegid a une approche différente avec un double accord stratégique – avec IBM d’une part, et Azure d’autre part. Comment allez-vous faire converger ces deux approches ? Allez-vous faire évoluer la doctrine technologique de Talentsoft ?
André Brunetière : Tout d’abord, Azure est aussi important chez Talentsoft. Mais c’est vrai que ce choix d’être sur plusieurs plateformes leur a beaucoup servi. Non pas parce qu’ils sont fâchés avec Microsoft, mais parce qu’ils ont gagné des clients dans la fonction publique qui n’imaginaient pas que leurs données puissent aller dans un cloud public détenu par un acteur américain.
Cette approche agnostique leur permet de faire coexister du cloud public à la Azure et du cloud privé à la Quadria, ou à la OVH. Le pari de ne pas être dépendant et de pouvoir « se poser un peu partout » est aussi très utile à Talentsoft pour simplifier la gestion de ses versions ; et ne pas avoir à mettre à jour une instance d’un côté, puis une autre ailleurs, etc.
« La multiplicité des clouds [de Talentsoft] nous amène à réfléchir pour répondre aux exigences de secteurs réticents au cloud public. »
André BrunetièreCegid
Donc, oui, ils ont bien industrialisé cela. Et cette multiplicité des clouds ne pose aucun problème en matière de maintenance. Donc il n’y a aucune raison que Cegid revienne dessus. C’est extrêmement pertinent et ça a beaucoup de sens. Et même… cela nous amène, nous, à réfléchir pour certains domaines où nous savons qu’il pourrait y avoir de la réticence à ce que des données soient sur du cloud public.
Deuxième point : sur Cegid. Vous dites que nous avons une approche très différente. Mais en fait, ce n’est pas vrai. Même si nous avons un contrat avec Microsoft, c’est plus une optique IaaS (Infrastructure as a service) que PaaS (Platform as a service). C’est-à-dire que l’on se sert de notre partenariat avec Microsoft sur Azure, mais sans s’attacher à des technologies propriétaires Azure.
Un tel attachement ne nous semble en effet pas viable. Pas tant sur la crainte de politiques de prix qui pourraient s’envoler, mais pour avoir une certaine souplesse par rapport à la réglementation sur le cloud qui est encore en forte évolution.
Enfin, nous sommes sur IBM historiquement parce qu’on y a été avant que les clouds publics n’existent vraiment. Les nouvelles solutions, elles, sont plutôt sur Azure, mais toujours dans une logique IaaS, donc déplaçables si besoin.
LeMagIT : Sur le papier, migrer une VM ou un conteneur semble simple. Dans la réalité, beaucoup de DSI disent qu’il y a un ensemble de choses qui empêche de le faire de manière fluide. Vous confirmez ?
André Brunetière : Autant être à plusieurs endroits en même temps, c’est simple, autant faire bouger d’un endroit à un autre, c’est autre chose. Il est clair que créer une instance Azure et finalement la mettre sur Quadria ou OVH, avec les données du client, ce n’est pas si évident que cela, même s’il y a toute la technologie qu’il faut. Cela reste une opération de déplacement qui suppose quelques précautions.
Nous n’allons pas être dans une espèce de flexibilité totale où on se dit « tiens, ce matin, ces clients sont là, si on les mettait ailleurs ». En fait, pour moi, l’intérêt [de notre stratégie], c’est surtout de ne pas mettre tous nos œufs dans le même panier, quand on décide de provisionner pour installer de nouveaux clients ou lancer de nouveaux produits.
« Cegid a plus une optique IaaS que PaaS, [et] sans s’attacher à des technologies propriétaires. Un tel attachement ne nous semble pas viable. »
André BrunetièreCegid
Ce qui est possible par exemple, c’est pour un produit donné, avoir deux fournisseurs de cloud – certains clients sur le premier et d’autres sur le second. Et avec des technologies comme Terraform, de ne pas avoir une maintenance qui se complexifie lors des mises à jour produit.
André Brunetière : Terraform fonctionne bien pour des solutions construites dès le départ pour le cloud. Celles qui ont évolué pour fonctionner dans le cloud, alors qu’elles ont été construites avant le cloud, ce n’est pas forcément la même logique.
Meta4 par exemple est initialement une solution de type client-serveur qui a été transformée progressivement pour exprimer toute sa puissance en cloud.
Dans ces cas-là, nous passons par plusieurs étapes. Pour commencer, on fait du « Lift & Shift », puis on engage un programme de transformation au long cours pour utiliser les techniques de conteneurisation. Et ensuite on sépare encore plus, à l'intérieur du produit, le front-end des données et de la logique métier.
André Brunetière : Dans les chantiers en commun, il y a une problématique fonctionnelle qu’il faut qu’on adresse. Dès lors que vous dites que vous êtes « sans couture » entre d’un côté, un produit qui fait de la gestion administrative et de la paye, et de l’autre un produit qui fait de la gestion des ressources humaines, vous faites plusieurs promesses à votre client.
La première c’est qu’il n’aura pas à saisir deux fois les mêmes données. Si elles ont été créées à un endroit et qu’elles sont nécessaires à l’autre, la synchronisation c’est notre problème à nous, éditeur. C’est la première étape.
La deuxième étape, c’est que le client n’a peut-être pas besoin de la donnée dans un produit, mais il peut quand même vouloir la connaître pour l’aider dans une réflexion. Dans ce cas, le parcours pour accéder à la donnée qui se trouve dans l’autre produit ne doit pas être compliqué – il ne doit par exemple pas supposer d’aller se loguer dans l’autre produit.
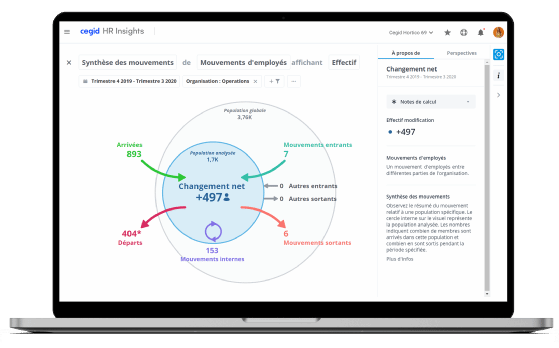
Cegid HR Insights
Pour le premier objectif, nous avons défini un chantier à court terme, avec des APIs. De cette manière, on s’assure – et ce sera le scénario principal – que quand nous vendrons la suite Talentsoft à un client paye de Cegid, il pourra utiliser directement ses données de paye sans avoir à les ressaisir. Dès la mise en route, il disposera de sa base de salariés et de toutes ses informations essentielles pour faire tourner une suite de gestion de talents. Et ensuite il y aura une synchronisation permanente entre les deux outils.
Cela crée une fluidité dans l’usage et cela évite aussi les multiples saisies qui sont source de perte de temps, et surtout, d’erreurs.
La deuxième étape – que j’ai présentée dans notre keynote avec Joël [Bentolila] [.N.D.R. : CTO et co-fondateur de Talentsoft] – doit répondre à la question : comment, quand je suis à un endroit, si j’ai besoin d’une donnée qui se trouve un autre endroit, je la fais voyager jusqu’à moi ? Et c’est là qu’arrive le data lake.
LeMagIT : Pouvez-vous nous expliciter cette différence entre les deux modes d’intégrations de données (API vs Data Lake) ?
« Le data lake [commun] ne sera pas une métabase de données. Les deux produits gardent leurs bases propres [qui vont] se synchroniser avec le data lake. »
André BrunetièreCegid
André Brunetière : La notion de lac de données se déconnecte de la notion de base de données qui fait tourner le produit.
C’est-à-dire que d’un côté, nous avons un produit avec sa base de données dont il se sert en permanence pour fonctionner. Et de l’autre, cette base va se synchroniser avec un data lake qui va, peut-être, aussi avoir des données qui viennent d’ailleurs.
Le fait que tout cela soit relié au data lake va permettre d’aller consulter et d’aspirer de la donnée à la demande. C’est beaucoup plus simple que de devoir refaire des APIs pour des cas particuliers auxquels nous n’avions pas pensé. C’est une autre approche. Dans un Data Lake, je vais chercher ce que je veux dedans et l’utiliser où je veux.
LeMagIT : Donc on va avoir deux produits – Cegid HCM et Talentsoft – avec leur propre base et par-dessus un data lake. Vous ne remplacez pas leurs bases de données par ce lac de données (ce qui est par exemple la stratégie de replateformisation d’un Adobe dans un autre domaine) ?
André Brunetière : Exactement. Le data lake ne sera pas une espèce de métabase de données qui marche pour tout. Les deux produits gardent leurs bases propres, avec des connecteurs permanents (des API pour que les deux produits partagent l’information). Et on ajoute un data lake commun qui permettra d’aller chercher les informations dont je pourrais avoir besoin – des données qui ne sont pas strictement nécessaires au fonctionnement opérationnel des produits entre eux, mais qui, dans un certain nombre de cas, vont intéresser un utilisateur d’un produit ou de l’autre.
LeMagIT : Ce Data lake est prévu pour quand ? Combien de temps va prendre ce chantier d’après vous ?
André Brunetière : Nous venons juste de sortir le data lake des données financières. Nous avons plusieurs produits qui gèrent des données de comptabilité, donc nous avons mis tout cela dans un data lake commun – là aussi pour donner plus d’accès aux informations.
« Un data lake a trois niveaux : la donnée brute, la donnée homogénéisée et la donnée élaborée. Nous allons construire ces trois étapes progressivement. »
André BrunetièreCegid
Pour les données RH, on est à peu près dans un timing de deux ans. Cela peut paraître long, mais en fait, il ne s’agit pas juste d’y déverser les données. Ça, c’est la première étape qui va relativement vite. Ensuite, il faut aussi définir un référentiel commun qui va faire que, même si les données viennent de différentes sources, on les comprend toujours de la même manière.
On dit souvent qu’il y a trois niveaux dans un data lake : la donnée brute (telle qu’elle est arrivée), la donnée homogénéisée (où les choses deviennent comparables), et les données élaborées (où à partir de ces données homogénéisées, on fait des calculs, des comparatifs, etc.).
Nous allons construire ces trois étapes progressivement.
LeMagIT : Donc dans deux ans, on peut envisager un data lake RH/HCM en plus de votre data lake Finance ?
André Brunetière : Oui, dans deux ans on devrait avoir quelque chose d’abouti. Mais on aura peut-être des premières choses qui commenceront à marcher avant.
LeMagIT : Quels sont les autres chantiers communs avec Talentsoft, en plus du Data lake ?
André Brunetière : Chez Cegid, nous avons travaillé sur des outils pour les grands comptes autour du SSO. En interne, nous appelons cela les « composants communs ». Nous regardons avec Talentsoft pour voir comment ils peuvent adopter ces composants.
Le troisième chantier commun en cours concerne l’interface. Nous avons chacun une équipe UX/UI avec des personnes qui s’occupent des écrans. Comme tout va converger vers une identité Cegid, ces équipes travaillent logiquement ensemble pour construire cette nouvelle identité dans les écrans de Talentsoft.


 André Brunetière, directeur
André Brunetière, directeur